你好,我是黄佳。
经过六讲的学习,我们完整走过了 Skills 从 语法 到 架构 再到 行业标准 的全路径。今天的加餐,我们一起整体回顾一下我们所学习过的 Skills 系统的设计逻辑和知识地图 。
Skills 专题六讲全景
我把 Skills 专题六讲全景总结列表如下。

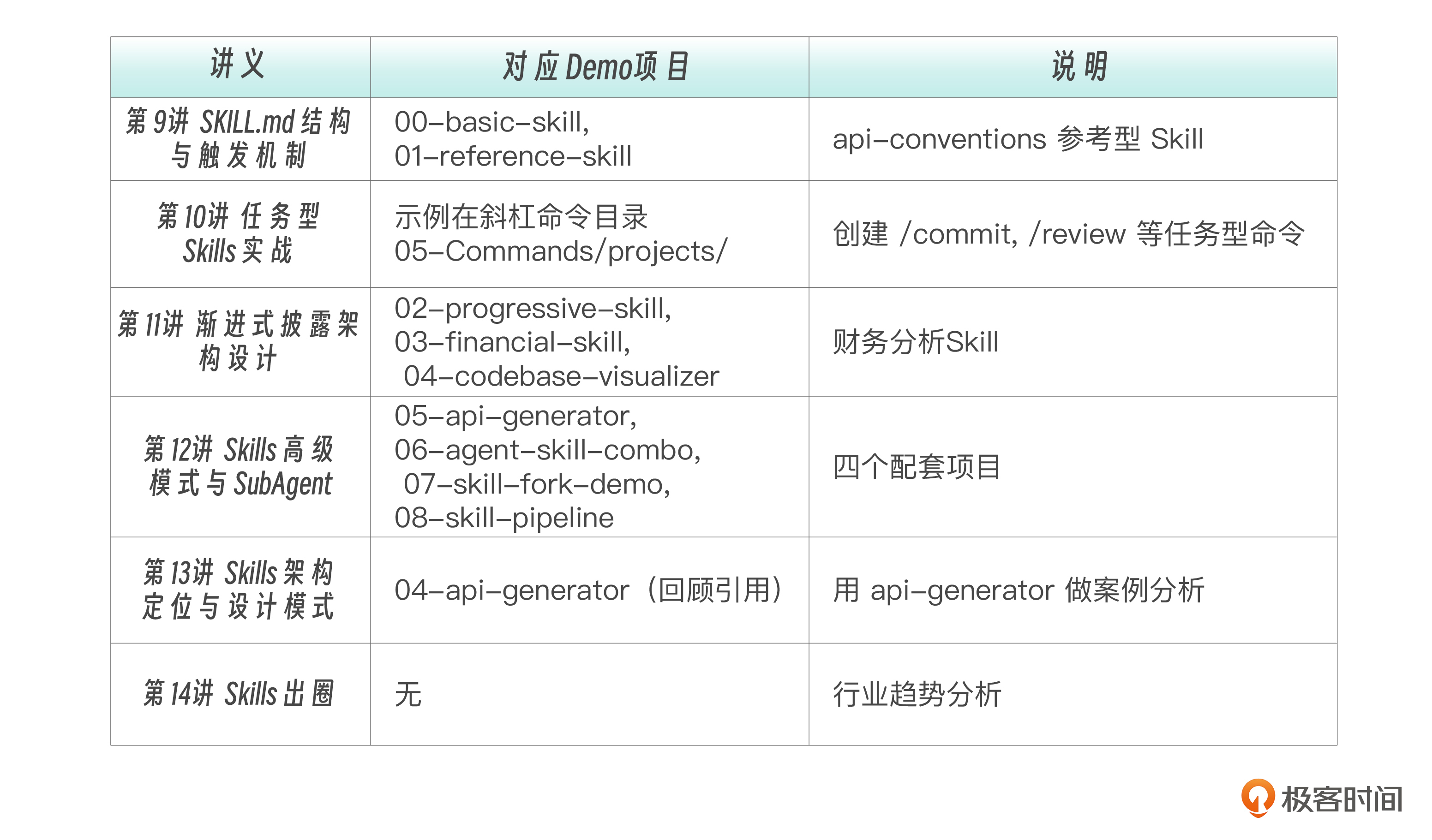
6篇讲义、Demo项目对应关系如下。
两层能力体系
和子代理专题一样,我们把六讲的内容按能力层级来划分。
第一层:知识工程(第 9-11 讲)——让 AI 在正确的时刻拥有正确的知识
第 9 讲:知识的结构与触发
↓ 知识怎么写、什么时候被加载
第 10 讲:知识的操作化
↓ 知识怎么变成可执行的标准流程
第 11 讲:知识的经济学
↓ 如何用最少的 token 传递最多的知识
这一层解决的是 知识管理问题 。你的团队有大量专业知识(编码规范、架构约定、审查标准、部署流程),怎么让 AI 在需要时精准获取,不需要时不浪费上下文?
第二层:系统集成(第 12-14 讲)——让知识驱动整个智能体系统
第 12 讲:知识 × 智能体
↓ Skill 怎么和 SubAgent 组合成领域专家
第 13 讲:知识在架构中的位置
↓ 五层架构全景定位,从 SOP 到专家系统
第 14 讲:知识的平台逃逸
↓ 声明式 + 自包含 + 知识本位 = 跨平台标准
这一层解决的是 系统设计问题 。Skills 不是孤立的知识包,它和 SubAgents、Hooks、Plugins 组成了一个完整的工程体系。知道 Skills 怎么写只是入门,知道它 放在哪里、和谁配合、为什么这样设计 才是真正的能力。
贯穿六讲的一条暗线
六讲看似讲了很多不同的概念,但如果你退后一步看,会发现一条清晰的演进路径。
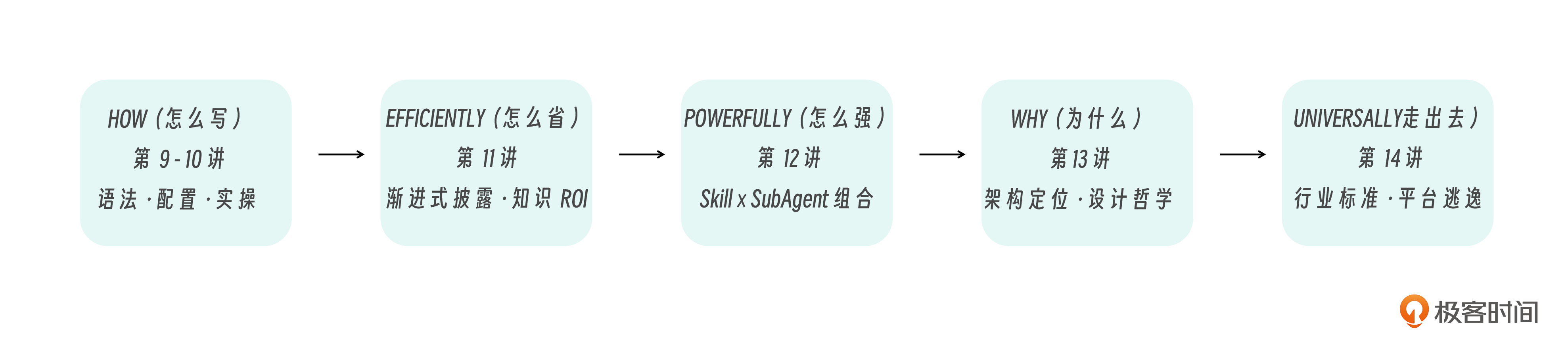
一句话概括就是 ,从“会写 SKILL.md”到“理解 Skills 为什么是 AI 工程化的关键基础设施”。
Skills 的四种设计模式
第 13 讲提出了四种设计模式:模板驱动(约束输出格式)、脚本增强(封装确定性逻辑)、分层知识(按频率分级加载)和工具隔离(权限是最重要的设计决策)。
这里我设计了一张图,希望通过更加工程化的视角帮你建立选型直觉。
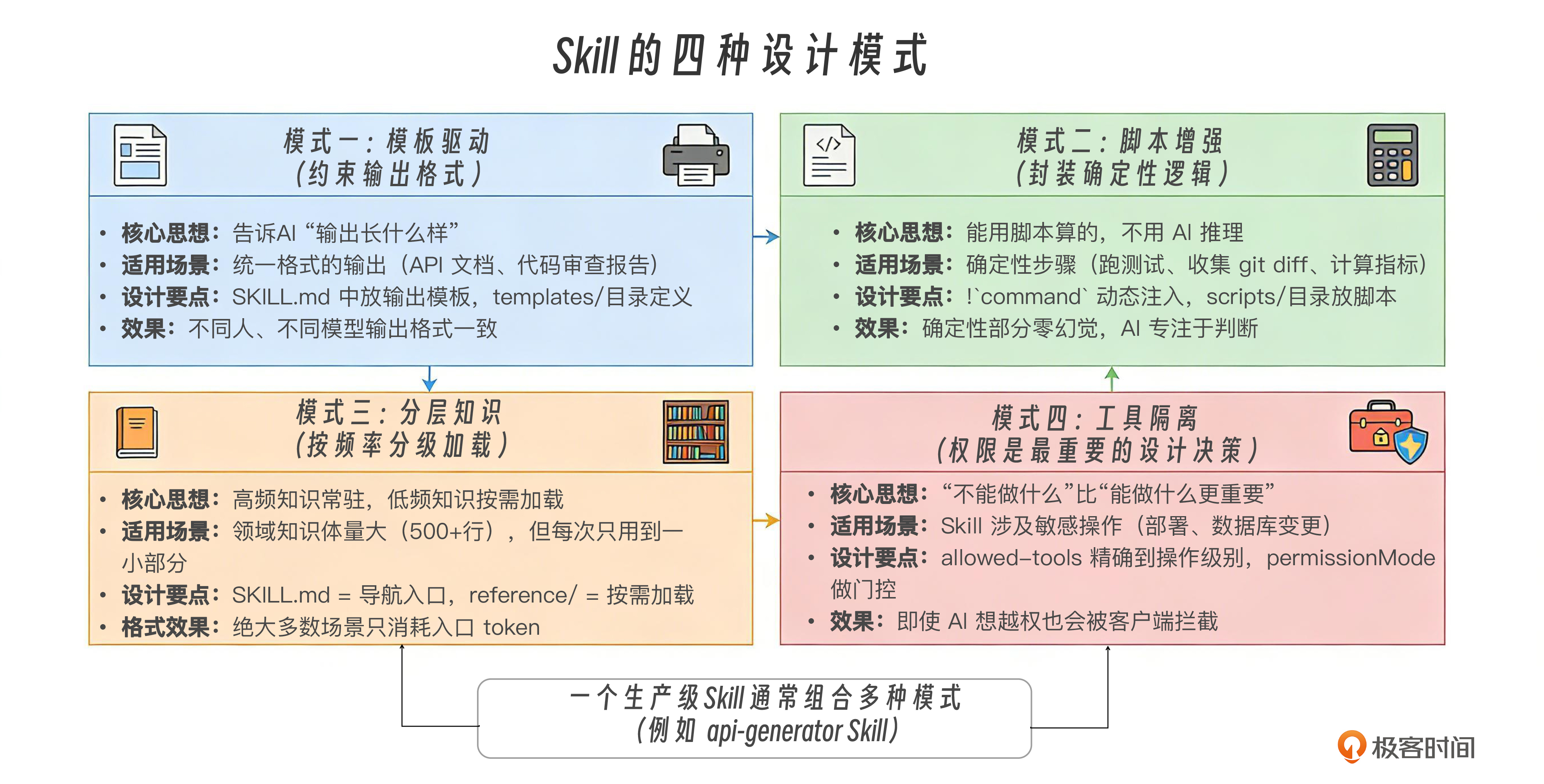
四种模式不是互斥的,一个生产级 Skill 通常组合多种模式。
api-generator Skill(第 12 讲项目 04):
├── 模板驱动:templates/api-doc.md 约束输出格式
├── 脚本增强:!`find src -name "*.ts"` 动态发现文件
├── 分层知识:reference/naming-conventions.md 按需加载
└── 工具隔离:allowed-tools: Read, Grep, Glob, Write
各种模式的综合运用:一个完整案例
在子代理总结中,我们用了“电商大促支付超时”的案例。这次我们换一个 纯 Skills 视角 的案例——看看不依赖 SubAgent 编排,单纯靠 Skills 系统能做到什么。
场景 :你的团队要对一个遗留的 Java 微服务项目做现代化改造——重构为符合团队新规范的代码结构,同时不破坏现有功能。
第一步:规范建立(模板驱动 + 分层知识)
创建 .claude/skills/java-modernization/SKILL.md
结构:
├── SKILL.md(入口:重构流程 + 检查清单)
├── reference/
│ ├── naming-conventions.md (命名规范)
│ ├── package-structure.md (包结构标准)
│ ├── error-handling-patterns.md(异常处理模式)
│ └── api-design-guidelines.md (API 设计规范)
└── templates/
├── refactor-plan.md (重构方案模板)
└── review-checklist.md (审查清单模板)
注意,规范知识按需加载。重构命名时只加载 naming-conventions.md,不加载无关的 api-design-guidelines.md。
第二步:标准流程固化(脚本增强 + 任务型) 创建 .claude/skills/java-refactor-check/SKILL.md
---
name: java-refactor-check
description: 检查 Java 代码是否符合团队现代化规范
disable-model-invocation: true
allowed-tools: Read, Grep, Glob, Bash
---
## 执行流程
1. !`find src -name "*.java" -newer .refactor-baseline | head -50`
→ 动态获取最近修改的文件
2. 逐个检查是否符合 reference/ 中的规范
3. 按 templates/review-checklist.md 格式输出报告
4. 标注:合规 / 不合规 / 需要人工判断
关键提示:disable-model-invocation: true——这是任务型 Skill,只有开发者主动 /java-refactor-check 才会执行,不会在 AI 写代码时“好心帮倒忙”,自动触发审查。
第三步:Skill × SubAgent 组合(领域专家模式)
创建 .claude/agents/java-modernizer.md
---
name: java-modernizer
description: Java 遗留代码现代化改造专家
tools: Read, Write, Edit, Grep, Glob, Bash
model: sonnet
permissionMode: default
skills:
- java-modernization ← 预加载改造规范
- java-refactor-check ← 预加载检查能力
---
你是 Java 现代化改造专家。改造代码时严格遵循预加载的
java-modernization 规范。每完成一个文件的改造后,
立即使用 java-refactor-check 的流程自检。
这就是第 12 讲的核心模式——SubAgent 是“谁来做”,Skill 是“怎么做”。组合后就成了一个懂团队规范的改造专家。
第四步:流水线中的 Skill 切换(Pipeline 模式)
完整的遗留代码现代化流水线:
Phase 1: 扫描评估
→ java-modernizer + java-modernization Skill
→ 产出:重构方案(按 templates/refactor-plan.md 格式)
Phase 2: 逐模块改造
→ java-modernizer + java-modernization Skill
→ 每个模块改完立即自检
Phase 3: 全量检查
→ 手动触发 /java-refactor-check
→ 产出:合规报告(按 templates/review-checklist.md 格式)
Phase 4: 代码审查
→ code-reviewer SubAgent(只读,permissionMode: plan)
→ 关注:改造是否引入了新风险
整体知识流如下。
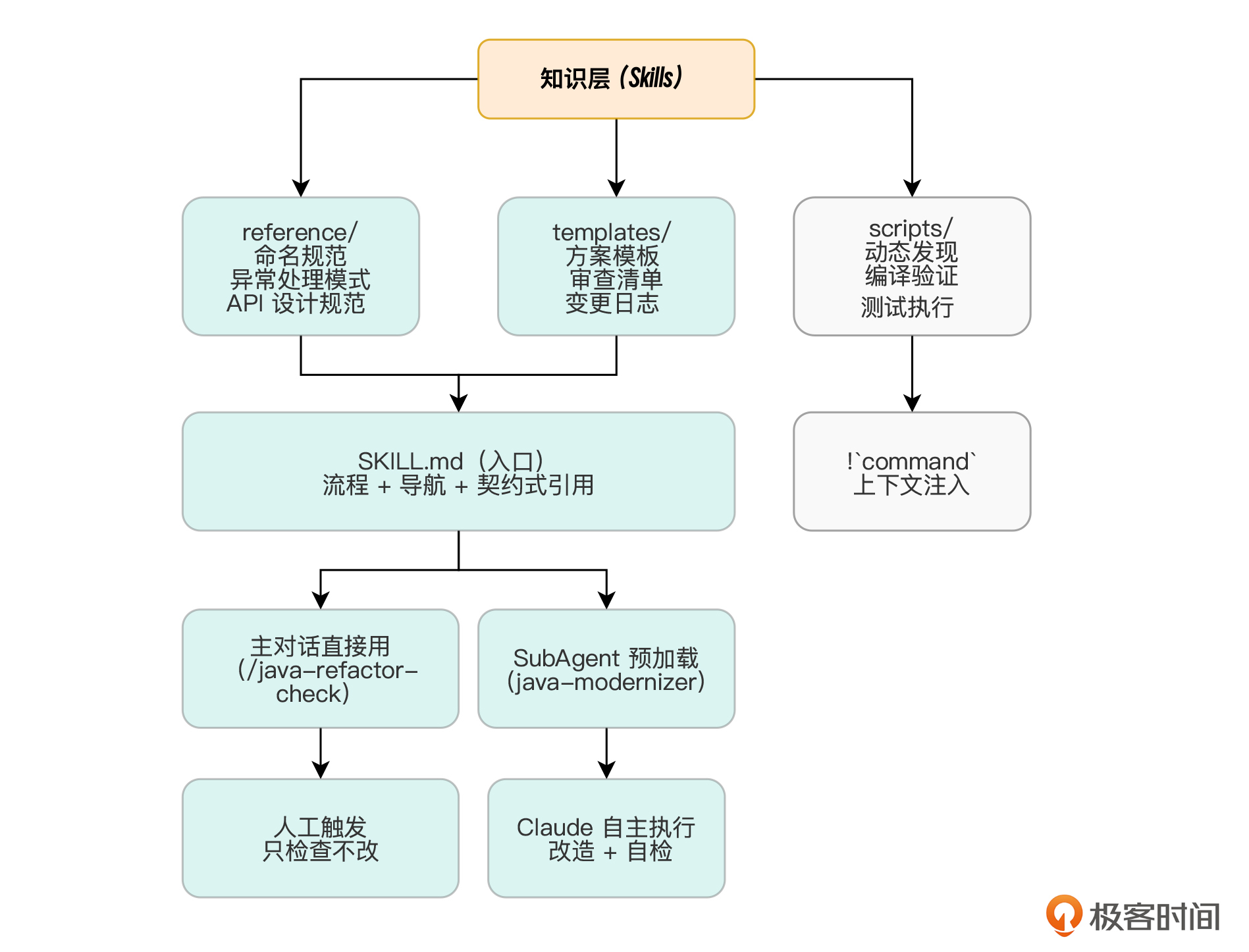
对比子代理案例的关键差异如下。
子代理案例(电商支付超时):
核心是"编排"——谁先做、谁后做、谁的输出给谁
Skills 是配角,SubAgent 是主角
Skills 案例(遗留代码现代化):
核心是"知识"——团队规范怎么沉淀、怎么加载、怎么执行
SubAgent 是载体,Skills 是灵魂
贯穿始终的工程方法论
我们保持了贯穿始终的工程方法论讲解模式。
第 9 讲的方法论是 description 三要素(做什么 + 怎么做 + 什么时候用),解决“Claude 什么时候加载这个 Skill”.
第 10 讲的方法论是七步设计清单(动作→触发→权限→上下文→安全网→隔离→模型),解决“怎么从零设计一个任务型 Skill”.
第 11 讲的方法论是知识 ROI 框架(关键知识常驻 / 补充知识按需 / 冗余知识排除),解决“知识太多怎么组织”
第 12 讲的方法论是两个原子方向(Skill 管 Agent / Agent 载 Skill)× 三种组合模式,解决“Skill 和 SubAgent 怎么配合”
第 13 讲的方法论是企业本体论映射(遇到设计决策,问“在企业里谁管这个”),解决“用哪个机制解决哪类问题”
第 14 讲的方法论是Push vs Pull 框架(高频 Push 到 CLAUDE.md / 低频 Pull 到 Skills),解决”“这条知识放在哪里最高效”
我们所有的Skills方法论的共同主线是: 不是学一个写 SKILL.md的僵化模版,而是锻炼工程化思考与知识管理能力 ,面对任何知识管理场景,能判断用什么机制、怎么组织、放在哪里、和谁配合。
Skills 的终极定义
最后,佳哥给出Skills的终级定义版本—— Skills 是 Claude Code 架构中的知识层,它把人类组织几十年积累的知识管理经验(SOP、专家系统、组织学习)技术化映射到 AI Agent 架构中。
它不是被动的文档,而是有触发条件、有执行流程、有质量标准、有工具约束、有自动检查的可操作知识体系。
它与 Tools(行动层)的关系是共生:约束、编排、反哺。 它与 SubAgents(智能体层)的关系是互补:知识注入 vs 任务委托。 它在五层架构中的位置是承上启下:向下约束工具,向上服务智能体。
而它能出圈成为行业标准的原因是三个本质属性:声明式(纯 Markdown,无运行时依赖)、自包含(一个目录完整交付)、知识本位(价值在内容不在格式)。当格式趋近于纯知识时,采纳就变成了必然。
大作业:为你的团队构建一个生产级 Skill 体系
这个作业不是“写一个 SKILL.md”——那只是第 9 讲的练习水平。这个作业要求你综合运用六讲的全部知识,设计一个 完整的、可交付给团队使用的 Skill 体系 。
作业要求
选择你团队中一个真实的知识管理痛点 ,构建完整的 Skill 解决方案。
参考痛点示例:
- 代码审查标准不统一,不同人审出来的结果天差地别
- 新人不知道 API 该放在哪个微服务里
- 数据库变更没有标准流程,出过生产事故
- 部署流程靠口口相传,关键人离职就断档
交付物清单
1. Skill 目录结构(第 11 讲)
.claude/skills/你的skill名/
├── SKILL.md
├── reference/(至少 2 个知识文件)
├── templates/(至少 1 个输出模板)
└── scripts/(如果有确定性步骤)
2. SKILL.md 设计决策文档(第 9-10 讲)
回答以下问题:
├── description 怎么写的?为什么这样写?(触发精度考虑)
├── 是任务型还是认知型?为什么?
├── allowed-tools 给了哪些?为什么不给更多?
└── 用了哪种设计模式(模板/脚本/分层/隔离)?为什么?
3. 与 SubAgent 的配合方案(第 12 讲)
回答以下问题:
├── 这个 Skill 需要配合 SubAgent 吗?
├── 如果需要,用哪个原子方向(Skill 管 Agent / Agent 载 Skill)?
└── 画出 Skill × SubAgent 的协作图
4. 知识 ROI 分析(第 11 讲)
├── 哪些知识放在 SKILL.md 主文件(高频)?
├── 哪些知识放在 reference/(低频按需)?
├── 哪些知识应该放在 CLAUDE.md 而不是 Skill(全局适用)?
└── 估算:全量加载 vs 渐进加载的 token 差异
5. 企业本体论映射(第 13 讲)
├── 这个 Skill 在企业中对应什么角色/流程?
├── 在五层架构中它和哪些层有交互?
└── 如果团队规模扩大 10 倍,这个 Skill 需要怎么演进?
评估标准
及格线(60 分):
✅ 目录结构完整,SKILL.md 能正常加载
✅ description 能被 Claude 正确触发
良好线(80 分):
✅ 渐进式披露设计合理,token 开销可控
✅ 权限最小化,allowed-tools 有明确理由
✅ 有清晰的设计决策文档
优秀线(95 分):
✅ 与 SubAgent 的配合方案有工程深度
✅ 知识 ROI 分析有数据支撑
✅ 企业本体论映射展示了架构思维
✅ 能说清楚"为什么不用 CLAUDE.md / SubAgent / Hook 来解决"
一个判断标准
最终检验你的 Skill 设计水平的,不是SKILL.md 写得有多漂亮,而是:
把你的 Skill 目录复制给一个从没见过它的同事,他能不能在 5 分钟内理解它做什么、10 分钟内开始使用、30 分钟内产出符合团队标准的工作成果。如果能——你的 Skill 就是一个合格的 **可操作知识体系** 。 这就是 Skills 的核心价值: **让知识可执行、可传递、可复用。** 如果不能——你需要回到第 11 讲,重新审视你的渐进式披露设计。 非常期待你的大作业,如果有什么思考或疑问,也请继续在留言区里交流分享。