释题:未雨绸缪。从 Stop Hook 质量门控到 SubAgent 事件验收,从 frontmatter 精准配置到三维决策框架——每一步都设防,构建滴水不漏的 Hook 工程体系。你好,我是黄佳。 上一讲我们学习了 Hooks 的基础概念——中间件本质、事件体系、配置结构,以及最常用的 PreToolUse 和 PostToolUse 两大实战。PreToolUse 在工具执行前做“入口安检”,PostToolUse 在工具执行后做“过程质检”。 但还有一个关键环节我们没有覆盖: **Claude 做完整个任务后,谁来验收?** 这就好比工厂的流水线:安检门(PreToolUse)检查原料是否合格,质检站(PostToolUse)检查每道工序的产出。但产品最终出厂前,还需要一道 **终检** ——确认成品整体质量达标。这道终检,就是 Stop Hook。 除了 Stop Hook,这一讲中我们还会介绍子代理场景下的 SubagentStart 和 SubagentStop 事件、frontmatter 内置 Hooks 的精准控制、多 Hook 链的组合模式,以及 Hook 工程设计的系统方法论。 内容不少,我们将步步为营,把整个 Hook 体系的高级武器库全部打通。 
Stop Hook——任务完成时的质量门控
Stop Hook 在 Claude 完成响应后 运行。如果说 PreToolUse 是入口安检,PostToolUse 是过程质检,那么 Stop Hook 就是出厂验收——在 Claude 宣布“我做完了”之后,再检查一遍交付物的质量。
Stop Hook 的核心能力是让 Claude 继续工作,Stop Hook 和其他 Hook 的最大区别。这个能力来源于它的 continue 字段:
{
"decision": "block",
"reason": "Tests are failing, please fix them",
"continue": true
}
continue: true 意味着“不要停,继续工作”。这创造了一个自动循环:Claude 认为完成了 → Stop Hook 检查 → 发现测试失败 → 把失败信息反馈给 Claude → Claude 继续修复 → 再次完成 → 再次检查…… 直到所有检查通过,Claude 才被允许真正停下来 。
这种机制把质量保证从“事后检查“变成了”交付前置条件”,这样能让 Claude 不是做完了再检查,而是检查通过了才算做完。
实战:自动测试门控
这是 Stop Hook 最经典的应用——Claude 完成任务后自动运行测试,测试不通过就不让停。
为什么要在 Stop 时运行测试而不是在每次文件修改后?因为一个功能的实现通常涉及多个文件的修改。中间状态的测试必然会失败——你改了接口但还没改实现,测试当然过不了。只有在 Claude 认为“全部完成”的时刻,再运行测试才有意义。
实战项目位于 hooks/run-tests.sh:
#!/bin/bash
# run-tests.sh
# 在 Claude 完成时自动运行测试
set -e
echo "DEBUG: Running tests before stopping..." >&2
# 确定项目目录
if [ -n "$CLAUDE_PROJECT_DIR" ]; then
cd "$CLAUDE_PROJECT_DIR"
fi
# 检测项目类型并运行相应的测试
RUN_TESTS=false
TEST_RESULT=""
TEST_PASSED=true
# Node.js 项目
if [ -f "package.json" ]; then
RUN_TESTS=true
echo "DEBUG: Detected Node.js project" >&2
if grep -q '"test"' package.json; then
TEST_RESULT=$(npm test 2>&1) || TEST_PASSED=false
else
TEST_RESULT="No test script found in package.json"
TEST_PASSED=true # 没有测试不算失败
fi
# Python 项目
elif [ -f "pytest.ini" ] || [ -f "setup.py" ] || [ -f "pyproject.toml" ]; then
RUN_TESTS=true
echo "DEBUG: Detected Python project" >&2
if command -v pytest &> /dev/null; then
TEST_RESULT=$(pytest 2>&1) || TEST_PASSED=false
fi
# Go 项目
elif [ -f "go.mod" ]; then
RUN_TESTS=true
TEST_RESULT=$(go test ./... 2>&1) || TEST_PASSED=false
# Rust 项目
elif [ -f "Cargo.toml" ]; then
RUN_TESTS=true
TEST_RESULT=$(cargo test 2>&1) || TEST_PASSED=false
fi
# 如果没有检测到测试框架
if [ "$RUN_TESTS" = false ]; then
echo '{}'
exit 0
fi
# 转义 JSON 特殊字符
TEST_RESULT_ESCAPED=$(echo "$TEST_RESULT" | head -50 | jq -Rs '.')
if [ "$TEST_PASSED" = true ]; then
# 测试通过,允许停止
echo '{"decision": "approve", "reason": "All tests passed."}'
else
# 测试失败,让 Claude 继续修复
cat <<EOF
{
"decision": "block",
"reason": "Tests are failing. Please fix the issues before stopping.",
"continue": true,
"systemMessage": $TEST_RESULT_ESCAPED
}
EOF
fi
exit 0
让我们逐段解析这个脚本的工作流程。
项目类型检测 :脚本通过检查特征文件来判断项目类型—— package.json 意味着 Node.js,pyproject.toml 意味着 Python,go.mod 意味着 Go,Cargo.toml 意味着 Rust。这种“约定优于配置”的检测方式让脚本能在不同类型的项目中通用,无需额外配置。
容错处理 :grep -q '"test"' package.json 先检查 package.json 中是否有 test 脚本。如果项目根本没有配置测试命令,脚本不会报错,而是报告 “No test script found” 并放行。 没有测试不等于测试失败 ——你不能因为项目还没写测试就阻止 Claude 完成工作。
结果截断 :head -50 只取测试输出的前 50 行。测试失败的输出可能非常长(几百行甚至几千行),但 Claude 只需要看到关键的错误信息就能定位问题。传入太多信息反而会稀释重点(这又是第 6 讲中“信噪比“思维的体现)。
关键分支 :测试通过时,输出 additionalContext 告诉 “Claude All tests passed”,脚本正常退出;测试失败时,输出 "decision": "block" 加 "continue": true,强制 Claude 继续工作。Claude 会收到测试失败的详细信息,然后自动尝试修复。
配置方式:
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "./hooks/run-tests.sh"
}
]
}
]
}
}
注意 Stop 事件没有 matcher 字段——因为 Stop 是生命周期事件,不针对特定工具。
动手试一下 ——进入质量钩子项目,让 Claude 写一段会导致测试失败的代码,观察 Stop Hook 的自动门控行为:
# 进入质量钩子项目(已配好 .claude/settings.json)
cd 06-Hooks/projects/02-quality-hooks
# 启动 Claude Code
claude
进入会话后,给 Claude 一个会产生测试失败的任务:
帮我创建一个 Node.js 项目,写一个 add 函数和对应的测试,但故意让测试失败
当 Claude 写完代码准备停下来时,Stop Hook 自动触发 run-tests.sh。如果测试失败,你会看到:
● Stop hook returned blocking error
Tests are failing. Please fix the issues before stopping.
⎿ [测试失败的详细输出...]
● Claude 继续修复代码...
Claude 收到失败信息后会自动修复,直到测试通过才真正停下来。如果你看到的是 hook error 而不是 blocking error,请检查 jq 是否可用(参见第 15 讲的前置依赖说明)。

这个 Hook 实现了一个强大的保障—— Claude 不会在测试失败的情况下停止工作 。它会不断尝试修复,直到所有测试通过。这在 Claude 执行复杂的重构任务时特别有价值——重构常常会破坏现有测试,而这个 Hook 确保 Claude 会把测试修好才停手。
用 Prompt 类型实现更灵活的 Stop Hook
Shell 脚本适合检查客观事实——测试通不通过、文件存不存在。但有时候你需要检查更“主观”的东西,包括代码风格是否合理?功能实现是否完整?有没有遗漏边界情况?这些判断需要“理解力”,不是模式匹配能解决的。
这时可以用 Prompt 类型的 Stop Hook,让一个小型 LLM(通常是 Haiku)担任代码审查员:
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "prompt",
"prompt": "Review the changes made in this session. Check that: 1) All requested features are implemented 2) No obvious bugs or security issues 3) Code follows project conventions. If any issues found, respond with continue: true and explain what needs to be fixed."
}
]
}
]
}
}
这相当于在 Claude 完成工作后,让另一个 AI 做 code review。两个 AI 的视角不同——主 Claude 相当于作者,Prompt Hook 的 Haiku 担任审查者。审查者往往能发现作者忽略的问题,因为它没有“我刚写的代码当然是对的”这种认知偏见。
当然,Prompt 类型的可靠性低于 Command 类型。LLM 可能漏检,也可能误报。但作为测试门控(Command 类型)之外的 第二层防线 ,它能覆盖一些脚本无法检查的维度。
防止 Stop Hook 死循环:stop_hook_active
Stop Hook 的 continue: true 很强大,但也有风险——如果 Claude 一直修不好,就会进入死循环:测试失败 → Claude 修复 → 测试还是失败 → Claude 再修 → 还是失败……如此无限循环。
所幸官方提供了一个安全字段 stop_hook_active:当 Claude 因为 Stop Hook 而继续工作时,下一次 Stop 事件的输入中 stop_hook_active 会被设为 true。你的脚本应该检查这个字段来避免死循环:
#!/bin/bash
INPUT=$(cat)
# 检查是否已经因为 Stop Hook 继续过了
if [ "$(echo "$INPUT" | jq -r '.stop_hook_active')" = "true" ]; then
# 已经重试过一次了,这次让 Claude 停下来
exit 0
fi
# 正常的测试逻辑
npm test 2>&1
if [ $? -ne 0 ]; then
echo '{"decision": "block", "reason": "Tests still failing, please fix."}'
else
exit 0
fi
这个模式允许 Claude 重试一次——第一次 Stop 时检查测试,如果失败就让 Claude 继续修复;第二次 Stop 时,stop_hook_active 为 true,无论测试是否通过都让 Claude 停下来。
16-1
子代理事件——SubagentStart 与 SubagentStop
在第 3-8 讲中,我们学习了子代理的各种使用模式。现在我们从 Hook 的角度来看子代理—— 如何在子代理启动和完成时自动执行检查?
这两个事件把 Hooks 和 SubAgents 两大机制连接了起来,让你能在子代理的“入口”和“出口“自动插入逻辑。
SubagentStart:为子代理注入上下文
SubagentStart 在子代理被启动时触发。它的 matcher 匹配的是 子代理类型名 ,而不是工具名。

SubagentStart 接收的输入数据包含子代理的标识信息。
{
"session_id": "abc123",
"cwd": "/project/root",
"hook_event_name": "SubagentStart",
"agent_id": "agent-def456",
"agent_type": "code-reviewer"
}
SubagentStart 不能阻止子代理启动 (这是设计决策——启动子代理是主会话的明确意图,不应该被 Hook 否决),但可以通过 additionalContext 向子代理注入上下文信息。
{
"hookSpecificOutput": {
"hookEventName": "SubagentStart",
"additionalContext": "当前分支是 feature/payment-refactor,请特别关注支付相关的代码变更"
}
}
这个能力的价值在于 自动化上下文注入 。比如你有一个 code-reviewer 子代理,每次启动时都需要知道团队的编码规范。
如果没有 SubagentStart Hook,你得在每次调用子代理时手动提醒它“请遵循 camelCase 命名规范“。有了 Hook,这个提醒将自动发生。
{
"hooks": {
"SubagentStart": [
{
"matcher": "code-reviewer",
"hooks": [
{
"type": "command",
"command": "echo '{\"hookSpecificOutput\":{\"hookEventName\":\"SubagentStart\",\"additionalContext\":\"Team coding standards: use camelCase, max line length 100, always add JSDoc for public APIs\"}}'"
}
]
}
]
}
}
这样,每次 code-reviewer 子代理启动时,都会自动收到团队编码规范——不需要在每次调用时手动提醒,不需要把规范写到子代理的 prompt 里(那样会占用子代理的上下文空间)。
SubagentStop:验证子代理的工作成果
SubagentStop 在子代理完成工作后触发。它的决策控制和 Stop 事件完全一致—— 可以阻止子代理停止,强制它继续工作 。
SubagentStop 的输入数据有一个独特的字段,agent_transcript_path。
{
"session_id": "abc123",
"cwd": "/project/root",
"hook_event_name": "SubagentStop",
"stop_hook_active": false,
"agent_id": "agent-def456",
"agent_type": "code-reviewer",
"transcript_path": "~/.claude/projects/.../main-session.jsonl",
"agent_transcript_path": "~/.claude/projects/.../subagents/agent-def456.jsonl"
}
注意两个 transcript path 的区别,transcript_path 是主会话的对话记录,agent_transcript_path 是子代理自己的对话记录。这意味着你的 Hook 脚本可以 读取子代理的完整对话历史 来判断质量——不是只看最终结果,而是能看到子代理是怎么得出结论的。 SubagentStop 的决策控制和 Stop 事件一样,可以用 decision: "block" 阻止子代理完成,强制它继续工作。
{
"decision": "block",
"reason": "Code review is incomplete: you found 3 issues but only provided fixes for 2. Please complete the review."
}
实战:用 SubagentStop 验证代码审查质量
下面这个脚本验证 code-reviewer 子代理的审查是否完整——如果它发现了问题但没有给出修复建议,就强制它继续工作。
这个需求背后的逻辑是:一个好的代码审查不仅要 发现问题 ,还要 提供解决方案 。只说“这里有 bug,而不说建议如何修复的审查是不完整的。Hook 可以把这个“完整性要求”固化为自动检查:
#!/bin/bash
# verify-review-quality.sh
# 验证 code-reviewer 子代理的审查是否完整
INPUT=$(cat)
AGENT_TYPE=$(echo "$INPUT" | jq -r '.agent_type')
STOP_HOOK_ACTIVE=$(echo "$INPUT" | jq -r '.stop_hook_active')
TRANSCRIPT=$(echo "$INPUT" | jq -r '.agent_transcript_path')
# 只检查 code-reviewer
if [ "$AGENT_TYPE" != "code-reviewer" ]; then
exit 0
fi
# 防止死循环
if [ "$STOP_HOOK_ACTIVE" = "true" ]; then
exit 0
fi
# 读取子代理的输出,检查是否包含必要的审查要素
if [ -f "$TRANSCRIPT" ]; then
HAS_ISSUES=$(grep -c "issue\|问题\|bug\|warning" "$TRANSCRIPT" || true)
HAS_SUGGESTIONS=$(grep -c "suggest\|建议\|recommend" "$TRANSCRIPT" || true)
if [ "$HAS_ISSUES" -gt 0 ] && [ "$HAS_SUGGESTIONS" -eq 0 ]; then
cat <<EOF
{
"decision": "block",
"reason": "You found issues but didn't provide suggestions. Please add actionable suggestions for each issue."
}
EOF
exit 0
fi
fi
exit 0
这个脚本的逻辑分为三层防护。
- 第一层 :只检查
code-reviewer类型的子代理,其他子代理直接放行。 - 第二层 :检查
stop_hook_active,防止死循环。 - 第三层 :读取子代理的对话记录,用关键词匹配检查是否包含问题和建议两类内容。如果只有问题没有建议,就阻止子代理完成。
配置方式如下:
{
"hooks": {
"SubagentStop": [
{
"matcher": "code-reviewer",
"hooks": [
{
"type": "command",
"command": "./hooks/verify-review-quality.sh"
}
]
}
]
}
}
当然,用关键词匹配来判断审查质量是比较粗糙的。对于更精细的质量验证,可以用 Prompt 或 Agent 类型的 Hook,让 LLM 来评估子代理的输出:
{
"hooks": {
"SubagentStop": [
{
"matcher": "code-reviewer",
"hooks": [
{
"type": "prompt",
"prompt": "Evaluate this code review result: $ARGUMENTS. Check that: 1) All issues have severity levels 2) Each issue has a concrete suggestion 3) No false positives. Respond with {\"ok\": true} or {\"ok\": false, \"reason\": \"what's missing\"}."
}
]
}
]
}
}
这让 LLM 来理解审查报告的语义,而不仅仅是匹配关键词。它能判断这个建议是否具体可操作,这是脚本无法做到的。
实战项目——完整的 Hook 系统
现在让我们把前面学到的知识组合起来,构建两个完整的 Hook 项目。单个 Hook 解决单个问题,但真正的工程价值在于 多个 Hook 组合成系统 ——就像单个中间件只做一件事,但中间件链条组合起来构成了完整的请求处理管线。
项目一:安全钩子系统
目标 :保护敏感资源,防止危险操作,记录审计日志。 项目结构:
.claude/
├── settings.json
└── hooks/
├── block-dangerous.sh # 阻止危险命令
├── protect-files.sh # 保护敏感文件
└── audit-log.sh # 记录操作日志
.claude/settings.json:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "./hooks/block-dangerous.sh"
}
]
},
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "./hooks/protect-files.sh"
}
]
},
{
"matcher": "Edit",
"hooks": [
{
"type": "command",
"command": "./hooks/protect-files.sh"
}
]
}
],
"PostToolUse": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "./hooks/audit-log.sh"
}
]
}
]
}
}
这个配置创建了一个 纵深防御 体系——三道防线各司其职,形成层层递进的安全屏障。
第一道防线:命令拦截 (PreToolUse → Bash)。在任何 Bash 命令执行前,检查它是否匹配危险命令模式。这是最外层的防护,拦截的是明确的“灾难性操作”——rm -rf /、git push --force origin main、DROP DATABASE 等。
第二道防线:文件保护 (PreToolUse → Write|Edit)。在任何文件写入或编辑操作前,检查目标文件是否是敏感文件。这是第二层防护,拦截的是看似无害但后果严重的操作——Claude 可能只是想”帮你整理配置文件”,但 .env 绝对不能动。
第三道防线:审计日志 (PostToolUse → *)。所有操作完成后,无差别记录到审计日志。这不是防护,而是 事后追溯的能力 。即使前两道防线有漏网之鱼,审计日志也能帮你在事后查明发生了什么。
三道防线的强度递减(拦截 → 拦截 → 记录),但覆盖面递增(Bash → Write|Edit → 所有工具)。这就是经典的纵深防御策略——不把安全寄托在任何单一防线上。

项目二:质量钩子系统
目标 :自动格式化代码,检查 lint 错误,确保测试通过。 项目结构:
.claude/
├── settings.json
└── hooks/
├── auto-format.sh # 自动格式化
├── lint-check.sh # Lint 检查
└── run-tests.sh # 运行测试
.claude/settings.json:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "./hooks/auto-format.sh"
},
{
"type": "command",
"command": "./hooks/lint-check.sh"
}
]
},
{
"matcher": "Edit",
"hooks": [
{
"type": "command",
"command": "./hooks/auto-format.sh"
},
{
"type": "command",
"command": "./hooks/lint-check.sh"
}
]
}
],
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "./hooks/run-tests.sh"
}
]
}
]
}
}
这个配置创建了一个 两阶段质量保证流水线。
第一阶段:逐文件质量保证 (PostToolUse → Write|Edit)。每次 Claude 写入或编辑文件后,立即执行两个操作——先格式化(确保代码风格一致),再 Lint 检查(确保没有语法或逻辑问题)。注意两个 Hook 在同一个 hooks 数组中,它们会 按顺序执行 ——先格式化再 Lint,顺序不能反(否则 Lint 检查的是格式化之前的代码)。
第二阶段:全局质量门控 (Stop)。Claude 完成所有工作后,运行完整的测试套件。如果测试失败,Claude 会收到失败信息并继续修复,直到所有测试通过才被允许停下来。
两个阶段的分工很明确——第一阶段是”边做边查”,保证每个文件的局部质量;第二阶段是做完再验,保证整体功能的正确性。这正是 eesel.ai 博客所描述的效果: Hooks 确定性地运行格式化器和 linter,确保代码符合风格指南;它们还能自动执行测试套件以捕获回归问题。
高级模式与最佳实践
前面的实战项目覆盖了最常见的使用场景。下面来看一些进阶技巧和最佳实践。
多 Hook 链
可以为同一事件配置多个 Hook,它们按顺序执行:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write",
"hooks": [
{ "type": "command", "command": "./hooks/format.sh" },
{ "type": "command", "command": "./hooks/lint.sh" },
{ "type": "command", "command": "./hooks/log.sh" }
]
}
]
}
}
注意执行顺序和中断语义 。三个 Hook 按数组顺序依次执行——先格式化,再 Lint,最后记日志。如果任何一个 Hook 返回阻止决策(比如 lint.sh 返回 exit 2),后续的 Hook(log.sh)不会执行。所以你应该把“不能失败”的 Hook(如日志记录)放在最前面,或者确保它们不会互相干扰。
环境变量
Hooks 可以访问多个环境变量,让你的脚本更灵活。
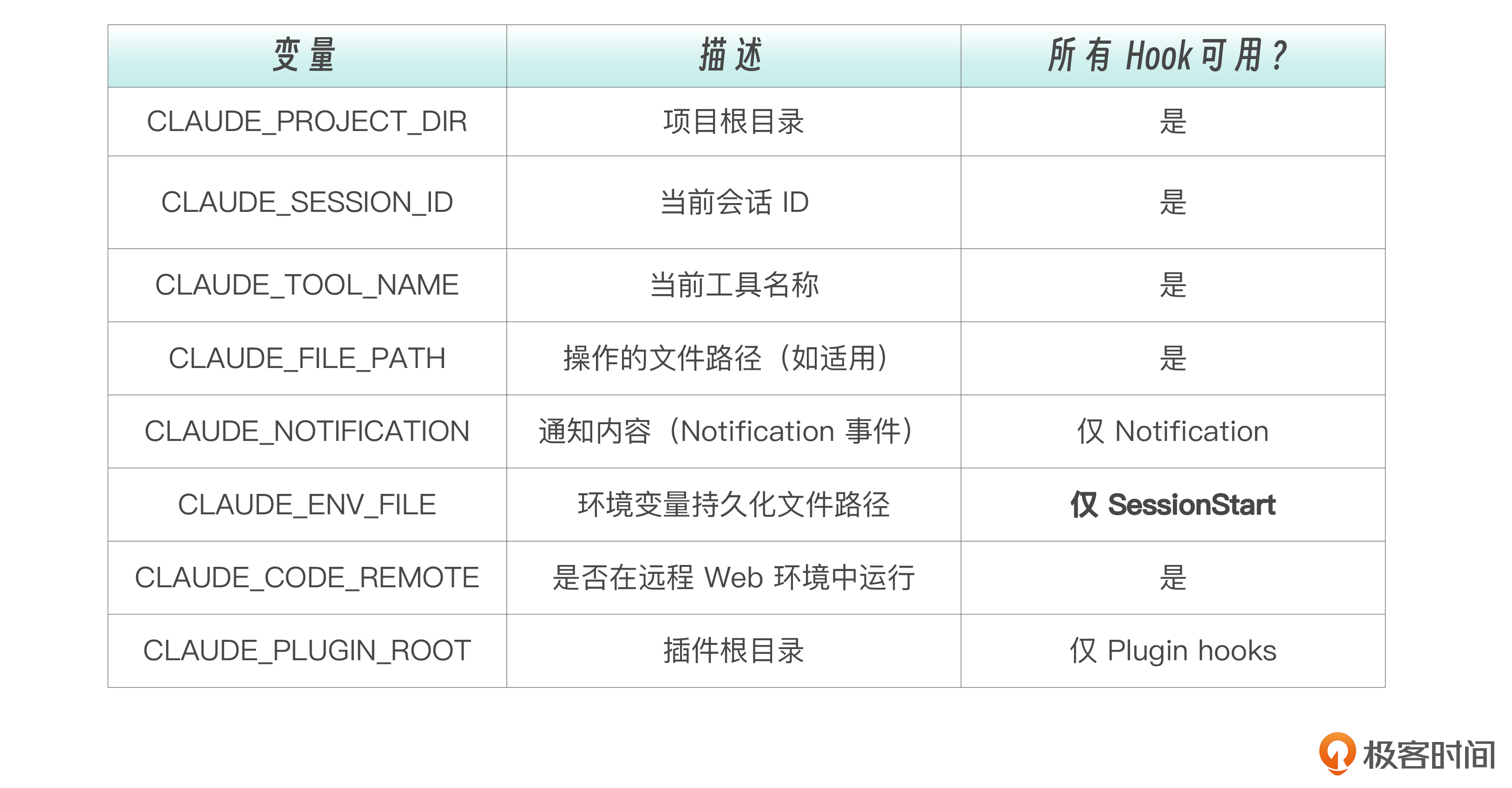
其中 CLAUDE_ENV_FILE 是一个特别有用的变量。SessionStart Hook 可以向这个文件写入 export 语句,这些环境变量会在后续所有 Bash 命令中生效,相当于在会话开始时,就设置了全局环境。
#!/bin/bash
# session-setup.sh - SessionStart hook
if [ -n "$CLAUDE_ENV_FILE" ]; then
echo 'export NODE_ENV=development' >> "$CLAUDE_ENV_FILE"
echo 'export DEBUG_LOG=true' >> "$CLAUDE_ENV_FILE"
fi
exit 0
利用 CLAUDE_FILE_PATH 可以让 Hook 只在特定目录下生效——比如只对 src/ 目录下的文件运行 Lint。
#!/bin/bash
# 只在 src/ 目录执行 lint
if [[ "$CLAUDE_FILE_PATH" == */src/* ]]; then
npm run lint "$CLAUDE_FILE_PATH"
fi
这种条件过滤让 Hook 更精准,你不需要对配置文件、文档、测试文件都跑同样的检查。
在 Commands 和 Skills 中定义临时 Hooks
前一讲我们学过,Commands 和 Skills 可以在 frontmatter 中包含临时 Hooks(仅在该命令/技能执行期间有效)。
---
description: Deploy with safety checks
hooks:
- event: PreToolUse
matcher: Bash
command: |
if [[ "$TOOL_INPUT" == *"production"* ]]; then
echo "Production deployment detected" >&2
fi
- event: PostToolUse
matcher: Edit
command: npx prettier --write "$FILE_PATH"
once: true
---
Deploy the application to staging environment.
once: true 表示 Hook 只触发一次。这适合“完成后运行一次测试”这类不需要重复执行的场景。注意 once 仅在 Skill 中可用,子代理中不支持。
子代理 frontmatter 内置 Hooks——比全局配置更精准的方案
在第 3 讲中,我们学习了子代理的 frontmatter 可以定义各种配置字段。现在来看其中最强大的一个——hooks 字段。
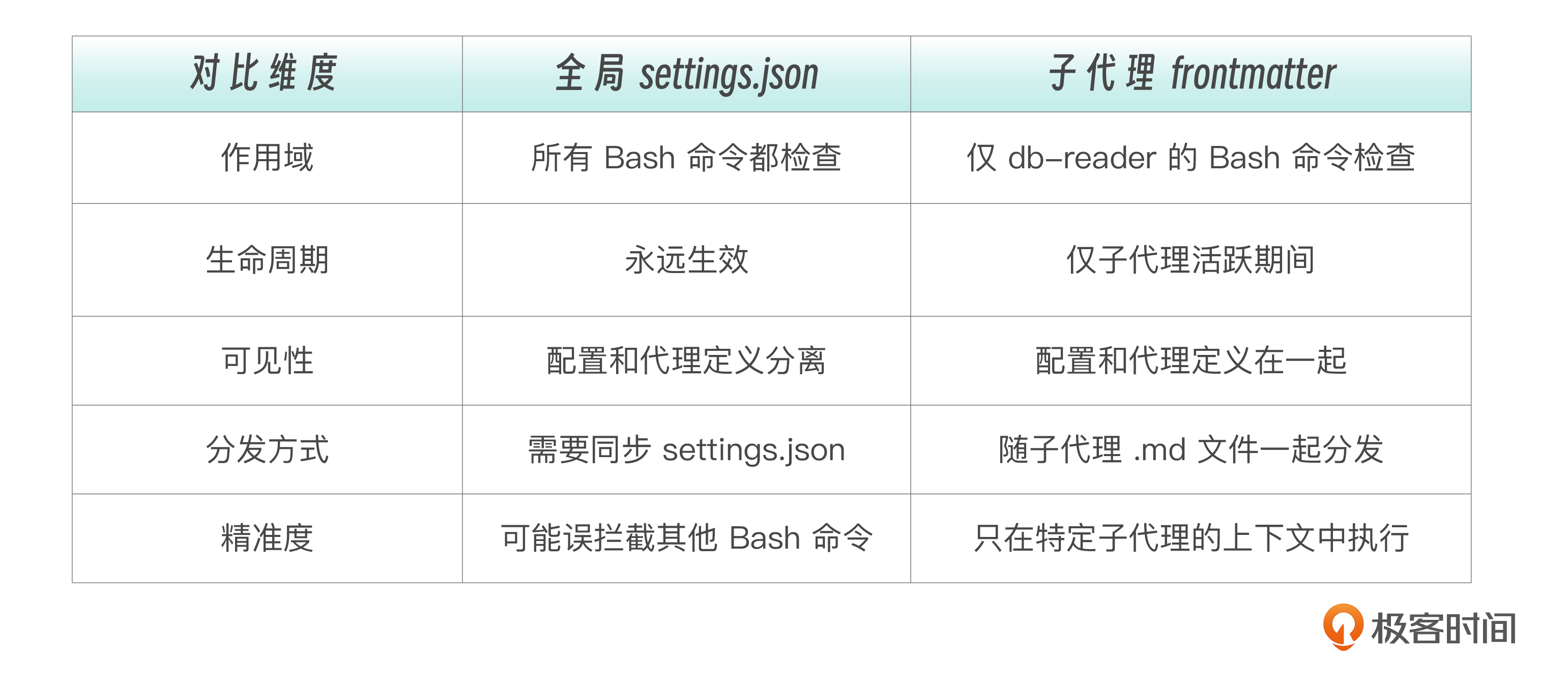
考虑这个场景:你有一个 db-reader 子代理,它可以执行 SQL 查询。你想在它每次执行 Bash 命令前检查 SQL 注入风险。
方案一:全局 settings.json
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "./hooks/check-sql-injection.sh"
}
]
}
]
}
}
问题来了: 所有 Bash 命令都会被 SQL 注入检查——包括 npm install、git status、ls -la 这些和 SQL 毫无关系的命令。这既浪费性能(每次 Bash 命令多执行一个脚本),又可能误拦截(脚本中某个字符串碰巧匹配了 SQL 注入模式)。
方案二:子代理 frontmatter Hooks
---
name: db-reader
description: Read-only database explorer for analyzing data patterns
tools: Read, Grep, Glob, Bash
permissionMode: plan
hooks:
PreToolUse:
- matcher: "Bash"
hooks:
- type: command
command: "./hooks/check-sql-injection.sh"
Stop:
- hooks:
- type: prompt
prompt: "Check if any query results contain PII (names, emails, phone numbers). If so, respond with {\"ok\": false, \"reason\": \"Results may contain PII, please redact before returning\"}."
---
You are a database analysis specialist. Execute read-only SQL queries to help understand data patterns.
## Rules
- ONLY execute SELECT queries
- NEVER use INSERT, UPDATE, DELETE, DROP, or any data-modifying SQL
- Limit results to 100 rows unless explicitly requested
这样做,SQL 注入检查只在 db-reader 子代理的 Bash 命令上触发。主会话和其他子代理的 Bash 命令完全不受影响。
结合下表,两种方案的差异一目了然。
frontmatter Hooks 的关键规则 :
- 支持所有事件类型 :PreToolUse、PostToolUse、Stop 等都可以用。
- Stop 会自动转换为 SubagentStop :在子代理 frontmatter 中定义的
StopHook,实际触发的是SubagentStop事件——因为子代理完成时触发的是 SubagentStop 而非 Stop。 - 生命周期绑定 :Hook 在子代理启动时激活,子代理完成时自动清理。
- 格式与 settings.json 一致 :YAML 格式,但字段名和结构完全相同。
为了让你加深理解,我们来看一个更复杂的例子,这是一个带安全检查的部署子代理。
---
name: deploy-checker
description: Verify deployment readiness with safety checks
tools: Read, Grep, Glob, Bash
hooks:
PreToolUse:
- matcher: "Bash"
hooks:
- type: command
command: |
INPUT=$(cat)
CMD=$(echo "$INPUT" | jq -r '.tool_input.command // ""')
# 阻止任何直接操作生产环境的命令
if echo "$CMD" | grep -qi "production\|prod-db\|deploy.*--force"; then
echo '{"hookSpecificOutput":{"hookEventName":"PreToolUse","permissionDecision":"deny","permissionDecisionReason":"Direct production operations are not allowed in this agent. Use the deployment pipeline instead."}}'
fi
Stop:
- hooks:
- type: agent
prompt: "Review the deployment check results. Verify that: 1) All health checks pass 2) No breaking API changes detected 3) Database migrations are backward-compatible. $ARGUMENTS"
timeout: 60
---
You are a deployment readiness checker...
这个子代理有两层保护。 PreToolUse Hook 用确定性规则阻止直接操作生产环境的命令,这是“硬规则”,不需要判断力,只需要模式匹配。 Stop Hook (实际触发为 SubagentStop)用 Agent 类型验证部署检查结果——这需要判断力和代码检查能力,所以用了最强的 Agent 类型。
什么时候用 frontmatter Hooks vs 全局 Hooks?
判断流程很简单:
判断流程:
├── 这个 Hook 是否只与特定子代理相关?
│ ├── 是 → frontmatter Hooks
│ │ 例:db-reader 的 SQL 注入检查、deploy-checker 的生产环境保护
│ └── 否 → 全局 settings.json
│ 例:所有 Write 操作后的格式化、所有 Bash 命令的危险命令拦截
│
├── 这个 Hook 是否需要随子代理定义一起分发?
│ ├── 是 → frontmatter Hooks
│ │ 例:开源项目中的子代理,使用者不需要额外配置 settings.json
│ └── 否 → 全局 settings.json
│
└── 这个 Hook 是否需要在子代理外也生效?
├── 是 → 全局 settings.json
└── 否 → frontmatter Hooks
调试技巧
Hook 脚本出问题时,调试手段和普通 Shell 脚本有所不同,因为 Hook 的 stdin/stdout 都有特殊用途。我来为你分享四个最实用的调试技巧。
1. 使用 stderr 输出调试信息
# 调试信息输出到 stderr(不影响 JSON 响应)
echo "DEBUG: Processing file $FILE_PATH" >&2
# 正常输出到 stdout
echo '{"decision": "allow"}'
记住,stdout 是给 Claude 读的 JSON,stderr 是给你看的调试信息。混淆两者是 Hook 开发中最常见的错误。
2. 手动测试 Hook 脚本 不需要启动 Claude 就能测试你的 Hook——手动构造 JSON 输入,通过管道传给脚本:
# 创建测试输入
echo '{
"tool_name": "Bash",
"tool_input": {
"command": "rm -rf /tmp/test"
}
}' | ./hooks/block-dangerous.sh
# 检查退出码
echo "Exit code: $?"
这让你能在开发过程中快速迭代——修改脚本、手动测试、检查输出,不需要每次都等 Claude 触发。
3. 使用 claude --debug 查看完整执行细节
[DEBUG] Executing hooks for PostToolUse:Write
[DEBUG] Found 1 hook matchers in settings
[DEBUG] Matched 1 hooks for query "Write"
[DEBUG] Hook command completed with status 0: <stdout output>
也可以在会话中用 Ctrl+O 切换详细模式(verbose mode),在对话记录中查看 Hook 的输出。
4. 常见问题排查清单
- Hook 不触发 :检查 matcher 是否正确(区分大小写);如果直接编辑了 settings 文件,需要在
/hooks菜单中确认或重启会话才能生效。 - 权限问题 :确保脚本有执行权限——
chmod +x hooks/*.sh - JSON 解析错误 :确保输出是有效 JSON。注意:如果你的 shell profile。(
~/.zshrc或~/.bashrc)中有无条件的echo语句,它会污染 stdout 导致 。JSON 解析失败。解决方法是用[[ $- == *i* ]]包裹 echo,只在交互式 shell 中输出。 - Stop Hook 死循环 :检查是否遗漏了
stop_hook_active判断(参见前面的”防止死循环”一节)。
异步 Hook:后台执行不阻塞
默认情况下,Hook 会阻塞 Claude 的执行直到完成。这在大多数场景下是合理的——安全检查必须在操作前完成,格式化必须在下一步操作前完成。但对于耗时操作(运行完整测试套件、发送通知、调用外部 API),阻塞会显著拖慢 Claude 的响应速度。
async: true 让 Hook 在后台运行,不阻塞主流程:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "./hooks/run-tests-async.sh",
"async": true,
"timeout": 300
}
]
}
]
}
}
你需要知道 异步 Hook 的三个限制。
- 只有
type: "command"支持异步,prompt 和 agent 类型不支持——因为它们需要实时影响 Claude 的决策。 - 异步 Hook 不能阻止操作 ,因为操作在 Hook 完成前就已经继续了
- Hook 完成后的输出会在 下一个对话轮次 传递给 Claude,这是有延迟的。
所以异步 Hook 适合“我不需要立即知道结果”的场景,在后台跑测试、发送 Slack 通知、写日志到远程服务。
HTTP Hook:对接外部服务
前面讲的 command、prompt、agent 三种 Hook 类型,执行逻辑都在本地——要么跑脚本,要么调 LLM。但有些场景下,Hook 的处理逻辑不在本地,而是在一个远程服务上:团队共享的审计服务、集中式的安全扫描平台、公司内部的合规检查 API。
这时候就该用 type: "http"。HTTP Hook 把事件数据以 POST 请求发送到指定 URL,由远程服务处理后返回决策结果。
{
"hooks": {
"PostToolUse": [
{
"hooks": [
{
"type": "http",
"url": "http://localhost:8080/hooks/tool-use",
"headers": {
"Authorization": "Bearer $MY_TOKEN"
},
"allowedEnvVars": ["MY_TOKEN"]
}
]
}
]
}
}
远程服务收到的 JSON 和 command Hook 从 stdin 读到的完全一样。返回的响应体也遵循相同的 JSON 格式——要阻止工具调用,在响应体里返回对应的 hookSpecificOutput 字段即可。注意:HTTP 状态码(如 403)不能阻止操作,必须在 2xx 响应体里用 JSON 表达决策。 headers 中的值支持 $VAR_NAME 语法做环境变量插值,但只有 allowedEnvVars 列表中的变量才会被解析,其他 $VAR 引用会保持为空。这是一个安全设计——防止意外泄露环境变量。
HTTP Hook 有一个限制,目前只能通过手动编辑 settings JSON 来配置,/hooks 交互菜单暂不支持添加 HTTP 类型。
四种 Hook 类型各有所长,我为你梳理了表格。
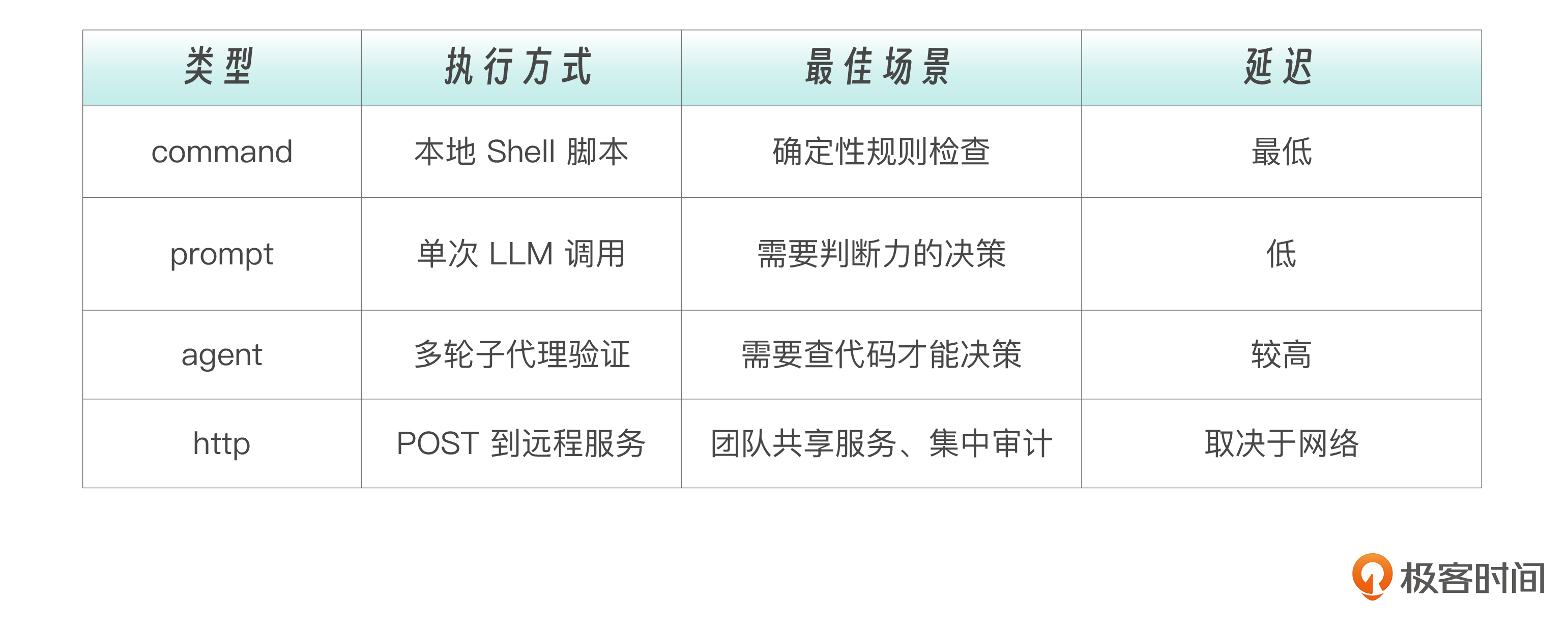
选择原则不变: 能用 command 解决的不要用 prompt,能用 prompt 解决的不要用 agent,需要对接远程服务时用 http 。
安全最佳实践
最后,我们来梳理几条在生产环境中久经验证的安全建议。
- 使用绝对路径引用脚本 :用
"$CLAUDE_PROJECT_DIR"/.claude/hooks/xxx.sh,比相对路径更可靠。相对路径在子代理中可能解析到错误的目录。 - 最小权限原则 :PreToolUse 只检查必要的条件。检查越多,误拦截的概率越高,用户绕过 Hook 的冲动也越强。
- 快速失败 :Hook 应该快速返回,避免长时间阻塞。如果确实需要耗时操作,用
async: true。 - 优雅降级 :格式化工具不存在时应跳过而不是报错。Hook 的失败不应该阻碍正常工作流。
- 输入校验 :永远不要盲目信任 stdin 输入,用
jq解析并验证。 - 引号包裹变量 :使用
"$VAR"而非$VAR,防止路径中的空格导致问题。 - 路径遍历防护 :检查文件路径中是否有
..,防止恶意路径逃逸。
Hook 工程设计方法论
前面教的是“Hooks 能做什么、怎么配置”。
下面来回答一个更重要的工程问题: 面对一个具体需求,如何系统地设计 Hook 方案?
三维决策框架
设计一个 Hook 方案,我们需要想清楚三个问题。

三个维度两两正交——你可以在任何事件上使用任何类型的 Hook,配置在任何位置。但能做不等于应该做。好的工程设计是在这三个维度上找到最恰当的交叉点——用最轻量的类型解决问题,在最小的作用域内生效。
Hook + SubAgent 组合模式
Hooks 和 SubAgent 是两个独立的机制,但组合使用时能产生强大的协同效果。
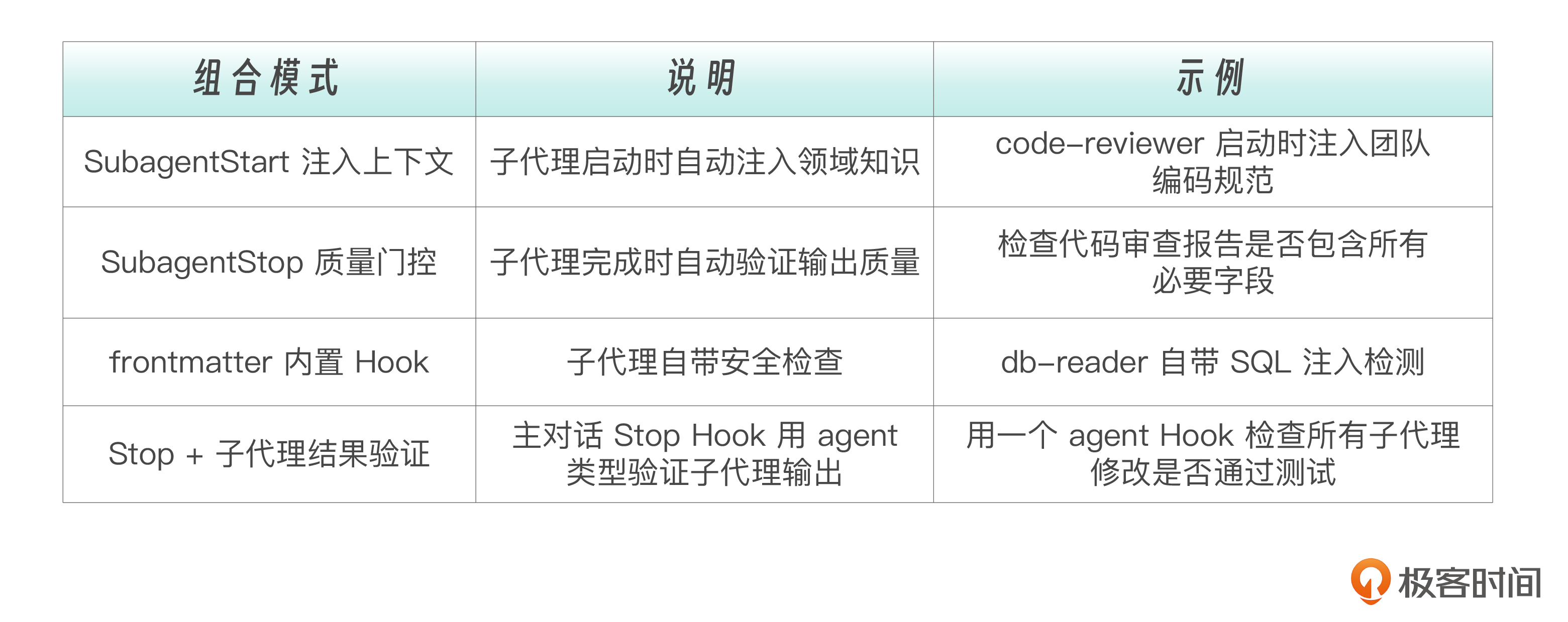
来看一个完整的组合案例,这是一个带质量门控的代码审查子代理。
子代理定义(.claude/agents/code-reviewer.md)
├── frontmatter
│ ├── tools: Read, Grep, Glob
│ ├── permissionMode: plan
│ └── hooks:
│ └── Stop: prompt hook 检查审查是否完整
│
全局 settings.json
├── SubagentStart hook(matcher: code-reviewer)
│ └── 注入当前分支的变更列表
└── SubagentStop hook(matcher: code-reviewer)
└── 验证审查报告格式和质量
这三层保护各司其职:
- frontmatter Hook :子代理内部的自检,检测我的输出完整是否完整。
- SubagentStart Hook :外部注入,给它必要的上下文。
- SubagentStop Hook :外部验收,判断它的工作是否达标。
内部自检发现的是“自己知道自己漏了什么”的问题,外部验收发现的是“它觉得完成了,但其实不够好”的问题。两者视角不同,互为补充。

总结一下
这一讲我们深入学习了 Hooks 的高级特性和工程实践方法。两讲合在一起,我们完整覆盖了 Hooks 的全部知识体系。
从概念(AI 中间件)到配置(六个位置、四种类型),从核心事件(PreToolUse、PostToolUse、Stop)到高级事件(SubagentStart、SubagentStop),从单个 Hook 到组合系统,从实战脚本到工程方法论。
Hooks 是 Claude Code 扩展机制中唯一能拦截和修改 AI 行为的组件。用好它,就能在享受 AI 效率的同时,守住安全和质量的底线。
思考题
- Stop Hook 的
continue: true创造了一个“修复循环”。结合stop_hook_active机制,你会如何设计一个允许最多 3 次重试的 Stop Hook?请写出伪代码。 - 对比全局 settings.json 和子代理 frontmatter 两种 Hook 配置方式,你的项目中哪些 Hook 适合放在全局,哪些适合放在特定子代理的 frontmatter 中?请举出具体场景。
- 设计一个完整的“代码提交前自动检查”Hook 方案:需要检查哪些维度?用什么事件?用 command/prompt/agent 哪种类型?为什么?
- Hook + SubAgent 组合模式中,frontmatter 内部自检和 SubagentStop 外部验收各自能发现什么类型的问题?两者的视角差异在哪里?
下一讲预告
Hooks 让 Claude 在执行工具时自动响应,但 Claude 能调用的工具毕竟有限——它能读文件、写代码、执行命令,但不能查数据库、调 API、访问第三方服务。
下一讲,我们将学习 MCP 协议与外部工具连接 ——通过 Model Context Protocol 把数据库、API、第三方服务变成 Claude 可调用的工具。
本讲示例项目对应表
本讲新增 1 个可运行脚本,其余 5 个脚本在上一讲已介绍(见第 15 讲对应表)。本讲的“项目一/项目二”章节将它们组合成完整系统。
本讲新增的可运行脚本 。

本讲的内联代码示例 (演示高级模式,未独立成脚本文件)。
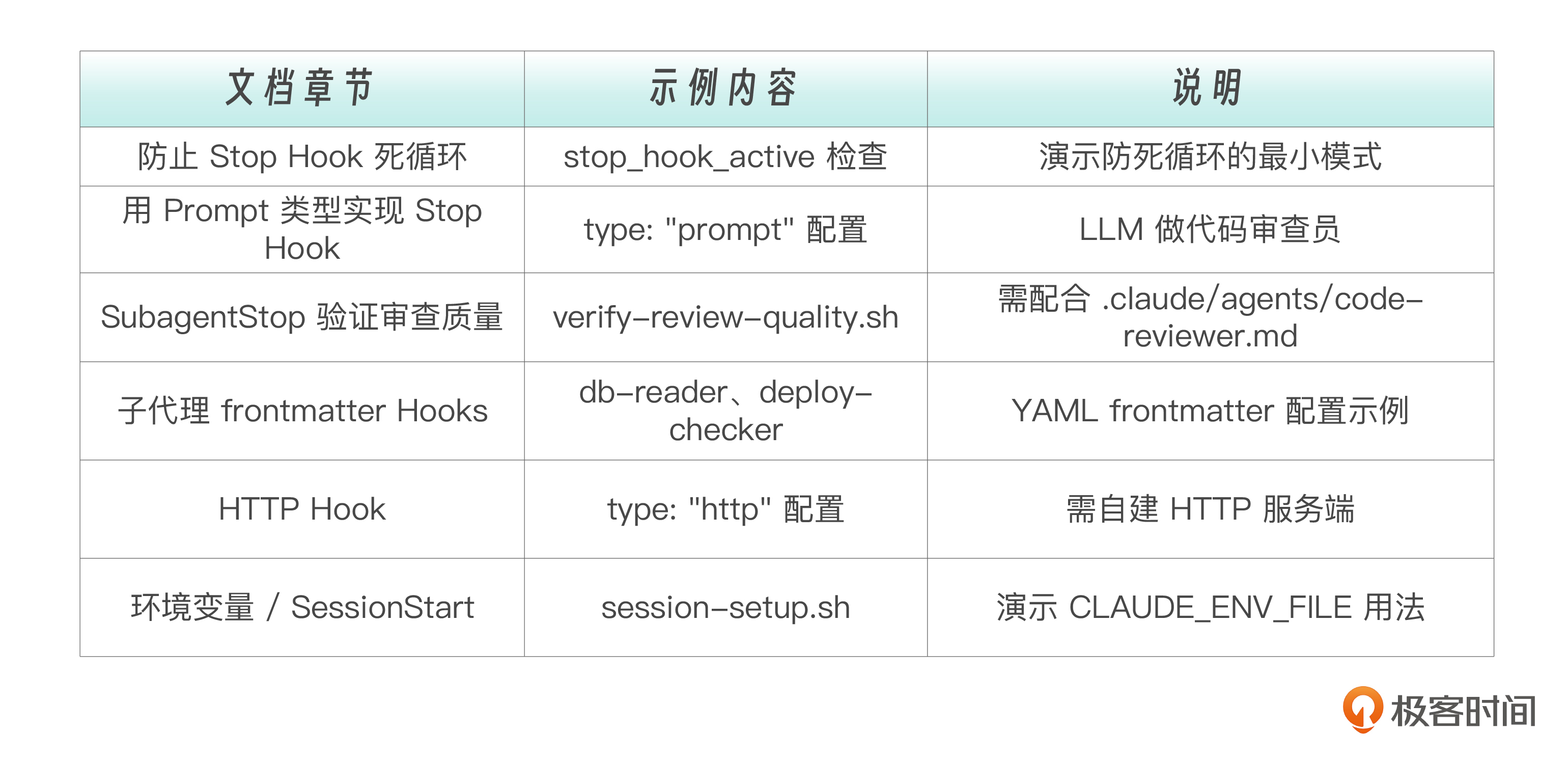
完整项目结构 :
06-Hooks/projects/
├── 01-safety-hooks/
│ ├── .claude/settings.json ← 3 条规则:PreToolUse(Bash) + PreToolUse(Write|Edit) + PostToolUse(*)
│ ├── hooks/
│ │ ├── block-dangerous.sh
│ │ ├── protect-files.sh
│ │ └── audit-log.sh
│ └── README.md
└── 02-quality-hooks/
├── .claude/settings.json ← 3 条规则:PostToolUse(Write|Edit) + Stop
├── hooks/
│ ├── auto-format.sh
│ ├── lint-check.sh
│ └── run-tests.sh
└── README.md
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。