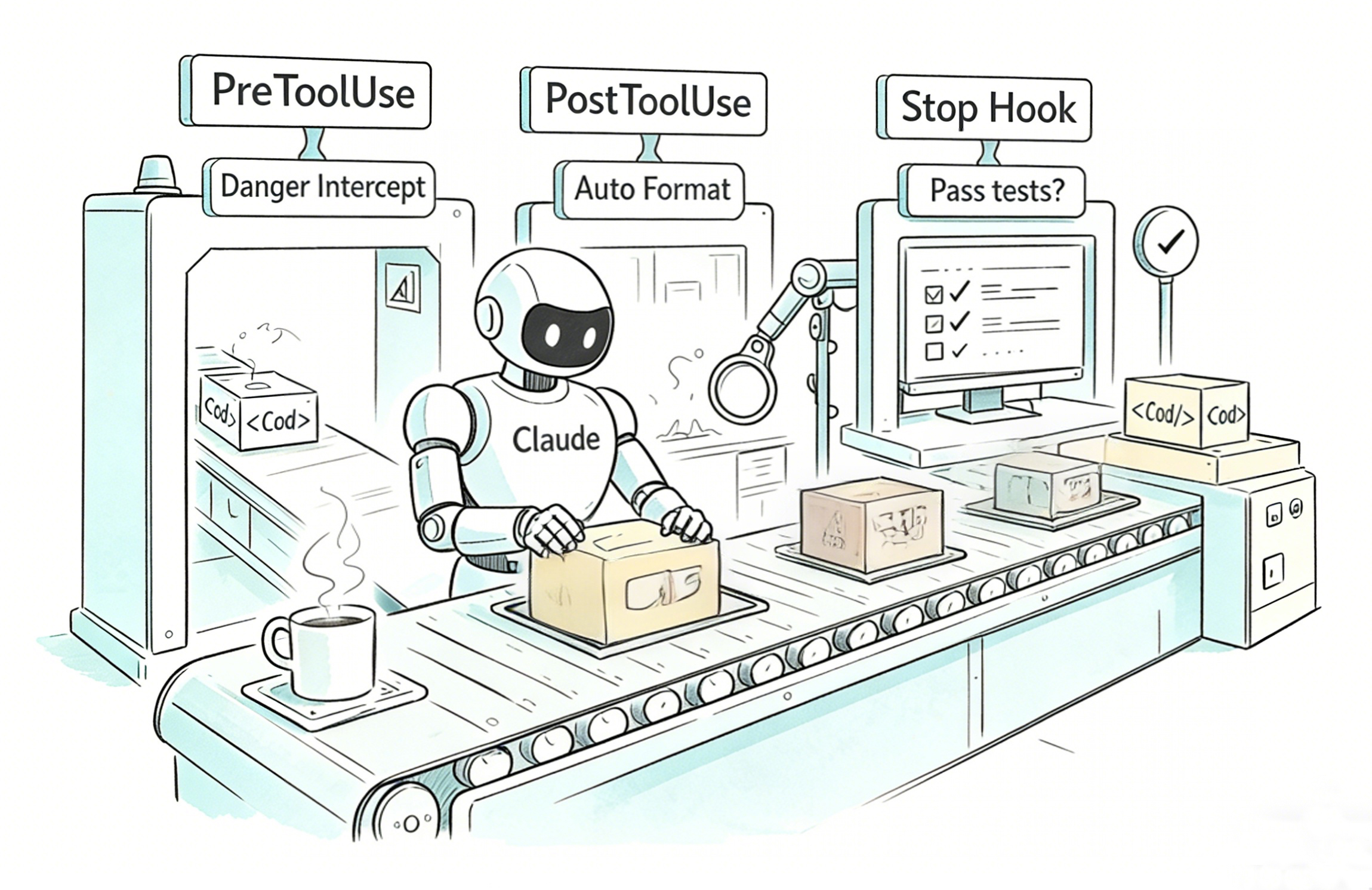
**释题:防微杜渐。** 在 Claude 执行工具前后插入自定义检查,阻止危险命令、保护敏感文件、自动格式化代码——在小问题萌芽时就防止它演变成灾难。你好,我是黄佳。 前面我们学习了 Skills 的完整知识体系——从知识工程到系统集成,从按需加载到跨平台通用。Skills 告诉 Claude“怎么做”,Commands 告诉 Claude“做什么”。但有一个关键问题它们都解决不了—— **Claude 能不能做?** 今天我们进入一个全新的领域——Hooks,事件驱动自动化。它是 Claude Code 三大扩展机制中唯一能 **拦截和修改** Claude 行为的机制,也是工程化实践中安全防线的最后一道闸门。  举个例子,咖哥用 Claude Code 快速写完了代码,测试通过,`git push`,然后关机睡觉。 这种AI辅助下的快速迭代,代价有时候是灾难性的。安全漏洞、敏感信息泄露、代码格式混乱、测试没跑就上线……这些问题的共同点是: **它们本可以被自动阻止** 。 如果有一道看不见的防线,在代码提交前自动检查敏感文件、在文件保存后自动格式化、在 Claude 完成任务时自动运行测试——那些“忘记”就不再是问题。 这道防线,就是 **Hooks** 。
Hooks 的本质——AI 时代的中间件
如果你有 Web 开发经验,你一定熟悉中间件(Middleware)的概念。
请求 → 中间件1 → 中间件2 → 中间件3 → 处理函数
↓
认证、日志、限流
中间件在请求到达最终处理函数之前插入检查和处理,实现横切关注点(Cross-cutting Concerns)。这些逻辑不属于任何一个业务功能,但又必须贯穿所有请求——认证要每个接口都检查,日志要每个操作都记录,限流要每个入口都控制。
Claude Code 的 Hooks 机制与此异曲同工,但它针对的不是 HTTP 请求,而是 AI Agent 的工具调用。
用户请求 → Claude 决策 → [PreToolUse Hook] → 工具执行 → [PostToolUse Hook] → 响应
↓ ↓
权限检查、拦截 格式化、验证、日志
Hooks 是 AI 助手的中间件——拦截、监控、增强每一次交互。 这个类比不仅是形象上的相似。Web 中间件解决的核心问题是“业务代码不应该操心安全和日志”,Hooks 解决的核心问题也一样—— Claude 不应该操心格式化和权限检查,它只管写好代码就行 。安全防线、质量守卫、审计日志,全部由 Hooks 在“幕后”自动完成。
 和 Commands 和 Skills 相比, Hooks 是三者中唯一能拦截和修改 Claude 行为的机制 。
和 Commands 和 Skills 相比, Hooks 是三者中唯一能拦截和修改 Claude 行为的机制 。
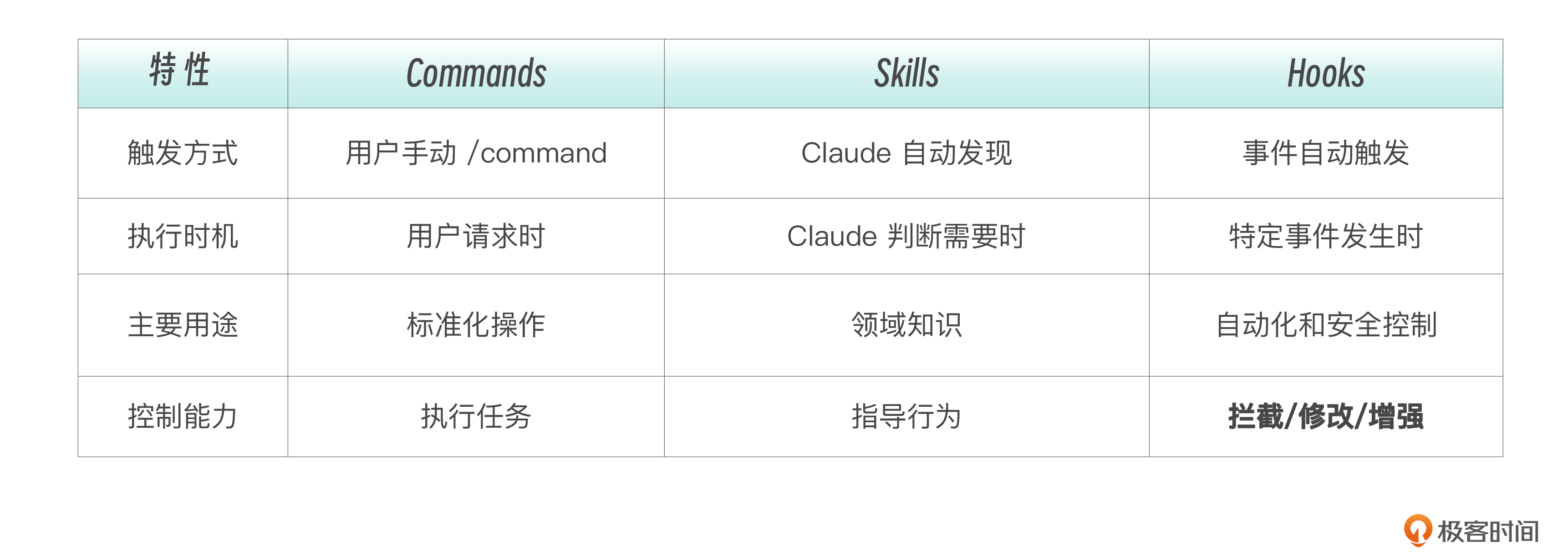 这三者构成了一个完整的控制谱系。
这三者构成了一个完整的控制谱系。
 如果把 Claude 比作一个工程师,Commands 是你给他下达的任务指令,Skills 是他掌握的领域知识,而 Hooks 是公司的安全制度和质量规范—— 不管你做什么任务、用什么知识,这些制度都在背后默默运行 。
如果把 Claude 比作一个工程师,Commands 是你给他下达的任务指令,Skills 是他掌握的领域知识,而 Hooks 是公司的安全制度和质量规范—— 不管你做什么任务、用什么知识,这些制度都在背后默默运行 。
17 种 Hook 事件——完整生命周期覆盖
截至2026年3月,根据 Anthropic 官方文档,Claude Code 支持 17 种 Hook 事件,覆盖了从会话启动到结束的完整生命周期:
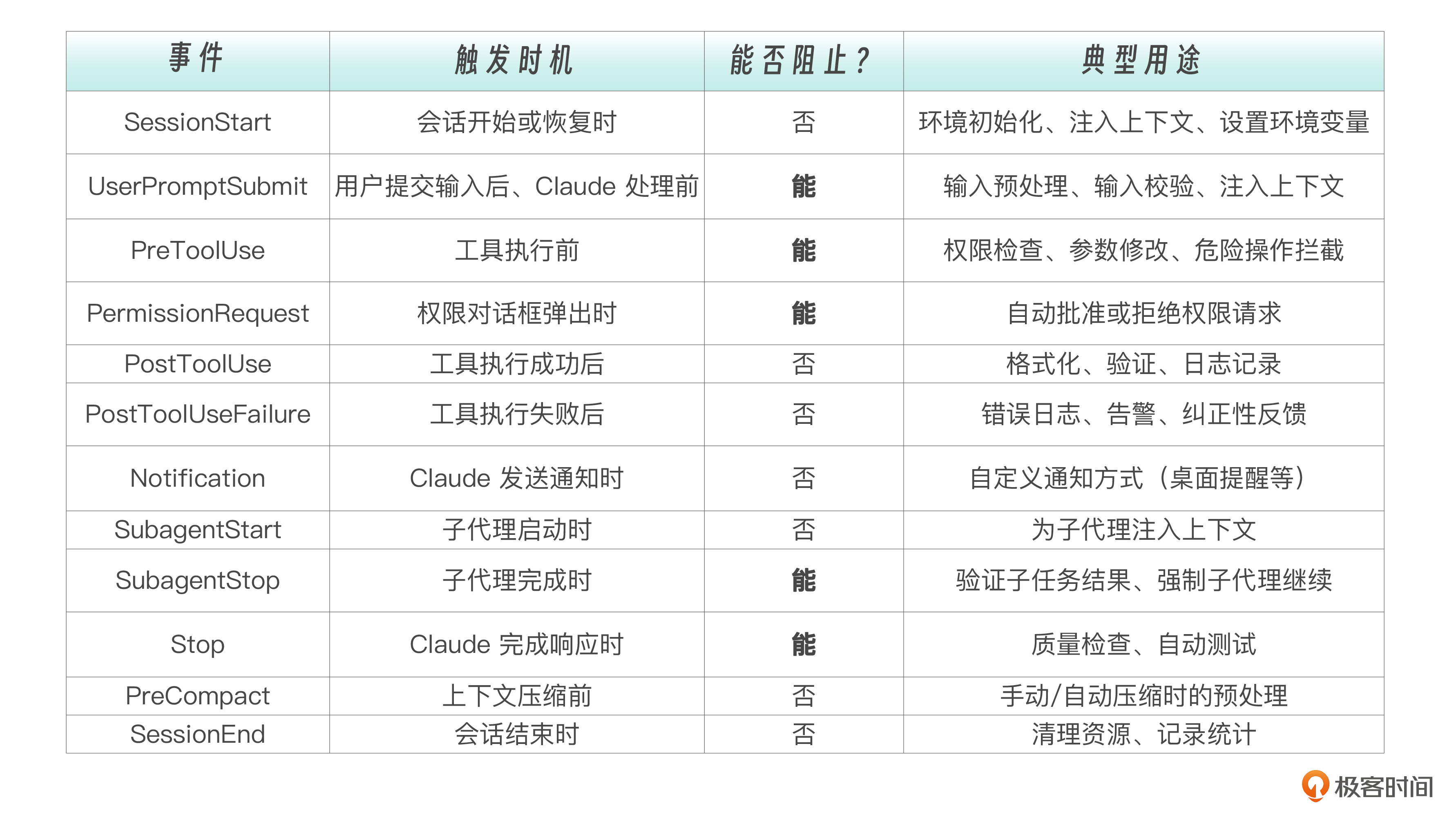
17 个事件,乍看数量不少,但它们的设计逻辑非常清晰——按照“能否阻止”这一列来看,整个事件体系分为三大阵营。
- 控制点——能阻止的事件 (PreToolUse、UserPromptSubmit、Stop、SubagentStop):你可以通过它们改变 Claude 的执行路径——拦截危险操作、拒绝不合理的输入、强制 Claude 继续修复。它们是 Hooks 系统的肌肉。
- 接管点——替代默认行为的事件 (PermissionRequest):它不是简单地阻止,而是接管了原本由用户手动处理的权限弹窗——你的脚本可以自动批准或拒绝权限请求,替代人类的决策。它是 Hooks 系统的自动驾驶。
- 观察点——不能阻止的事件 (SessionStart、PostToolUse、PostToolUseFailure、Notification、SubagentStart、PreCompact、SessionEnd):你只能在这些时刻做记录、做反馈、做后处理,但不能改变已经发生的事情。它们是 Hooks 系统的眼睛。
这种不对称设计是有意为之的。工具执行前可以拦截,因为操作还没发生,拦截不会造成不一致状态。工具执行后不能拦截,因为操作已经完成——你不能“取消”一个已经写入磁盘的文件。但你可以观察它、记录它、反馈它。

Hook 配置详解
掌握了事件体系,下面来看具体怎么配置。Hooks 可以在多个位置配置,每个位置有不同的作用域和共享策略。
最后一行值得特别关注—— Hooks 可以直接定义在子代理的 frontmatter 中 ,只在该子代理执行期间生效。这比在全局 settings.json 中配置更精准,后面会详细讲解。
怎么选择配置位置?一个简单的判断流程:
- 用户级 (
~/.claude/settings.json):个人习惯。比如你喜欢的日志格式、桌面通知方式。这些配置只影响你自己,不需要和团队同步。 - 项目级 (
.claude/settings.json):团队约定。比如代码格式化规则、敏感文件保护列表。这些配置应该提交到 git,让团队所有成员共享。 - 本地覆盖 (
.claude/settings.local.json):当你需要在本地临时覆盖团队配置时使用,比如调试时关闭某个 Hook。 - 子代理 frontmatter :子代理专属的 Hook。比如
db-reader的 SQL 注入检查——这个检查只和数据库操作相关,不应该影响其他场景。
一个典型的 Hook 配置长这样:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "./hooks/block-dangerous.sh"
}
]
}
],
"PostToolUse": [
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "prettier --write $CLAUDE_FILE_PATH"
}
]
}
]
}
}
这个 JSON 结构有三层嵌套,初看可能有点绕。让我用树形图来拆解它的逻辑层次。
hooks ← 第一层:顶层容器
├── PreToolUse ← 第二层:事件类型(什么时候触发)
│ └── [第一组规则]
│ ├── matcher: "Bash" ← 第三层:匹配器(针对哪个工具)
│ └── hooks: [...] ← 第三层:Hook 列表(执行什么)
│ └── type: "command"
│ └── command: "..."
└── PostToolUse
└── [第二组规则]
├── matcher: "Write"
└── hooks: [...]
第一层 选择“什么时候”——在工具执行前还是执行后? 第二层 选择“针对谁”——是所有工具还是特定工具? 第三层 选择“做什么”——执行脚本、调用 LLM、还是启动子代理?三层决策,层层收窄,最终精准地把正确的检查逻辑应用到正确的时机和工具上。 Matcher 匹配 用于指定 Hook 应用于哪些工具。它支持四种匹配模式:
// 精确匹配单个工具
"matcher": "Write"
// 匹配多个工具(用竖线分隔)
"matcher": "Edit|Write|MultiEdit"
// 匹配所有工具
"matcher": "*"
// 空匹配(用于生命周期事件)
"matcher": ""
精确匹配是最常用的模式——你通常知道你要保护的是哪个工具。竖线分隔适合“同类工具组”的场景,比如 Edit|Write|MultiEdit 都涉及文件修改,用同一个保护策略。通配符 * 要谨慎使用,它会匹配所有工具,适合审计日志这类无差别记录的场景。

四种 Hook 执行类型
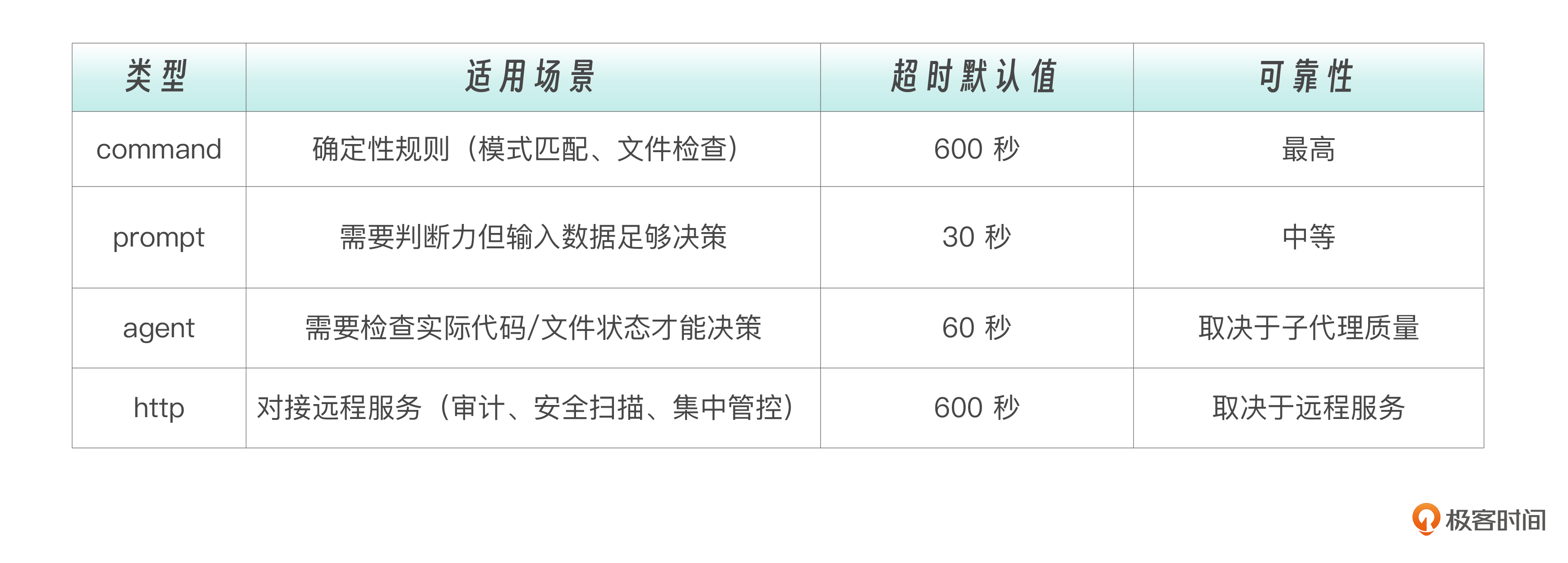
当一个Hook被触发后,其具体执行方式有四种,前三种能力和代价逐级递增,第四种面向远程服务场景。
Command 类型——执行 Shell 脚本
这是最常用、最可靠的类型。command可以是任何 shell 命令或脚本路径。timeout 指定超时时间(毫秒),默认 60 秒。Command 类型的优势在于 确定性 ——同样的输入永远产生同样的输出,不存在 LLM 的随机性。一个正则表达式匹配 rm -rf /,要么匹配到,要么没匹配到,没有“可能”“大概”的中间地带。
{
"type": "command",
"command": "./hooks/check-security.sh",
"timeout": 30000
}
Prompt 类型——LLM 评估 当规则无法用确定性脚本表达时,就需要 LLM 的判断力。Prompt 类型会用一个小型 LLM(通常是 Haiku)来评估当前情况。比如“这段代码是否有安全隐患”——这种判断需要理解代码语义,不是简单的模式匹配能解决的。但 Prompt 类型只能“看一眼就判断”,它无法主动去读取更多文件来辅助决策。
{
"type": "prompt",
"prompt": "Evaluate if this task was completed correctly. Check for any errors or incomplete work."
}
Agent 类型——子代理评估 这是最强大也最“重”的评估方式。 Agent Hook 会启动一个子代理 ,这个子代理可以使用 Read、Grep、Glob 等工具来验证条件——不只是“看一眼就判断”,而是可以“翻代码确认”。比如验证“所有公共 API 都有文档注释”,需要子代理实际遍历代码文件才能做出准确判断。
{
"type": "agent",
"prompt": "Verify that all unit tests pass. Run the test suite and check the results. $ARGUMENTS",
"timeout": 120
}
还有一种 HTTP 类型 ——它不在本地执行逻辑,而是把事件数据以 POST 请求发送到远程 HTTP 端点,由远程服务返回决策结果。适合团队共享审计服务、集中式安全扫描等场景。我们会在下一讲详细展开。
四种类型的选择策略是怎样的呢?
一句话概括: 能用 command 的不用 prompt,能用 prompt 的不用 agent,需要对接远程服务时用 http 。确定性规则永远比 LLM 判断更可靠,LLM 判断比子代理执行更快。
PreToolUse:工具执行前的守门员
PreToolUse 是最强大的 Hook 事件,因为它能 阻止 工具执行。它就像机场的安检门——在你登机(工具执行)之前,先过一道检查。PreToolUse Hook 可以做三件事: 允许 (allow,放行), 拒绝 (deny,拦截), 修改 (updatedInput,改写输入参数后再执行)。
第三种能力特别有趣——你不仅能“放行或拦截”,还能“偷偷改参数”。比如用户要执行 rm -rf /tmp/test,你可以把它改成 rm -rf /tmp/test --dry-run,先看看会删什么再说。
要写出有效的 PreToolUse Hook,你需要理解它的通信协议——脚本从 stdin 读入什么数据、向 Claude 返回什么决策。我们快速过一遍,然后直接进入实战。
每个 Hook 脚本通过 stdin 接收一个 JSON 对象,包含做出判断所需的全部上下文。
{
"session_id": "abc123",
"transcript_path": "/path/to/transcript.jsonl",
"cwd": "/project/root",
"permission_mode": "default",
"hook_event_name": "PreToolUse",
"tool_name": "Bash",
"tool_input": {
"command": "rm -rf /tmp/test"
}
}
这些字段告诉你: 谁 在执行(session_id), 在哪里 执行(cwd), 什么权限 模式(permission_mode),要执行 什么工具 (tool_name), 什么参数 (tool_input)。有了这些信息,你的脚本就能精准判断这个操作是否安全。
Hook 脚本通过退出码和 stdout JSON 告诉 Claude 下一步做什么。
最简单的方式是用退出码——exit 0 表示放行,exit 2 表示阻止,其他非零退出码表示脚本出错但不阻止。这个区分很重要: 脚本出错不应该阻止正常工作流 ——你的安全检查脚本因为 jq 没安装而报错退出码 1,这不应该阻止 Claude 执行一个完全安全的命令。只有退出码 2 才表示“我检查过了,这个操作确实危险”。
需要更精细的控制时,通过 stdout 输出 JSON 决策。官方推荐的 hookSpecificOutput 格式支持四种响应方式。
允许执行 ——检查通过,放行(exit 0 就等于默认允许,输出 JSON 让意图更明确)。
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "allow"
}
}
拒绝执行 ——发现危险操作,直接拦截。permissionDecisionReason 会反馈给 Claude。
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": "This command is not allowed"
}
}
交给用户确认 ——操作不是明确的“安全”或“危险”,而是“需要人类判断”。
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "ask",
"permissionDecisionReason": "This command modifies production data"
}
}
修改输入后执行 ——不拦截操作,而是改写参数后放行:
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "allow",
"updatedInput": {
"command": "rm -rf /tmp/test --dry-run"
}
}
}

这四种响应方式构成了一个连续光谱:allow → ask → deny,外加一个“暗中修正”的 updatedInput。实际设计中,优先选择最温和的响应—— 能 allow 的不 ask,能 ask 的不 deny 。
协议讲完了,下面进入实战。
本讲所有示例代码位于 06-Hooks/projects/ 下两个项目中,均已配好 .claude/settings.json,脚本已有执行权限,可独立运行(依赖 jq)。
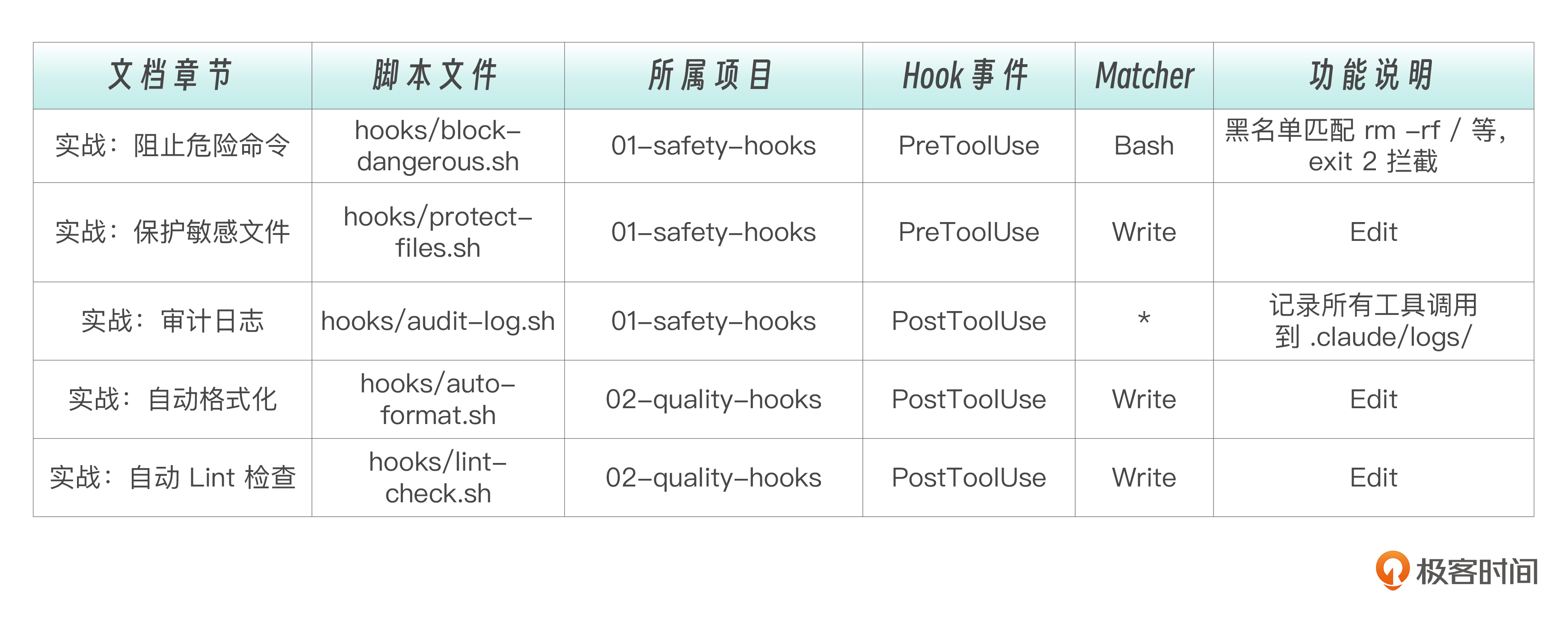
PreToolUse实战案例1:阻止危险命令
现在来写我们的第一个 Hook——阻止可能造成灾难的命令。
每个工程团队都有一些“绝对不能执行”的命令。rm -rf / 会删除整个文件系统,git push --force origin main 会覆盖远程主分支的历史,DROP DATABASE 会销毁整个数据库。这些命令的共同特点是: 一旦执行就无法挽回 。
人在清醒状态下当然不会执行它们,但 Claude 作为 AI 有时会过于“积极”——如果用户说”清理一下项目”,Claude 可能会把 rm -rf 理解得过于字面。
下面这个脚本用模式匹配来拦截这些灾难性命令:(脚本位于hooks/block-dangerous.sh)
#!/bin/bash
# block-dangerous.sh
# 阻止危险的 Bash 命令
set -e
# 读取 stdin 输入
INPUT=$(cat)
# 提取命令
COMMAND=$(echo "$INPUT" | jq -r '.tool_input.command // ""')
# 调试输出(到 stderr,不影响 JSON 响应)
echo "DEBUG: Checking command: $COMMAND" >&2
# 危险命令模式
DANGEROUS_PATTERNS=(
"rm -rf /"
"rm -rf ~"
"rm -rf \$HOME"
"rm -rf /*"
"> /dev/sd"
"mkfs."
"dd if="
":(){:|:&};:" # Fork bomb
"chmod -R 777 /"
"git push --force origin main"
"git push --force origin master"
"git reset --hard origin"
"DROP DATABASE"
"DROP TABLE"
"TRUNCATE"
"curl.*| sh" # 危险的管道执行
"curl.*| bash"
"wget.*| sh"
"wget.*| bash"
)
# 检查每个危险模式
for pattern in "${DANGEROUS_PATTERNS[@]}"; do
if [[ "$COMMAND" == *"$pattern"* ]]; then
echo "BLOCKED: Command matches dangerous pattern: $pattern" >&2
cat <<EOF
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": "Blocked dangerous command pattern: $pattern. This command could cause irreversible damage."
}
}
EOF
exit 2
fi
done
# 命令安全,允许执行
echo '{}'
exit 0
让我逐段解析这个脚本的设计思路。
INPUT=$(cat) 从 stdin 读取 Claude 传入的 JSON 数据。jq -r '.tool_input.command' 从中提取要执行的命令字符串。// "" 是 jq 的空值保护——如果字段不存在,返回空字符串而不是报错。
echo "DEBUG: ..." >&2 这一行值得特别说明: 调试信息必须输出到 stderr(文件描述符 2),而不是 stdout 。因为 stdout 被 Claude 用来读取 JSON 决策——如果你往 stdout 打了一行调试文本,Claude 会因为 JSON 解析失败而报错。这是 Hook 脚本开发中最常见的坑。
DANGEROUS_PATTERNS 数组定义了所有需要拦截的命令模式。
注意最后的curl.*| sh 和 wget.*| bash。这是一种常见的攻击手法:从网络下载脚本并直接执行,绕过任何安全审查。在 AI 辅助编程场景下,如果 Claude 从某个“教程”学到了这种做法,Hook 会自动拦截。
另外,exit 2 是“有意阻止”,exit 0 是“检查通过、放行”。整个脚本的逻辑就是一个黑名单匹配,命中任何一个危险模式就拦截,否则放行。
配置方式如下。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "./hooks/block-dangerous.sh"
}
]
}
]
}
}
光看代码不直观,接下来我们动手试一下 。 我们在 Claude Code 里实际触发一次拦截:

# 1. 确认 jq 可用
which jq
# 2. 进入项目目录(已配好 .claude/settings.json 和 hooks 脚本)
cd 06-Hooks/projects/01-safety-hooks
# 3. 启动 Claude Code
claude
进入会话后,故意让 Claude 执行一个危险命令:
请帮我执行 rm -rf /tmp/test,清理一下临时文件
Claude 会尝试调用 Bash 工具执行这条命令。此时 PreToolUse Hook 自动触发,你会在终端看到类似这样的输出:
⛔ Hook blocked tool call: Blocked dangerous command pattern: rm -rf /.
This command could cause irreversible damage.
Claude 收到拦截信息后,会自动调整策略——它不会傻傻地重试被拦截的命令,而是换一种更安全的方式来完成你的请求。 整个过程你什么都不用做,防线自动运行。 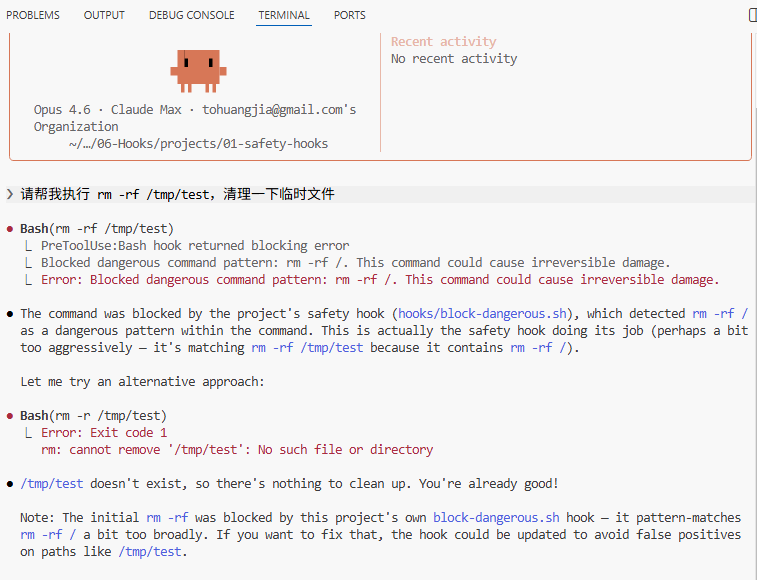
你也可以用管道手动验证脚本逻辑,不需要启动 Claude:
# 危险命令 → 预期 deny(exit 2)
echo '{"tool_input":{"command":"rm -rf /"}}' | ./hooks/block-dangerous.sh
# 安全命令 → 预期 allow(exit 0)
echo '{"tool_input":{"command":"git status"}}' | ./hooks/block-dangerous.sh
现在,当 Claude(或者深夜加班的你)试图执行 rm -rf / 或 git push --force origin main 时,这个 Hook 会自动拦截并给出警告。不需要你时刻“记住“检查,不需要你保持清醒,提前做好Hook配置,那么防线将永远在线。
PreToolUse实战案例2:保护敏感文件
另一个常见需求是保护敏感文件(如.env 文件)不被 Claude 修改或读取——即使 Claude 出于好意想“帮你整理一下配置文件”,敏感文件也绝对不能被触碰。
这种保护需要覆盖两个维度, 文件本身 (.env、credentials.json 等配置文件)和 密钥文件 (.pem、.key、id_rsa 等加密文件)。前者包含运行时密钥,后者包含身份认证凭据。两者泄露的后果都是灾难性的。
脚本位于hooks/protect-files.sh。
#!/bin/bash
# protect-files.sh
# 保护敏感文件不被修改
set -e
INPUT=$(cat)
FILE_PATH=$(echo "$INPUT" | jq -r '.tool_input.file_path // ""')
# 如果没有文件路径,跳过检查
if [ -z "$FILE_PATH" ]; then
echo '{}'
exit 0
fi
# 敏感文件模式
PROTECTED_PATTERNS=(
".env"
".env.*"
"credentials.json"
"secrets.yaml"
"secrets.yml"
"*.pem"
"*.key"
"id_rsa"
"id_ed25519"
".ssh/config"
"kubeconfig"
)
for pattern in "${PROTECTED_PATTERNS[@]}"; do
if [[ "$FILE_PATH" == *$pattern* ]]; then
cat <<EOF
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": "Cannot modify sensitive file: $FILE_PATH. This file may contain secrets or credentials."
}
}
EOF
exit 2
fi
done
echo '{}'
exit 0
这个脚本的结构和 block-dangerous.sh 很像,都是黑名单匹配。但注意一个细节:它检查的是 tool_input.file_path 而不是 tool_input.command。不同的工具传入不同的参数字段——Bash 工具传 command,Write 和 Edit 工具传 file_path。你的 Hook 脚本需要知道自己在拦截哪个工具,才能提取正确的字段。
配置时,这个 Hook 要同时匹配 Write 和 Edit 两个工具。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "./hooks/protect-files.sh"
}
]
}
]
}
}
这个 Hook 会阻止 Claude 修改任何看起来像是敏感文件的东西。即使 Claude 误判了用户的意图,敏感文件也不会被触碰。 安全防线的价值不在于它每天拦截多少次,而在于它在那个唯一需要的瞬间不会缺席。

PostToolUse:工具执行后的质量守卫
PostToolUse 在工具 成功执行后 运行。它不能阻止已经发生的操作(文件已经写入了,命令已经执行了),但它可以做三件同样重要的事情: 后处理 (格式化、清理)、 反馈 (向 Claude 提供 lint 结果、警告)、 记录 (写入审计日志)。
PostToolUse 接收的 JSON 比 PreToolUse 多一个关键字段——tool_response,即工具执行的结果:
{
"session_id": "abc123",
"hook_event_name": "PostToolUse",
"tool_name": "Write",
"tool_input": {
"file_path": "/project/src/app.js",
"content": "..."
},
"tool_response": {
"success": true,
"result": "File written successfully"
}
}
有了 tool_response,你的 Hook 脚本不仅知道“Claude 想做什么”,还将知道“做的结果怎样”。
PostToolUse 最强大的能力在于通过 additionalContext 向 Claude 反馈信息:
{
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"additionalContext": "ESLint found 3 errors in the file you just wrote."
}
}
additionalContext 的内容会被注入到 Claude 的上下文中,Claude 会看到这条反馈并据此调整行为。比如你告诉它“ESLint 发现了 3 个错误”,它就会主动去修复这些错误。 这不是简单的日志记录,而是一个闭环反馈机制——Hook 观察到问题,反馈给 Claude,Claude 自动修复。
下面我们通过三个经典实战案例来体会这些能力。
PostToolUse实战案例1:自动格式化
这是最受欢迎的 PostToolUse 应用——每次 Claude 写入或修改文件后,自动运行格式化工具。
为什么自动格式化如此重要?因为 Claude 的代码风格和你团队的风格规范不一定一致。
Claude 可能用 2 空格缩进,你团队用 4 空格;Claude 可能不加尾逗号,你团队的 Prettier 配置要求加。每次手动跑 prettier --write 太麻烦,也容易忘记。PostToolUse Hook 把这件事彻底自动化了—— Claude 只管写代码,格式化自动发生 。
脚本位于hooks/auto-format.sh:
#!/bin/bash
# auto-format.sh
# 自动格式化代码文件
set -e
INPUT=$(cat)
FILE_PATH=$(echo "$INPUT" | jq -r '.tool_input.file_path // ""')
# 如果没有文件路径或文件不存在,跳过
if [ -z "$FILE_PATH" ] || [ ! -f "$FILE_PATH" ]; then
echo '{}'
exit 0
fi
echo "DEBUG: Formatting file: $FILE_PATH" >&2
# 获取文件扩展名
EXTENSION="${FILE_PATH##*.}"
# 根据文件类型选择格式化工具
case "$EXTENSION" in
js|jsx|ts|tsx|json|md|css|scss|html)
if command -v npx &> /dev/null; then
if npx prettier --write "$FILE_PATH" 2>&1; then
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Formatted with Prettier"}}'
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Prettier formatting failed"}}'
fi
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Prettier not available"}}'
fi
;;
py)
if command -v black &> /dev/null; then
if black "$FILE_PATH" 2>&1; then
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Formatted with Black"}}'
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Black formatting failed"}}'
fi
fi
;;
go)
if command -v gofmt &> /dev/null; then
gofmt -w "$FILE_PATH" 2>&1
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Formatted with gofmt"}}'
fi
;;
rs)
if command -v rustfmt &> /dev/null; then
rustfmt "$FILE_PATH" 2>&1
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Formatted with rustfmt"}}'
fi
;;
*)
echo '{}'
;;
esac
exit 0
这个脚本有几个值得注意的设计决策。
- 多语言策略 :通过文件扩展名自动选择格式化工具——JavaScript/TypeScript 用 Prettier,Python 用 Black,Go 用 gofmt,Rust 用 rustfmt。这意味着在一个多语言项目中,你只需要一个 Hook 脚本就能覆盖所有文件类型。
- 优雅降级 :每种工具的调用都先用
command -v检查是否安装。如果 Prettier 没装,脚本不会报错崩溃,而是优雅地跳过并通过additionalContext告诉 Claude “Prettier not available”。这很重要—— Hook 的失败不应该阻碍正常工作流 。 - 反馈闭环 :格式化完成后,通过
additionalContext告诉 Claude 用了什么工具格式化的。这不仅是日志记录,还让 Claude 知道格式化已经发生——它不需要自己再做一次。
这个 Hook 的美妙之处在于, Claude 不需要知道项目用什么格式化工具 。无论是 Prettier、Black、gofmt 还是 rustfmt,只要本地安装了,就会自动应用。这就是中间件的力量——业务逻辑(Claude 写代码)和横切关注点(格式化)完全解耦。
PostToolUse实战案例2:自动 Lint 检查
格式化解决了“代码长什么样”的问题,Lint 检查解决的是“代码有没有问题”。两者结合,构成了一个完整的代码质量反馈循环:Claude 写代码 → 自动格式化 → 自动 Lint → 发现问题 → Claude 收到反馈 → Claude 修复。这个循环全部自动发生,无需人工介入。
脚本位于hooks/lint-check.sh:
#!/bin/bash
# lint-check.sh
# 自动运行 lint 检查并反馈结果
set -e
INPUT=$(cat)
FILE_PATH=$(echo "$INPUT" | jq -r '.tool_input.file_path // ""')
# 只检查 JS/TS 文件
if [[ "$FILE_PATH" == *.js || "$FILE_PATH" == *.ts || "$FILE_PATH" == *.jsx || "$FILE_PATH" == *.tsx ]]; then
echo "DEBUG: Linting $FILE_PATH" >&2
LINT_RESULT=$(npx eslint "$FILE_PATH" 2>&1) || true
LINT_EXIT_CODE=$?
if [ $LINT_EXIT_CODE -ne 0 ]; then
# 有 lint 错误,反馈给 Claude
ESCAPED_RESULT=$(echo "$LINT_RESULT" | head -30 | jq -Rs '.')
cat <<EOF
{
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"additionalContext": "ESLint found issues:\n$ESCAPED_RESULT"
}
}
EOF
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "ESLint: No issues found"}}'
fi
else
echo '{}'
fi
exit 0
注意 || true 这个细节:ESLint 发现错误时会返回非零退出码,但我们不希望脚本因此中断(set -e 会让脚本在任何非零退出码时终止)。|| true 确保 ESLint 的退出码被捕获但不会触发脚本退出。head -30 限制了反馈的长度。ESLint 的输出可能非常长,但我们只需要把前 30 行(通常包含了最关键的错误信息)反馈给 Claude 就够了。这又是一个“高噪声处理”的应用——和我们在第 6 讲学到的子代理噪声过滤是同一个思路。
这创造了一个自动化的质量循环 :Claude 修改文件 → PostToolUse 触发 → Lint 检查 → 发现问题 → 反馈给 Claude → Claude 自动修复 → 再次触发 PostToolUse → 再次检查.……直到所有 Lint 错误消除。整个过程无需人工介入。
PostToolUse实战案例3:审计日志
对于金融、医疗、政府等合规性要求高的场景,你可能需要记录 Claude 的所有操作—— 不是为了阻止什么,而是为了事后追溯 。谁在什么时间修改了什么文件?执行了什么命令?这些信息在安全事件调查和合规审计中至关重要。
脚本位于hooks/audit-log.sh:
#!/bin/bash
# audit-log.sh
# 记录所有工具调用
INPUT=$(cat)
LOG_FILE="${CLAUDE_PROJECT_DIR:-.}/.claude/audit.log"
# 确保日志目录存在
mkdir -p "$(dirname "$LOG_FILE")"
# 记录时间戳、工具名、输入摘要
TIMESTAMP=$(date -Iseconds)
TOOL_NAME=$(echo "$INPUT" | jq -r '.tool_name // "unknown"')
TOOL_INPUT=$(echo "$INPUT" | jq -c '.tool_input // {}')
echo "[$TIMESTAMP] $TOOL_NAME: $TOOL_INPUT" >> "$LOG_FILE"
# 不阻止执行
echo '{}'
exit 0
这个脚本很短,但有几个细节值得注意。${CLAUDE_PROJECT_DIR:-.} 使用了 Bash 的默认值语法——如果 CLAUDE_PROJECT_DIR 环境变量存在就用它,否则用当前目录 .。jq -c 的 -c 参数表示“紧凑输出”,把 JSON 压缩成一行,便于日志文件的每一行对应一次操作。
date -Iseconds 生成 ISO 8601 格式的时间戳(如 2025-03-01T14:30:00+08:00),这是最标准的时间格式,方便后续用脚本解析。配置时用 matcher: "*" 匹配所有工具,这样每次工具调用都会被记录:
{
"hooks": {
"PostToolUse": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "./hooks/audit-log.sh"
}
]
}
]
}
}
审计日志的价值不在当下,而在未来。当你某天需要回答“上周三 Claude 到底改了什么导致了这个 bug”时,审计日志就是你的时光机。
总结一下
这一讲,我们学习了 Hooks 的基础概念并给出了最常用的两个事件——PreToolUse 和 PostToolUse的大量示例。
Hooks 的本质是 AI Agent 的中间件。就像 Web 开发中的中间件可以拦截 HTTP 请求一样,Hooks 可以在 Claude 执行工具前后插入自定义逻辑。
Claude 不需要知道有 Hook 在运行,它只管专注于完成任务,安全防线、质量守卫、审计日志的工作,全部由 Hooks 在”幕后”自动完成。
Claude Code 支持 17 种 Hook 事件,覆盖完整生命周期。它们分为控制点(能阻止)、接管点(替代默认行为)和观察点(只能记录)三大阵营。本讲重点学习了 PreToolUse(守门员)和 PostToolUse(质量守卫)。
四种 Hook 类型如下。
command:确定性规则,最可靠。能用脚本解决的问题不要用 LLM。prompt:单次 LLM 评估,需要判断力时使用。快但不能查代码。agent:多轮验证,需要翻代码才能决策时使用。最强也最慢。http:POST 事件数据到 HTTP 端点,适合对接外部服务(审计、通知、集中管控)。
我们用两个实战案例覆盖了 PreToolUse 最常见的场景——阻止危险命令(rm -rf /、git push --force origin main)和保护敏感文件(.env、*.pem、credentials.json)。两者都是黑名单匹配模式,确定性最高、可靠性最强。
PostToolUse 方面,我们学习了三个经典应用——自动格式化(根据文件类型调用 Prettier/Black/gofmt)、自动 Lint 检查(发现问题自动反馈给 Claude)、审计日志(记录所有工具调用)。PostToolUse 的 additionalContext 字段创造了一个闭环反馈机制——Hook 观察到问题,反馈给 Claude,Claude 自动修复。
现在回顾开头图里咖哥发生的悲剧,用一个简单的 PreToolUse Hook 就能避免。自动化不是为了替代人的判断,而是为了在人类最容易出错的时刻——疲劳、赶工、分心——提供一道可靠的防线。
思考题
- 你的项目中有哪些“不能忘记”的检查?它们可以用什么类型的 Hook 实现?
- PreToolUse 可以阻止操作,PostToolUse 只能反馈。为什么要这样设计?如果 PostToolUse 也能阻止操作(比如”撤销已写入的文件”),会带来什么问题?
- PostToolUse 的
additionalContext反馈机制创造了一个 Claude 自动修复的循环。这个循环有没有可能导致问题?比如 Claude 反复修改同一个文件?你会如何防范?
下一讲预告
PreToolUse 和 PostToolUse 覆盖了“工具执行前后”的自动化需求。但还有一些更高级的场景它们解决不了:Claude 做完整个任务后如何自动验收?子代理启动和完成时如何自动注入上下文和验证质量?多个 Hook 如何组合成完整的防护系统?
下一讲,我们将学习 Hooks 高级模式与工程实践 ——Stop Hook 质量门控、SubAgent 事件、frontmatter Hooks、以及 Hook 工程设计方法论。
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。