**释题:** 触类旁通。Skills 的 Description 不只是说明文档,而是触发器——我们要掌握让 Claude 自动发现并逐渐加载技能的关键写法。这是从“教”到“学”的转变。你好,我是黄佳。上一部分我们深入研究了子代理,学会了如何把“一个大脑”拆成多个“专职岗位”。现在,让我们进入一个更有趣的领域—— **Skills(技能系统)** 。
从第一性原理来理解什么是Skills
在真实的工程团队里,很少有人能够把所有规范背下来。
代码风格指南十几页,Git 提交规范三四种类型,API 设计有版本约定,安全审查有检查清单,部署流程有风险控制条款……这些规则并不复杂,但数量一多,就不可能长期驻留在脑中。人类工程师的做法很简单:需要时再查阅。
如果我们把 Claude 当作真正的工程助手,它也会面临同样的问题。最直接的做法,是把所有团队规范写进 CLAUDE.md,让模型每次对话都读取这些内容。短期看这是可行的。但当知识规模扩大到几十页甚至上百页时,问题就出现了——每一次对话都在为“可能用不到的知识”支付上下文成本。这不仅消耗 tokens,更重要的是,它会稀释模型的注意力。真正需要用到的规则,反而淹没在冗余信息里。
这正是 Skills 出现的背景。
Skills 并不是简单的“能力扩展机制”,它本质上是一种按需加载的认知结构。与其把所有知识常驻在上下文中,不如把它们封装成可独立触发的能力单元。当模型判断当前任务涉及某个特定领域时,再加载对应的知识与操作流程。
因此,我们可以给 Skills 一个更精确的定义: Skills 是一种可被语义触发的能力包,它包含领域知识、执行步骤、输出规范与约束条件,并在需要时渐进式加载到主 Agent 的认知空间中。
如果我们把 Agent 生态整体展开来看,会发现 Skills 并不是孤立存在的。Agent 生态中有四大支柱,每个都解决了一个根本性问题。
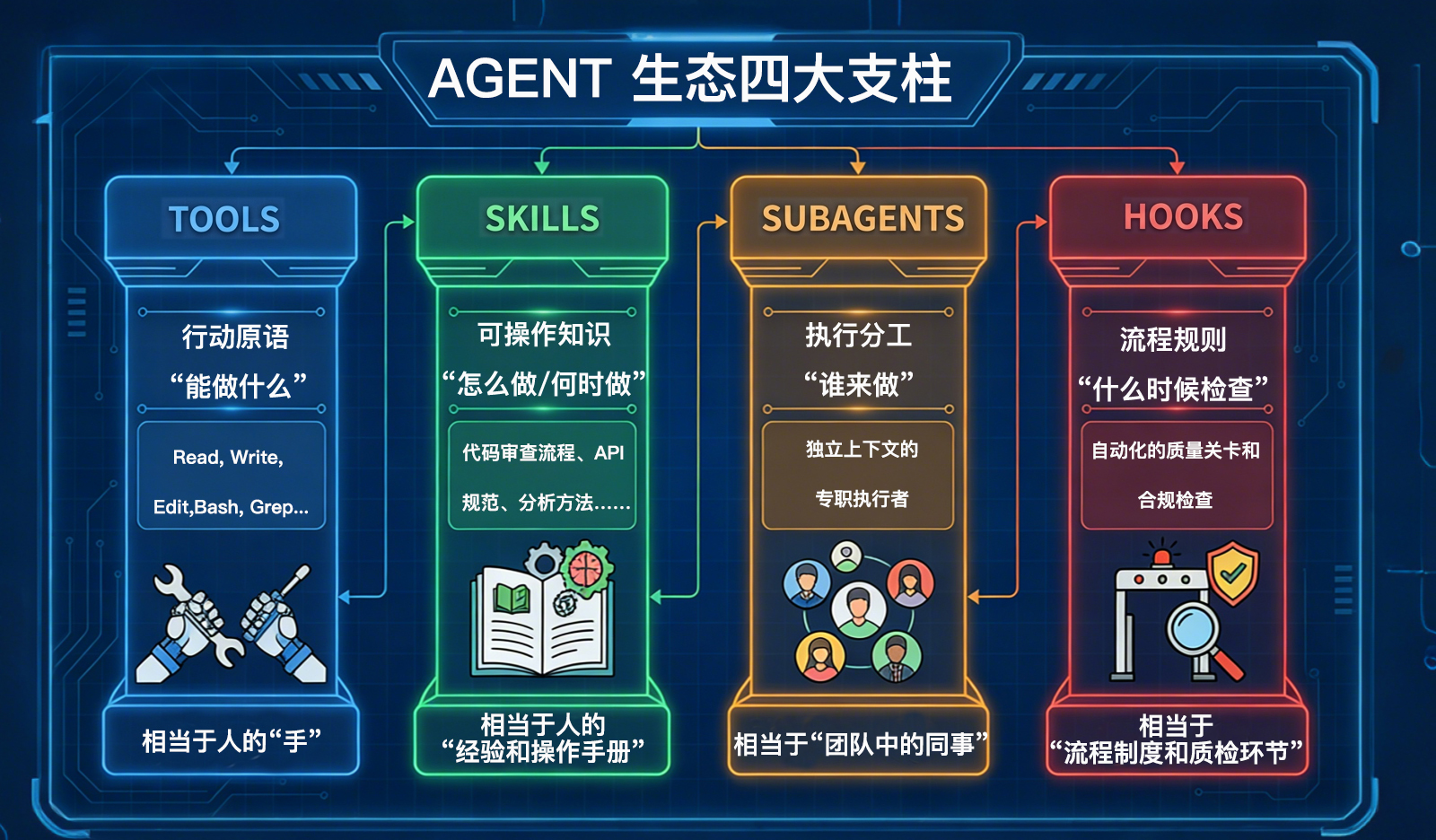
- Tools 是行动原语 。它回答的是 能做什么 。读文件、改代码、执行 Bash 命令……这些是操作层面的能力,类似人的双手。
- SubAgents 是执行分工 。它回答的是 谁来做 。当任务复杂到需要独立上下文时,子代理承担专职职责,类似团队中的同事。
- Hooks 是流程规则 。它回答的是 什么时候检查 。它们在关键节点自动触发质量校验或合规约束,类似企业中的质检流程。
- 而 Skills 回答的,是另外一个非常关键的问题:“ 怎么做,以及何时做 ”,它不是工具,也不是分工机制。它是一种 可操作知识结构 。
Skills 解决的核心问题是,在有限的上下文窗口中,让 Agent 在正确的时刻拥有正确的领域知识。
这不是工具问题(Tools 回答“能做什么”),也不是分工问题(SubAgents 回答“谁来做”),而是 认知问题 ——Agent 需要知道特定领域的规范、流程、模式,才能做出正确决策。
Skills 的核心生态位——可操作知识
很多人会把 Skills 理解成“结构化文档”。但可操作知识与被动文档之间,存在本质区别。
一份 API 设计指南放在 Wiki 上,是静态文本。它不包含触发条件,不定义执行流程,不规定输出结构,也不会自动校验质量。它等待人去阅读。
而一个 Skill,则是一段具备语义入口的标准操作程序。它通过 description 告诉模型:在什么情况下应该加载这项能力。它在正文中定义执行步骤,将抽象原则转化为可执行流程。它通过模板约束输出格式,确保结果标准化。它可以限制可调用工具的范围,防止越权操作。它甚至可以通过 hooks 在完成后自动执行验证逻辑。
当我们把文档封装为 Skill,它就不再是参考资料,而成为一种可被调用的行为模式。从工程视角看,这是对上下文资源的优化;但从系统设计视角看,这是一种更深层的变化。
过去的软件体系中,调度权始终掌握在人类手中。工程师写 Prompt、编排 Workflow、定义调用顺序。模型只是执行者。路径在设计时就被固定下来。但当知识规模持续扩大、场景组合持续增长时,这种“人预编排一切”的模式开始失效。我们无法穷举所有路径,也无法为每一种场景写出完整流程。
Skills 的真正突破点,在于它把能力的“语义定义权”交给模型。
人不再编排具体执行路径,而是定义能力的边界与含义。模型根据 description 理解能力语义,并在运行时决定是否加载、何时加载。这看似只是增加了一个字段,却完成了一次范式跃迁。我们从“人调度模型”,走向“模型调度能力”。

正因为“模型调度能力”和“可操作知识”的重要性,Skills已经逐渐脱离了Claude的语境,成了Agent生态中的通用概念。“技能化”思路正在从 Claude 系统扩展到其他智能体平台,以及 AI 赋能的工程工具中。在Claude发布的 Agent Skills 公用仓库中,集成了大量可复用的能力。Coze也推出了技能商店,为Coze智能体生态提供即插即用的能力组件。
企业本体论视角:Skills 是组织的 SOP 体系
当这种“可操作知识”机制扩展到企业层面,它的意义会更加清晰。
如果把 Claude Code 的技术栈映射到企业组织结构,我们会发现一种高度对称的关系。Tools 对应员工的操作工具;SubAgents 对应岗位分工;Hooks 对应质量与合规流程;CLAUDE.md 类似企业文化与通用规章;MCP Servers 像外部合作伙伴;Plugins 是对外打包的解决方案。
而 Skills,正是企业的 SOP 体系。
一个成熟的企业不会要求员工背诵全部操作手册。相反,它建立标准操作程序,在具体任务发生时按需查阅,并按照步骤执行,输出标准化结果。当新员工进行代码审查时,他不会即兴发挥。他会参考《代码审查 SOP》,按步骤检查,最后输出符合模板的报告。
Claude 在加载 code-review Skill 时,所做的事情,本质上是同一个过程。从这个角度看,Skills 不再只是技术机制,而是一种企业经验的结构化表达方式。
当组织的“做事方式”被封装为可语义调用的能力单元,经验就不再依附于老员工的记忆,也不再散落在文档系统中。它变成模型可以理解、选择和继承的结构。
对于企业来说, 把专业流程、领域知识和行动判断封装成可复用的能力单元,然后让智能体按需加载和调用,这是一种让通用模型具备专业化、按需调用能力的通用设计模式 。类似 Skills 的模块化能力已经被用于数据分析、校验、报告生成等任务,把自然语言指令转化成结构化的专业工作流;也有技术方案将企业组件库、开发规范等封装成“技能包”,让模型自动发现、理解并正确应用这些业务能力。

这就是为什么 Skills 在 Agent 时代具有特殊地位。它既不是单纯的工具层扩展,也不是应用层封装。它是认知层的调度结构,是企业本体论在模型世界中的映射。

在企业中,本体论决定了什么叫“产品”、什么叫“客户”、什么叫“流程”、什么叫“风险”。它定义了组织共享的语义边界。没有这层语义结构,所有规则都会碎片化,所有流程都会各自为政。
当我们把这个视角带入 Agent 系统时,会发现同样的问题:模型需要的不仅是能力,更需要知道这些能力存在于怎样的“世界结构”中。这正是图中第四层——Enterprise Ontology——所表达的含义。
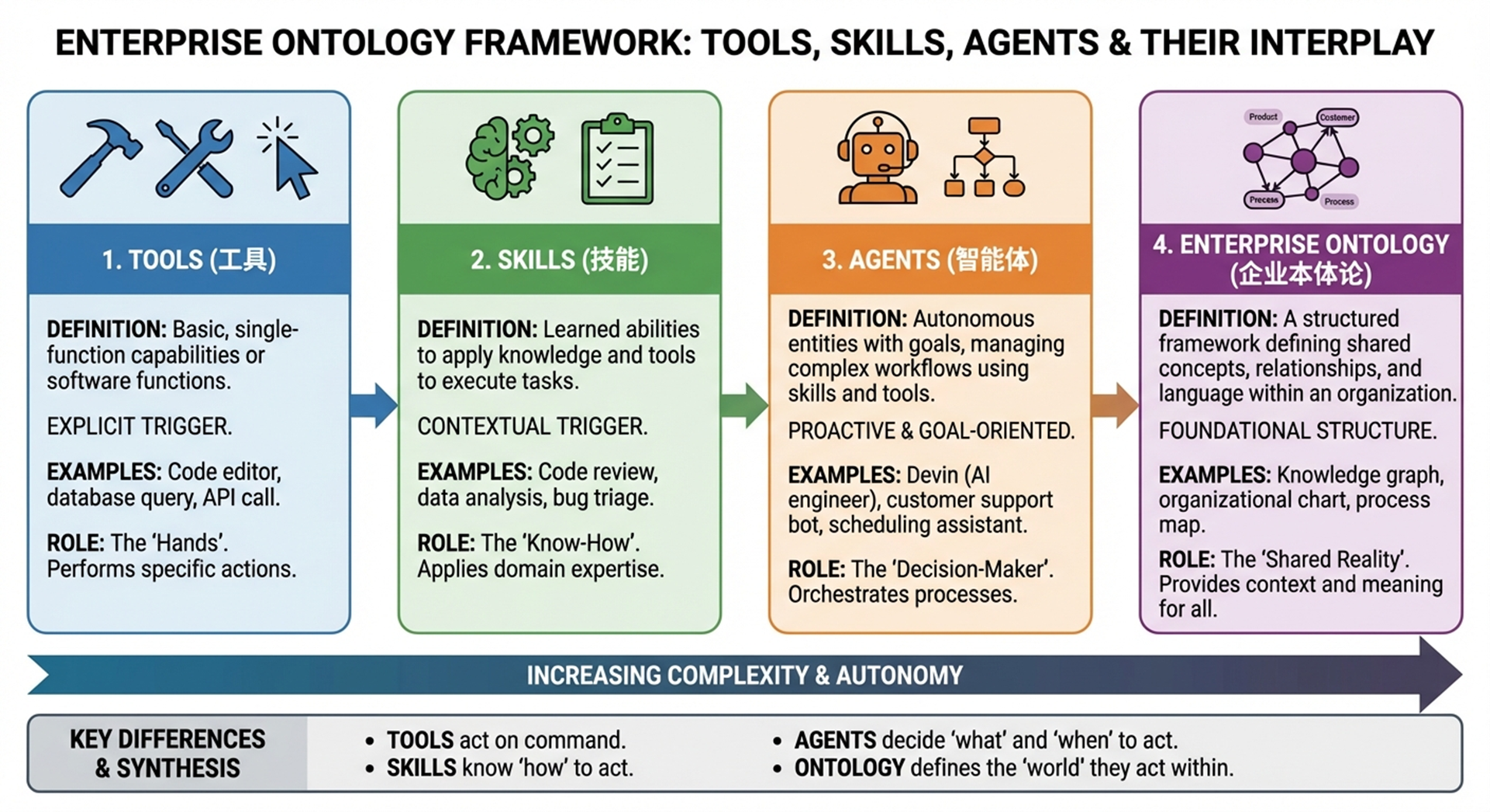
上面这张图真正希望你关注的,不是四个并列组件,而是四种不同层级的存在方式。
- 工具回答“能做什么”。
- 技能回答“该怎么做”。
- 智能体回答“什么时候做什么,以及由谁来做”。
- 本体论回答“在什么世界里做”。
当 Skills 被放入这样的结构中,我们才能看清它的真正位置。它是连接“行动能力”与“语义世界”的中间层。它将企业本体中的概念与规范,转译为可执行的行为模式。
在有限的上下文窗口里, 组织的做事方式第一次获得了结构化存在的形式 。这,才是 Skills 的真正意义。
深入理解Skill 触发机制
好,上面花了好长的篇幅介绍Skills在整个Agent生态中的独特位置。下面书归正传,回到Claude Code本身,继续讲Skills的具体实现细节。我们先来深入的理解一下Claude Code是如何触发一个相关Skill的。
在Claude Code中,Skills 默认情况下支持两种触发方式。
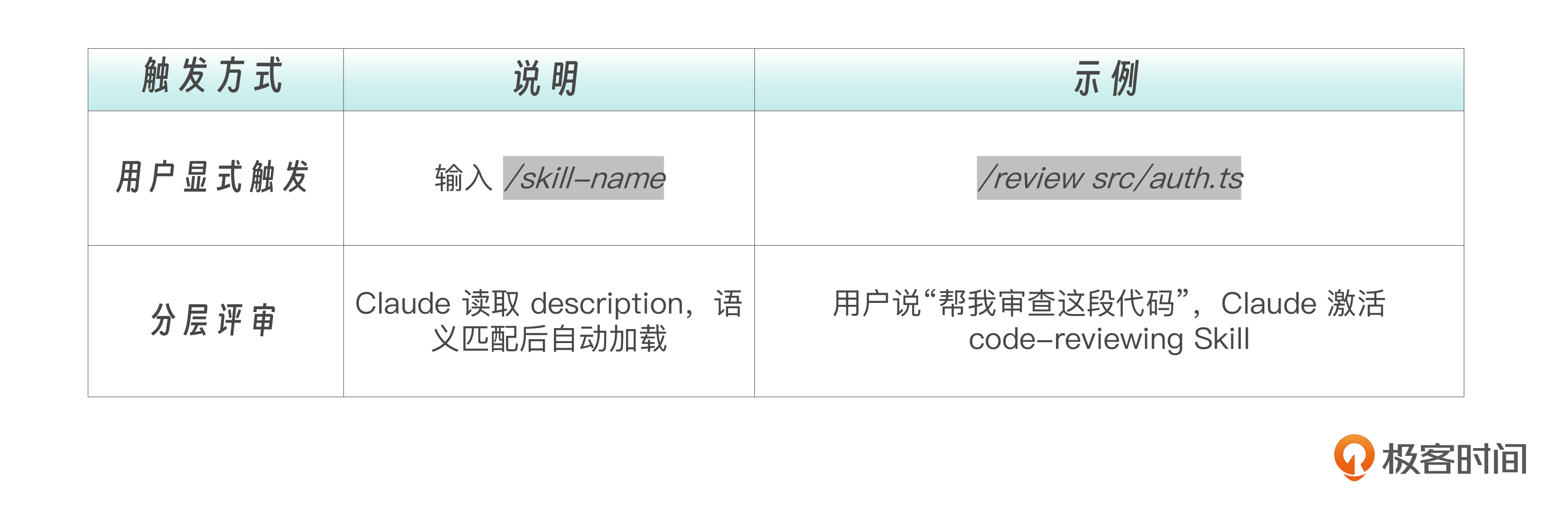
这是 Skills 最重要的设计特性—— 同一个 Skill 既可以作为斜杠命令使用,也可以让 Claude 自动判断何时需要 。
为什么要这样设计? 用户有时知道自己要什么(/review),有时只是描述需求(“帮我看看代码“)。Skills 的双向触发机制让两种场景都能被满足,同时保持能力定义的统一。
举个例子:

两种方式调用的是同一个 Skill,执行的是同样的指令。
和Sub-Agents类似,Skills 的触发机制 靠 LLM 语义推理,而非精确匹配 。Claude 读取所有 Skills 的 description,通过语义理解判断当前对话是否匹配某个 Skill。
当用户发送消息时,Claude 的处理流程如下图所示:
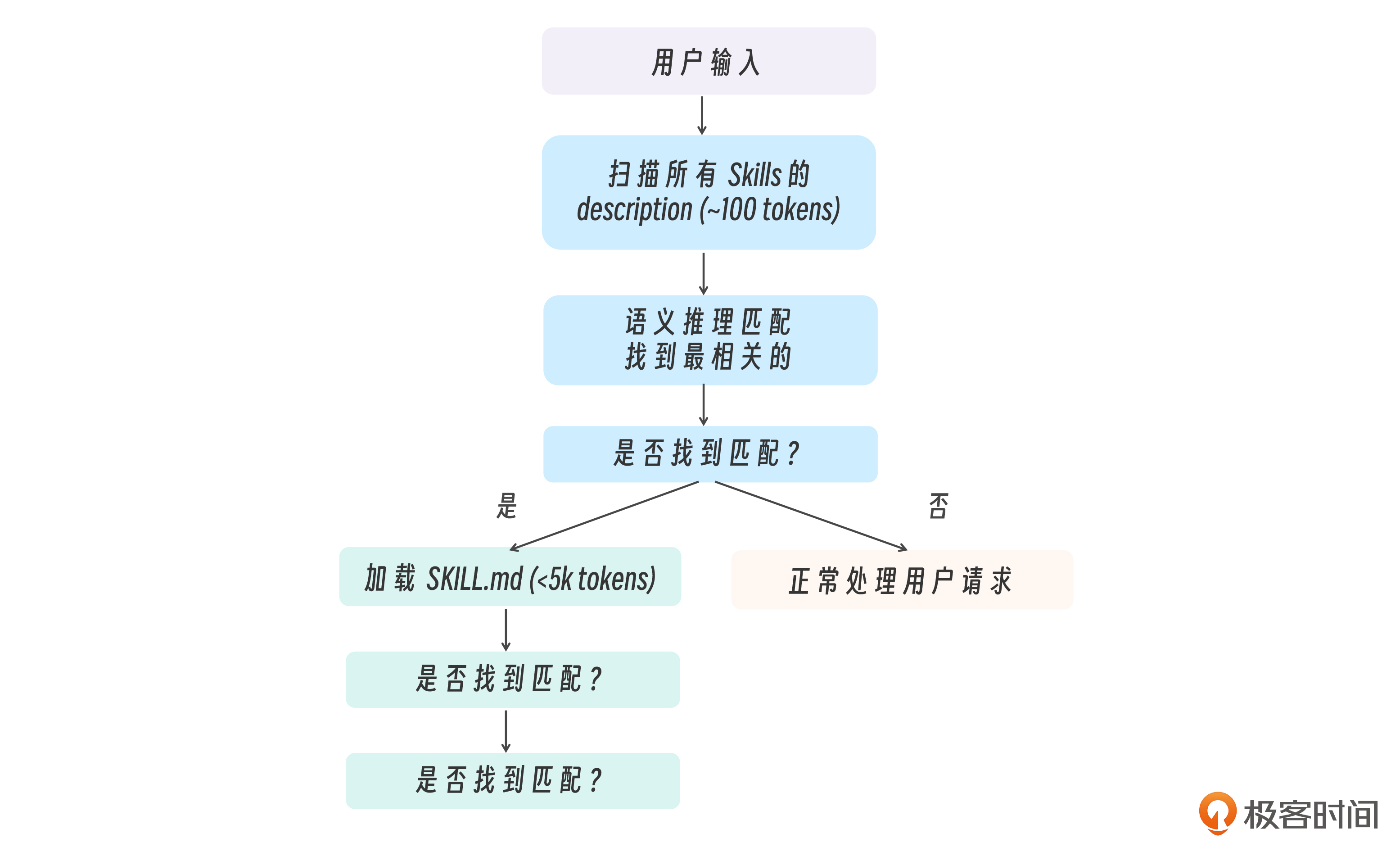
假设你有 5 个 Skills,每个 SKILL.md 约 1000 tokens。

这里我们注意到, 渐进式加载时Token的节省比例高达78% ~ 98%。 这就是为什么 Skills 采用“渐进式披露”而非“一次性加载”。
当用户请求可能匹配多个 Skills 时,Claude 会:
- 评估每个 Skill 的 description 与用户请求的相关性。
- 选择 最相关 的那个。
- 如果不确定,可能会询问用户或使用通用方式处理。
之前讲过 Skill 有两种触发方式,理解这一点对 Skill 设计和触发过程也很重要。

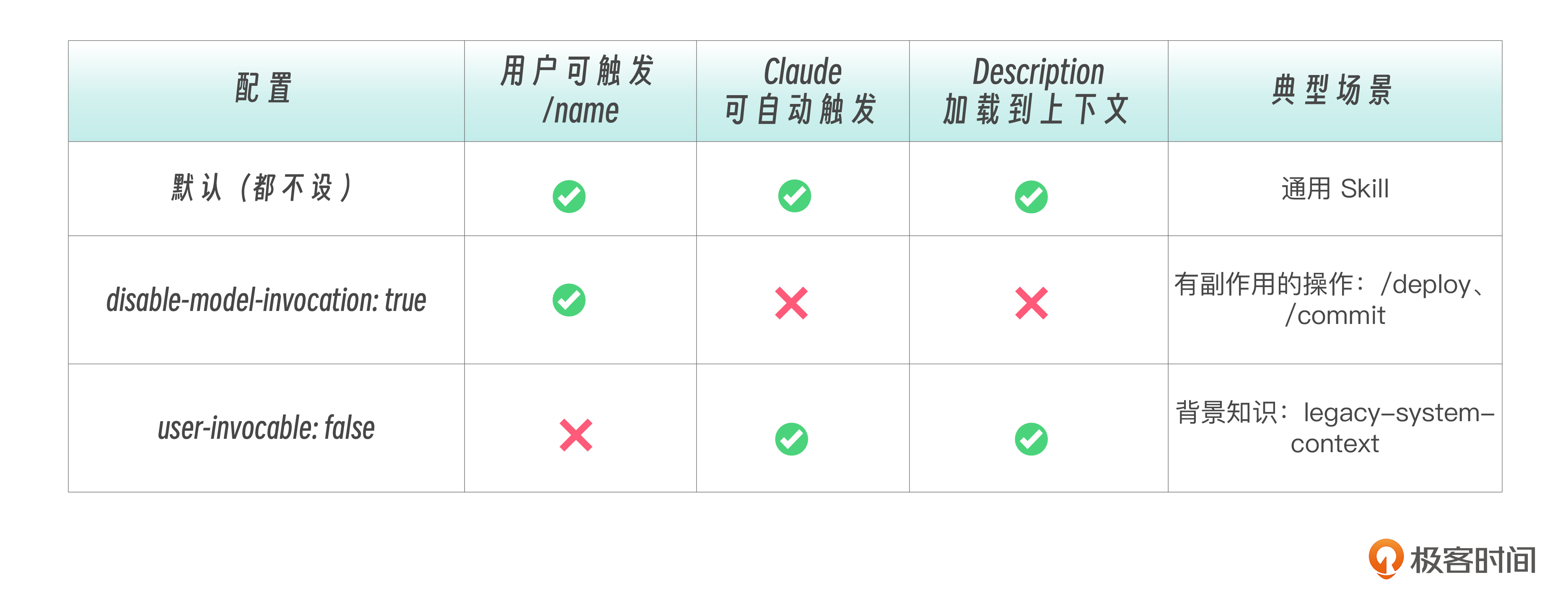
设有 disable-model-invocation: true 的 Skill,其 description 不会加载到上下文 ——Claude 完全看不到它,只有用户 /name 才能触发。
另外,可以采用三种方式来控制 Claude 对 Skills 的访问。
- 全局禁用:在
/permissions中 denySkill工具 - 精确控制:
Skill(commit)精确匹配,Skill(deploy *)前缀匹配 - 逐个控制:给 Skill 加
disable-model-invocation: truefrontmatter
# 权限规则示例
Skill(commit) # 允许 Claude 使用 commit skill
Skill(review-pr *) # 允许 Claude 使用 review-pr skill(带任意参数)
Skill(deploy *) # 拒绝 Claude 使用 deploy skill(放在 deny 列表)
好的 Skill 设计遵循“ 导航页 + 详情页 ”模式(这个在第 11 讲会深入展开):
SKILL.md ← 导航页:概述 + 引用(< 500 行)
├── reference.md ← 详情页:详细 API 文档
├── examples.md ← 详情页:使用示例
└── scripts/validate.sh ← 工具:可执行脚本
**注意:** SKILL.md 应该被控制在 500 行以内。如果过于复杂,应该将详细参考资料移到独立文件,并在 SKILL.md 中进行引用(也就是我们所常说的渐进式加载)。Skills 的存放位置决定了谁能使用它,以及优先级顺序。 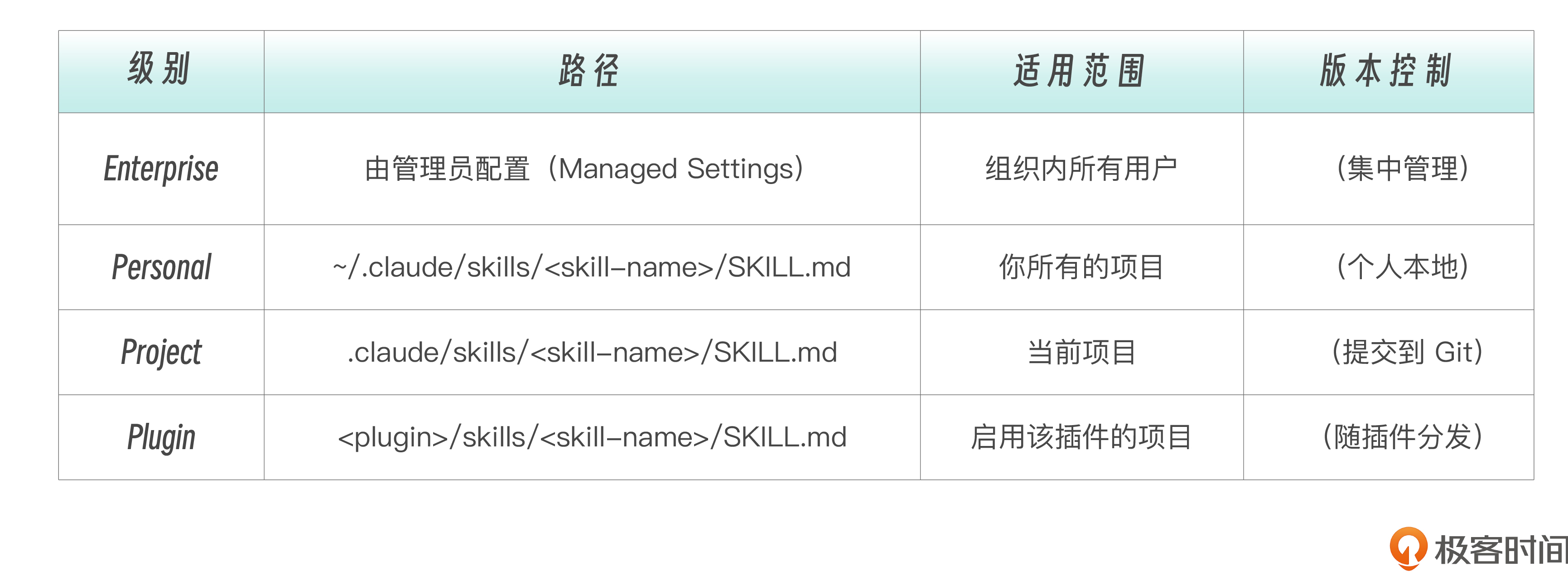 同名优先级:Enterprise > Personal > Project。Plugin Skills 使用 `plugin-name:skill-name` 命名空间,不与其他级别冲突。 当你在子目录(如 `packages/frontend/`)中工作时,Claude Code 会自动发现该目录下的 `.claude/skills/`。这种monorepo 的Skills自动发现机制让 monorepo 中的每个 package 都可以有自己的 Skills。 
两大类型的Skills:参考型和任务型
从工程角度,Skill 内容分为两类,参考型和任务型。参考型 Skill 影响“怎么做”,任务型 Skill 决定“做什么”。前者是语义环境,后者是具体行动。
你在写 description 时需要明确它属于哪种类型。

# 参考型——Claude 自动选择是否使用
name: api-conventions
description: API design patterns for this codebase. Use when writing or reviewing API endpoints.
# 任务型——通常由用户手动触发
name: deploy
description: Deploy the application to production
disable-model-invocation: true
从企业本体论的视角看,所谓“参考型”和“任务型”Skill,其实对应的是两种不同的组织存在方式。
参考型 Skill 更像组织的行为规范层。它定义“在这个世界里,什么是正确的做法”——例如 API 设计标准、代码风格、错误处理约定。这类 Skill 通常由模型根据语义自动判断是否加载,它不主导行动,而是塑造行动的方式。它属于“世界规则”。
任务型 Skill 则更像组织的操作流程层。它定义一次明确的行动——部署、发布、迁移、生成报告等。这类行为具有边界和风险,通常需要显式触发,因此常配合 disable-model-invocation 使用。它属于“世界事件”。
创建一个参考型SKILL.md 文件:api-conventions
下面我们就通过创建一个参考型的Skill来理解SKILL.md 文件的结构(任务型Skill的创建,留到下节课介绍)。
在Claude Code中,每个 Skill 独占一个目录。其标准的目录和文件结构如下:.claude/skills/<skill-name>/SKILL.md。
因此,首先要在项目中创建一个以 skill 名称命名的目录(参考我的Repo中的04-Skills/projects/01-reference-skill)。里面放 SKILL.md 文件。
我们即将要创建的这个 参考型 Skill 是一个“API 设计规范”:
.claude/skills/api-conventions/ # skill 目录,名称即 skill 名
└── SKILL.md # 主文件(必需)
---
name: api-conventions
description: API design patterns and conventions for this project. Covers RESTful URL naming, response format standards, error handling, and authentication requirements. Use when writing or reviewing API endpoints, designing new APIs, or making decisions about request/response formats.
allowed-tools:
- Read
- Grep
- Glob
---
# API Design Conventions
These are the API design standards for our project. Apply these conventions whenever working with API endpoints.
## URL Naming
- Use plural nouns for resources: `/users`, `/orders`, `/products`
- Use kebab-case for multi-word resources: `/order-items`, `/user-profiles`
- Nested resources for belongsTo relationships: `/users/{id}/orders`
- Maximum two levels of nesting; beyond that, use query parameters
- Use query parameters for filtering: `/orders?status=active&limit=20`
## Response Format
All API responses must follow this structure:
{
"data": {}, // 成功时返回的数据
"error": null, // 错误时返回错误对象 { code, message, details }
"meta": { // 分页和元信息
"page": 1,
"limit": 20,
"total": 100
}
}
## HTTP Status Codes
- 200: 成功返回数据
- 201: 成功创建资源
- 400: 请求参数错误
- 401: 未认证
- 403: 无权限
- 404: 资源不存在
- 422: 业务逻辑错误
- 500: 服务器内部错误
## Authentication
- All endpoints require Bearer token unless explicitly marked as public
- Public endpoints must be documented with `@public` annotation
- Token format: `Authorization: Bearer <jwt-token>`
## Versioning
- API version in URL path: `/api/v1/users`
- Breaking changes require new version
这个文件有三个部分:
注意这个 Skill 的关键特征——它是一个典型的 参考型 Skill 。
这正是企业本体论的体现—— 它告诉 Claude 在我们的世界里,API 应该长什么样 。
在这里, description是 Skill 的灵魂,因为它不是给人看的文档,而是给 Claude 看的触发器。 Claude 选择是否激活一个 Skill,完全依赖于阅读 description。这不是关键词匹配,而是语义理解。
用户输入: "帮我看看这段代码有没有问题"
Claude 思考过程:
1. 扫描所有 Skills 的 description
2. 看到 "code-reviewing" 的 description:
"Review code for quality... Use when the user asks for code review..."
3. 语义推理:"看看代码有没有问题" ≈ "code review"
4. 决定:激活这个 Skill
如果你这样写 description,想想看合适么?
description: Handles PDFs
很明显,问题在于太模糊,“handles”是什么意思?读取?转换?合并?Claude 不知道什么时候该用它。用户说“帮我处理这个 PDF”时,Claude 可能不确定这个 Skill 是否合适。
我们再对比一下更好的 description 长什么样。
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
为什么这版更好?因为它列出了具体动作(extract, fill, merge);包含了用户可能说的关键词(PDF, forms, document extraction);明确说明了触发场景(“Use when…”)
因此,我给你总结了一个 description写作公式 :
description = [做什么] + [怎么做] + [什么时候用]
套用公式创作几个示例Skill:
# 代码审查 Skill
description: Review code for quality, security, and best practices. Checks for bugs, performance issues, and style violations. Use when the user asks for code review, wants feedback on their code, mentions reviewing changes, or asks about code quality.
# API 文档 Skill
description: Generate API documentation from code. Extracts endpoints, parameters, and response schemas. Use when the user wants to document APIs, create API reference, generate endpoint documentation, or needs help with OpenAPI/Swagger specs.
# 数据库查询 Skill
description: Query databases and analyze results. Supports SQL generation, query optimization, and result interpretation. Use when the user asks about data, wants to run queries, needs database information, or mentions tables/schemas.
当你有多个 Skills 时,确保它们的 description 有明确区分:
# ❌ 容易冲突
name: unit-testing
description: Write tests for code
name: integration-testing
description: Write tests for code
# ✅ 明确区分
name: unit-testing
description: Write and run unit tests for individual functions. Use for testing single functions or methods in isolation, mocking dependencies, and verifying function behavior.
name: integration-testing
description: Write and run integration tests for system components. Use when testing how multiple components work together, testing API endpoints end-to-end, or verifying database interactions.
Skills Frontmatter 字段详解
Claude Code官方支持的完整 frontmatter 字段如下。
---
name: my-skill-name # 可选:Skill 标识符(省略则用目录名)
description: What this does # 推荐:触发器(最重要!)
argument-hint: "[issue-number]" # 可选:自动补全时的参数提示
disable-model-invocation: true # 可选:禁止 Claude 自动触发
user-invocable: false # 可选:对用户隐藏 /skill-name
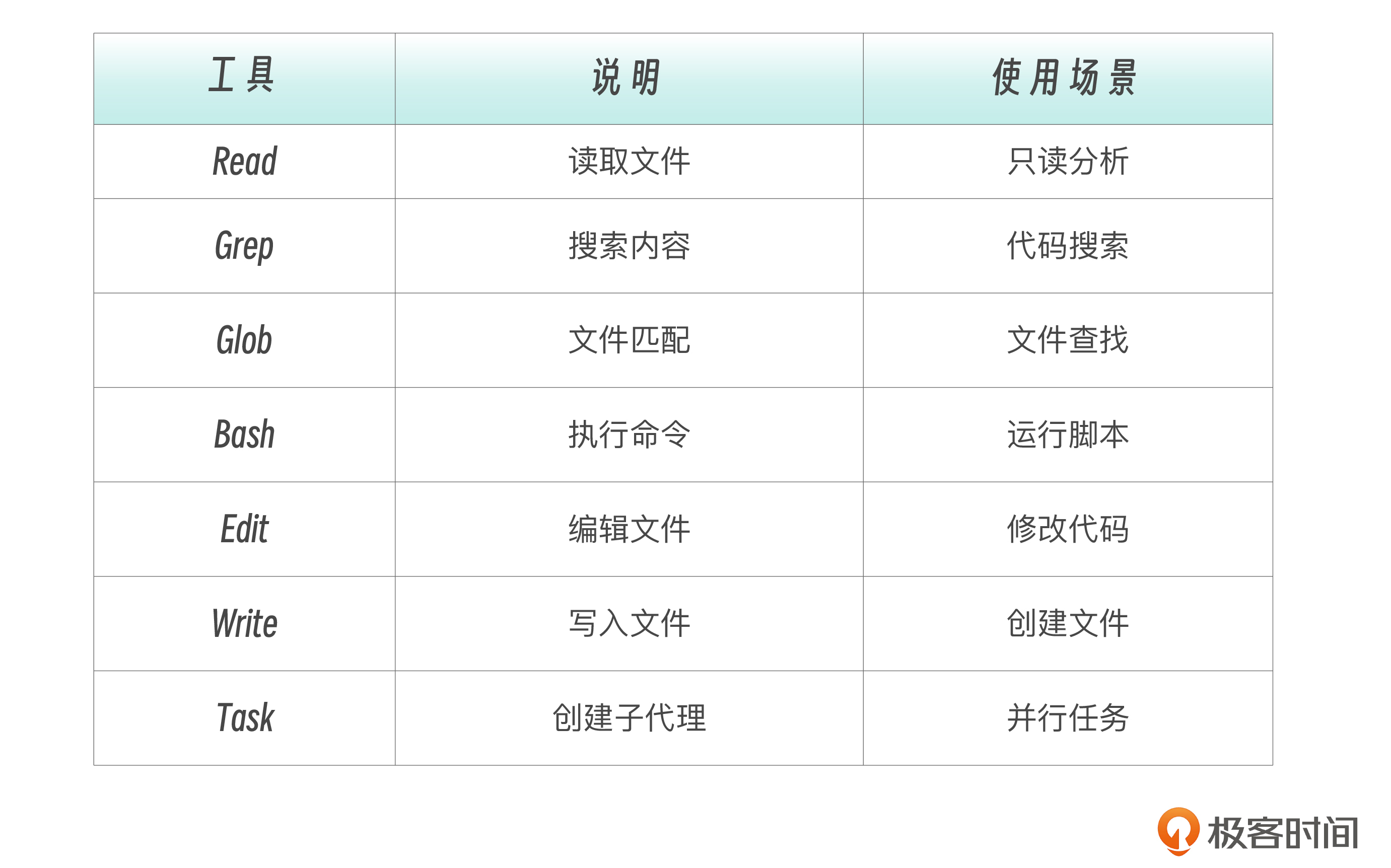
allowed-tools: # 可选:限制可用工具
- Read
- Grep
- Glob
model: sonnet # 可选:指定执行模型
context: fork # 可选:在子代理中隔离执行
agent: Explore # 可选:context: fork 时的代理类型
hooks: # 可选:作用域为此 Skill 的 Hooks
PreToolUse:
- matcher: Write
hooks:
- type: command
command: "echo 'Write called in skill'"
---
其中所有字段都是可选的,但强烈建议提供 description,否则 Claude 无法判断何时使用。
让我逐一解释核心字段:
name字段:最大 64 字符,只能使用小写字母、数字、连字符,推荐使用动名词形式:code-reviewing、api-documenting、bug-fixing。如果省略了这个字段(通常不大可能啦),则自动使用目录名(.claude/skills/code-reviewing/→ name 为code-reviewing)description字段:这是最重要的字段——它决定 Skill 何时被触发。这个字段应该包含两部分信息:这个 Skill 做什么,以及什么情况下使用它。如果省略了这个字段(也不大可能啦),系统会使用 Markdown 正文的第一段作为 description。
**注意** :所有 Skill 的 description 会被加载到上下文中供 Claude 判断选择,默认总预算为 15,000 字符。如果你的 Skills 很多,导致 description 被截断,可以运行 `/context` 查看警告,并通过环境变量 `SLASH_COMMAND_TOOL_CHAR_BUDGET` 调大预算。
argument-hint: "[issue-number]" # /fix-issue [issue-number]
argument-hint: "[filename] [format]" # /convert [filename] [format]

还可以更精细地控制 Bash 命令。
allowed-tools:
- Bash(git:*) # 只能执行 git 命令
- Bash(npm test:*) # 只能执行 npm test 相关命令
**权限交互** :`allowed-tools` 中的工具在 Skill 激活时 **无需逐次确认** 。你的全局权限设置(`/permissions`)仍然控制其他工具的审批行为。
好了,这就是所有frontmatter 字段的说明。现在,你可以这样测试这个api-conventions:
帮我写一个用户管理的 API 接口。
Claude 会自动识别这是 API 相关需求,激活 api-conventions Skill,然后按照规范生成代码——使用复数名词的 URL、标准的响应格式、正确的状态码。
注意,我们并没有输入 /api-conventions,只是自然地描述需求,Claude 就自动加载了这份”企业知识”。这就是参考型 Skill 的威力—— 知识在需要的时候自动到场 。
总结一下
好的,这一讲内容非常多,你需要慢慢消化。
我来给你总结一下重点。
- Skills 是可由用户或 Claude 触发的能力包 ,Claude 通过语义推理决定何时激活,但目前已经脱离了Claude Code本身,形成了Agent 通用技能生态。
- Skill 的 description不是文档,而是触发器 ,其构建公式为:
做什么 + 怎么做 + 什么时候用 - Claude Code采用渐进式加载 来节省 token——description 常驻上下文,全文仅在触发时加载。
当我们谈论 Agent 系统的工程化时,我们真正面对的问题,并不是“模型是否足够强大”,而是“模型在何时拥有何种知识”。Skills 给出的答案,是通过语义定义与按需加载,让能力在正确的时刻出现。在有限的上下文窗口里,组织的做事方式第一次获得了结构化存在的形式。
这,才是 Skills 的真正意义。
最后,让我们来建立一个系统的设计思维框架。这个框架用来回答两个问题。
- 面对一个具体需求,如何决定该不该用 Skill,怎么用。
- 什么时候用参考型Skill,什么时候用任务型Skill?什么时候必须手动触发?
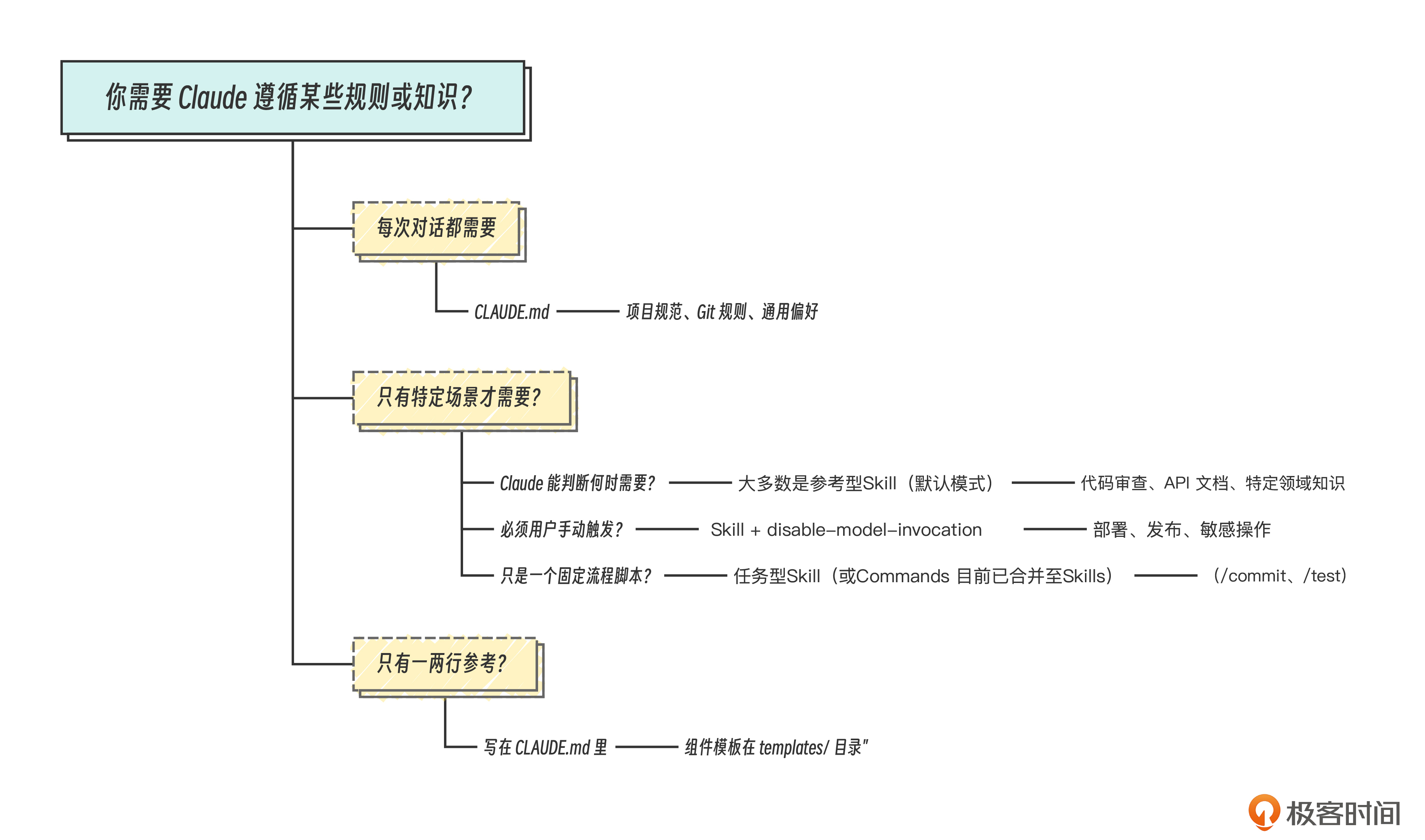
简而言之,CLAUDE.md 放“Claude 每次都该知道的少量规则”(< 100 行);Skill 放“特定场景下的详细指令和知识”(可以很长,按需加载)。如果你犹豫 放 CLAUDE.md 还是 Skill,那么就放 Skill,并在 CLAUDE.md 里加一行引用 。
思考题
- 你的项目中有哪些专业知识适合封装成 参考型 Skill ?想想那些 Claude 需要在特定场景下自动应用的知识(API 规范、代码风格、领域知识)。
- 如果两个 Skill 的功能有重叠,你会如何设计它们的 description 来避免冲突?
- 你有一个内部 legacy 系统的架构文档(5000 行),Claude 在修改相关代码时需要了解它的依赖关系。你会如何用 Skills 组织这份知识?用什么 frontmatter 配置?
- 对比参考型和任务型 Skill,你的项目中有哪些需求适合参考型(Claude 自动触发),哪些适合任务型(用户手动触发)?判断的标准是什么?
下一讲预告
这一讲我们建立了 Skills 的基础认知——从本体论到文件结构,从 description 触发器到渐进式加载,并亲手创建了一个参考型 Skill。
但 Skills 还有另一半—— 任务型 Skill 。当你需要 /commit、/deploy、/review 这样的标准化命令时,需要考虑权限授权、动态上下文注入、安全防护等一系列工程问题。
下一讲,我们将掌握任务型 Skill 的完整设计方法论,并通过团队标准命令集项目(/commit、/review、/pr-create)完成实战。
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。