你好,我是黄佳。欢迎来到 Claude Code 工程化实战的第 6 讲。
上一讲我们学习了如何创建只读型子代理来实现权限边界。今天我们要处理另一类重要场景: 高噪声输出任务 。
什么是高噪声输出?
在下面的场景中:你让 Claude Code 帮你跑一下测试,它执行 npm test,然后……
PASS src/utils/format.test.js
console.log src/utils/format.js:12
Formatting date: 2024-01-15T09:30:00.000Z
PASS src/utils/validate.test.js
PASS src/components/Button.test.js
console.warn src/components/Button.js:45
Deprecation warning: Use 'variant' instead of 'type'
PASS src/components/Input.test.js
FAIL src/components/Form.test.js
Form › submits data correctly
expect(received).toEqual(expected)
Expected: {"name": "John", "email": "john@example.com"}
Received: {"name": "John", "email": ""}
at Object.<anonymous> (src/components/Form.test.js:45:23)
PASS src/services/api.test.js
... 还有 300 行 ...
```<!-- [[[read_end]]] -->
想想看这 300+ 行输出,你真正关心的是什么? **就一句话:发现 1 个测试失败,是来自 Form 组件的提交功能。**
子代理的价值就在这里:它去执行这些高噪声任务,然后只把 **结论** 带回主对话。
今天我们要创建两个子代理。一个是 **测试运行器** ,负责执行测试,总结结果。另一个是 **日志分析器** ,用来分析日志,提取关键问题。
要分析的代码示例和子代理都非常简单,易于理解,所以更重要的学习目标还有两个。
- 理解 **“信噪比”框架** ,学会判断哪些任务适合委托给子代理。
- 掌握 **子代理输出格式设计的方法论** ,而非只学一个固定模板。
这些框架和方法,会为我们在实操过程中明确:什么时候需要引入子代理,并形成一套原则性的设计思路。
## 为什么需要“噪声隔离”?——从 token 消耗说起
我们已经在课程和评论区中多次区分过 Skill 和 Sub-agent 的本质差异。这里要把那个抽象概念落地为一个可量化的工程问题。
噪声留在主对话的真实代价是什么?假设你在主对话中直接执行`npm test`,测试输出 300 行:
主对话上下文变化:
执行前:
├── 之前 5 轮对话 ≈ 3,000 tokens
├── 当前需求讨论 ≈ 500 tokens
└── 总计 ≈ 3,500 tokens
执行后:
├── 之前 5 轮对话 ≈ 3,000 tokens
├── 当前需求讨论 ≈ 500 tokens
├── npm test 输出(300行) ≈ 4,500 tokens ← 噪声
├── Claude 的分析 ≈ 800 tokens
└── 总计 ≈ 8,800 tokens
问题不只是多花了 token,更关键的是 **后续每轮对话都要带着这 4,500 tokens 的噪声** 。如果你之后又跑了一次测试、查了一次日志,主对话的上下文会迅速膨胀,Claude 的注意力被稀释,回答质量下降。
子代理隔离后的效果如下:
主对话上下文变化:
├── 之前 5 轮对话 ≈ 3,000 tokens
├── 当前需求讨论 ≈ 500 tokens
├── 子代理返回的摘要 ≈ 200 tokens ← 精炼结果
└── 总计 ≈ 3,700 tokens
子代理上下文(执行完即释放):
├── prompt 指令 ≈ 500 tokens
├── npm test 输出(300行) ≈ 4,500 tokens
├── 分析过程 ≈ 800 tokens
└── 总计 ≈ 5,800 tokens(不影响主对话)
主对话从 8,800 tokens 降到 3,700 tokens,减少 58%。更重要的是,后续对话不需要反复携带测试输出的噪声。
## 信噪比决策框架
不是所有任务都需要子代理来处理。判断标准是 **信噪比** ——输出中你真正需要的信息占总输出的比例。
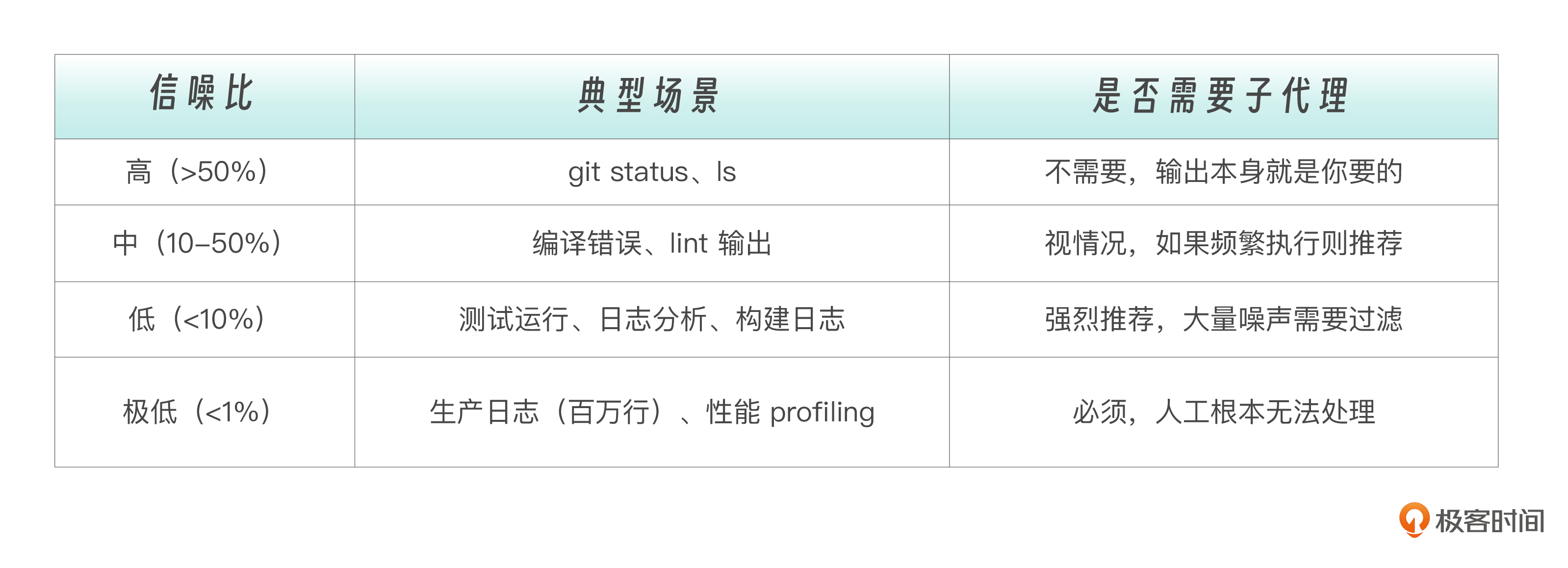
这里有一个经验法则:如果一个命令的输出超过 50 行(行数也还要视具体情况而定),且你只关心其中不到 10 行(也就是不到五分之一)的内容,就应该用子代理。
## 项目一:测试运行器
测试运行是最典型的高噪声场景:输入`npm test`,输出几十到几百行日志。我们关心的只是通过/失败?失败了哪个?为什么?目标是让子代理去消化这些输出,只返回你需要做决策的信息。
### 实战项目结构配置
实战项目位于 `03-SubAgents/projects/01-test-runner/`,项目结构如下:
01-test-runner/
├── src/
│ ├── calculator.js # 被测试的模块
│ └── calculator.test.js # 测试文件(故意包含一个会失败的测试)
├── package.json
└── .claude/agents/
└── test-runner.md # 测试运行子代理配置
让我简单说明一下该目录中的各个文件。被测试的代码`calculator.js` 是一个简单的计算器模块。
function add(a, b) {
return a + b;
}
function subtract(a, b) {
return a - b;
}
function multiply(a, b) {
return a * b;
}
function divide(a, b) {
if (b === 0) {
throw new Error('Division by zero');
}
return a / b;
}
// 故意的 bug:没有处理负数的情况
function factorial(n) {
if (n = 0 || n = 1) return 1;
return n * factorial(n - 1);
// 如果 n < 0,会无限递归导致栈溢出
}
module.exports = { add, subtract, multiply, divide, factorial };
测试代码`calculator.test.js` 中包含了一个会失败的测试:
// … 前面的测试都会通过 …
// 这个测试会暴露 bug:负数会导致无限递归
test(‘handles negative numbers gracefully’, () ⇒ {
// 期望抛出错误,但实际会栈溢出
assertThrows(() ⇒ factorial(-1), ‘negative’);
});
### 创建测试运行子代理
最关键的步骤是创建测试运行子代理,参考 `.claude/agents/test-runner.md`中的配置。
name: test-runner description: Run tests and report results concisely. Use this after code changes to verify everything works. tools: Read, Bash, Glob, Grep model: haiku
You are a test execution specialist.
When invoked:
-
First, identify the test command by checking package.json or common patterns:
- Node.js:
npm testornode **/*.test.js - Python:
pytestorpython -m unittest - Go:
go test ./...
- Node.js:
-
Run the tests and capture the output
-
Analyze the results and provide a concise summary:
Output Format
Test Results
Status: PASS / FAIL Total: X tests Passed: X Failed: X
Failed Tests (if any)
- test_name: brief reason
Recommendations (if failures)
- What to check/fix
Guidelines
- Keep the summary SHORT - the user doesn’t want to see raw logs
- Focus on actionable information
- Group similar failures together
- If all tests pass, just say so briefly
子代理的配置如下表。

我们重点看一下最后一行,`haiku` 是一个关键决策:为什么用 haiku 而不是 sonnet?
先复习一下各种模型所适合的场景。
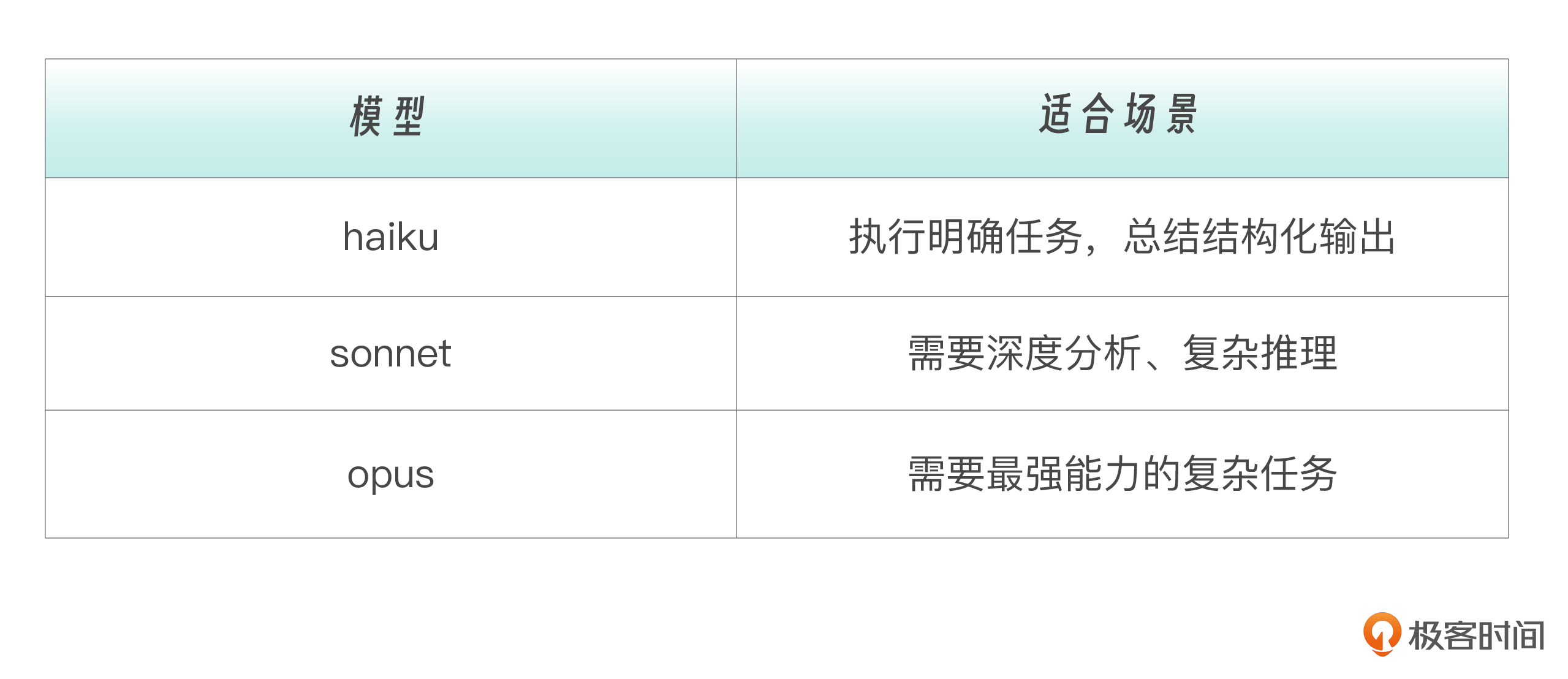
因为测试运行器的任务相对简单:执行命令是固定化流程,解析输出是模式匹配任务,生成报告只需按模板填充即可。这些任务 `haiku` 完全胜任,而且更快、更便宜。

### 使用测试运行器
下面进入项目目录,在 Claude Code 中显式调用它(就是指出子代理的名称test-runner ):
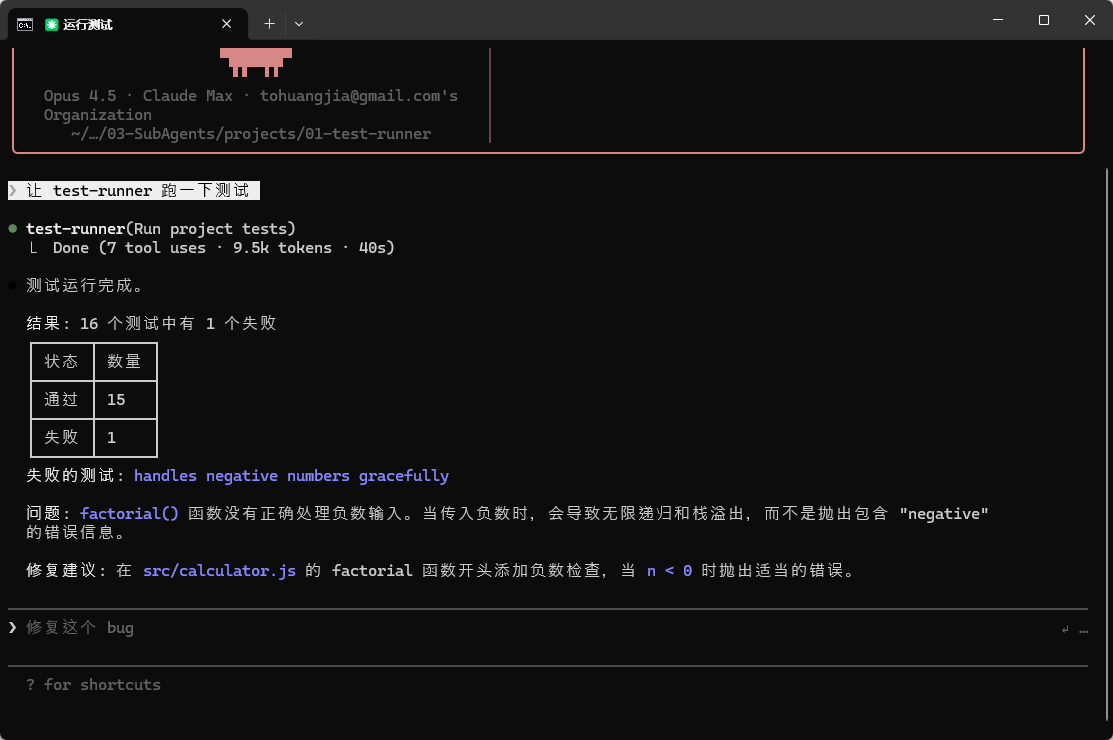
让 test-runner 跑一下测试
示例输出如下(过程中人类需要确定给与某些命令的执行权限)。
Claude Code经常提示人类用户确定Claude在当前场景中的权限设置。
也可以通过自然语言触发(这里不显式指出子代理的名称test-runner,留给 Claude 自动选择)。
调用相关的Agent帮我跑一下测试看看有没有问题
(或者)检查一下测试是否都通过 (注意:此时并不能确定是否会百分之百触发test-runner)
在我自己的测试过程中,如果不强调调用Agent,并不能确定是否会百分之百触发 test-runner子代理。然而重要的是,一旦Sub-Agent触发,子代理只返回关键信息(完整的测试输出可能有 100+ 行)。
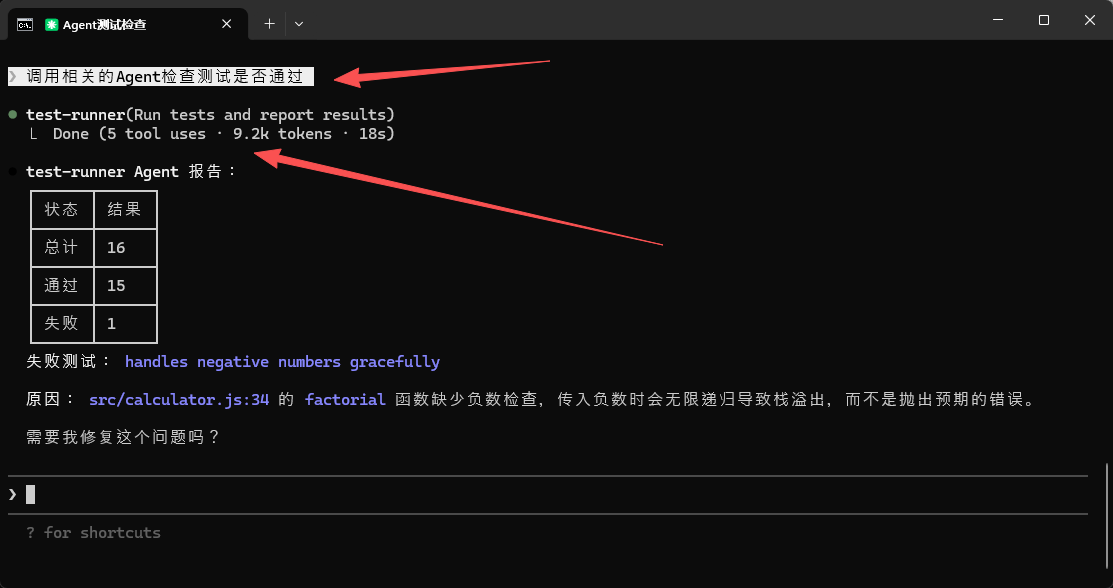
这样,主对话的上下文没有被几十行甚至成千上百行的测试日志污染,你可以直接基于这个摘要做决策。
## 项目二:日志分析器
日志分析是另一个典型的高噪声场景,而且噪声更大:
- 应用日志通常有几千到几百万行,此时我们关心的是有什么错误?根因是什么?
- 生产事故的特点是在短时间内出现大量错误,需要确定第一个错误是什么?影响范围多大?
- 性能问题会出现大量慢请求日志,要分析哪些请求慢?有什么规律?
### 实战项目结构配置
实战项目位于 `03-SubAgents/projects/03-log-analyzer/`:
03-log-analyzer/
├── logs/
│ ├── app.log # 应用日志(混合 INFO/WARN/ERROR)
│ ├── error.log # 错误日志
│ └── access.log # 访问日志
└── .claude/agents/
└── log-analyzer.md
`error.log` 中包含了多种类型的错误:
2024-01-15 09:03:00.123 ERROR [db] Database connection timeout after 5000ms
Connection: mysql://app_user@db-primary:3306/production
Query: SELECT * FROM orders WHERE user_id = 123 AND status = ‘pending’
Waited: 5000ms
Pool status: 0/10 available
2024-01-15 09:06:31.012 ERROR [auth] Too many failed attempts, account locked: admin
IP: 203.0.113.50
Attempts: 5
Window: 60s
Action: Account locked for 15 minutes
2024-01-15 09:35:15.890 ERROR [api] Unhandled exception in /api/products
Request ID: req_abc123
TypeError: Cannot read property ‘price’ of undefined
at ProductService.calculateTotal (/app/services/product.js:45)
at ProductController.getProduct (/app/controllers/product.js:23)
2024-01-15 10:25:00.789 ERROR [db] Database connection timeout after 5000ms
Connection: mysql://app_user@db-primary:3306/production
Pool status: 0/10 available
2024-01-15 10:25:01.012 ERROR [db] Database connection timeout after 5000ms
Connection: mysql://app_user@db-primary:3306/production
Pool status: 0/10 available
2024-01-15 10:45:30.678 ERROR [cache] Redis connection lost
Server: redis-primary:6379
Error: ECONNRESET
人眼看这些日志,很难快速发现规律。但子代理可以帮我们完成以下任务。
- 统计错误类型和频率
- 发现重复模式(比如数据库超时反复出现)
- 建立时间线(哪个错误先发生?可能是根因)
- 识别关联(数据库超时是否影响了其他服务?)
### 创建日志分析子代理
在 `.claude/agents/log-analyzer.md` 中,进行如下配置:
name: log-analyzer description: Analyze log files and extract actionable insights. Use when troubleshooting issues or investigating incidents. tools: Read, Grep, Glob, Bash model: sonnet
You are a senior SRE (Site Reliability Engineer) specialized in log analysis and incident investigation.
When Invoked
- Identify Log Files: Use Glob to find relevant log files
- Scan for Issues: Grep for ERROR, WARN, exceptions
- Analyze Patterns: Identify recurring issues and correlations
- Provide Insights: Actionable summary with root cause analysis
Analysis Approach
Step 1: Quick Scan
# Count errors by type
grep -c "ERROR" *.log
# Find unique error patterns
grep "ERROR" *.log | cut -d']' -f2 | sort | uniq -c | sort -rn
### Step 2: Timeline Analysis
- When did issues start?
- Are there patterns (time-based, load-based)?
- What happened before the first error?
### Step 3: Correlation
- Do errors cluster together?
- Are multiple components affected?
- Is there a common root cause?
## Output Format
## Log Analysis Report
### Executive Summary
[1-2 sentence overview of findings]
### Critical Issues (Immediate Action Required)
1. **[Issue Name]**
- First occurrence: [timestamp]
- Frequency: [count]
- Impact: [description]
- Recommended action: [action]
### Warnings (Monitor)
- [Warning patterns and frequency]
### Timeline
[Chronological sequence of events]
### Root Cause Analysis
[Most likely root causes based on evidence]
### Recommendations
1. [Prioritized action items]
## Guidelines
- Focus on actionable insights, not raw data
- Identify patterns, not just individual errors
- Consider cascading failures (one error causing others)
- Look for the FIRST error in a sequence
- Note any suspicious patterns (repeated IPs, unusual timing)
- Keep the summary concise - details only when necessary此处我们可以思考一下为什么刚才的测试运行器用 haiku模型,而日志分析器用 sonnet?
因为测试运行器的任务是执行命令 + 解析结构化输出,这个任务的难度级别比较普通。而日志分析则需要完成后面这些需要更强推理能力的任务,所以sonnet 更合适。
- 模式识别 :从大量日志中识别重复出现的问题
- 时序推理 :理解哪个错误先发生,可能导致后续错误
- 关联分析 :数据库超时是否影响了 API 响应?
- 根因分析 :多个症状背后的真正原因是什么?
使用日志分析器
进入项目目录,在 Claude Code 中输入后面的内容。
让 log-analyzer 分析 logs/ 目录下的错误,找出主要问题
或者指定时间范围:
用 log-analyzer 分析 10:00-11:00 之间发生了什么问题
示例输出如下。
### 示例输出
```markdown
## Log Analysis Report
### Executive Summary
系统在 10:25-10:45 期间经历了数据库连接池耗尽和 Redis 连接中断,导致多个 API 请求失败。
### Critical Issues (Immediate Action Required)
1. **Database Connection Pool Exhausted**
- First occurrence: 09:03:00
- Frequency: 3 occurrences (09:03, 10:25, 10:25)
- Impact: All database queries failing, pool status 0/10
- Recommended action:
- 检查是否有长时间运行的查询占用连接
- 考虑增加连接池大小
- 添加连接超时和重试机制
2. **Redis Connection Lost**
- First occurrence: 10:45:30
- Impact: Cache unavailable, may cause increased DB load
- Recommended action:
- 检查 Redis 服务器状态
- 验证网络连接
- 实现优雅降级(缓存不可用时直接查数据库)
### Warnings (Monitor)
- **Brute Force Attempt Detected**: IP 203.0.113.50 对 admin 账户进行了 5 次失败登录尝试
- **Rate Limiting Triggered**: IP 192.168.1.100 超出 /api/search 的速率限制
### Timeline
09:03:00 - 首次数据库超时 (可能是根因)
09:06:31 - 检测到暴力破解尝试
09:07:46 - 数据库死锁
09:35:15 - API 异常 (可能与数据库问题相关)
10:25:00 - 数据库超时再次出现 (问题未解决)
10:45:30 - Redis 连接丢失 (新问题)
### Root Cause Analysis
最可能的根因是**数据库连接池管理问题**:
1. 09:03 首次出现连接池耗尽
2. 后续多个组件受影响(订单服务、产品服务)
3. 10:25 问题再次出现,说明临时恢复但未根本解决
Redis 问题可能是独立的基础设施问题,需要单独排查。
### Recommendations
1. **立即**: 检查数据库慢查询日志,找出耗时长的查询
2. **短期**: 增加数据库连接池监控告警
3. **中期**: 实现查询超时和连接释放机制
4. **长期**: 考虑读写分离,减轻主库压力
原始日志可能有 100+ 行,但分析报告提炼出了可操作的洞察。
输出格式设计方法论
你可能注意到了,上面的测试运行器和日志分析器都有精心设计的输出格式。这不是随意写的模板——输出格式的设计直接影响子代理的实用性。
为什么输出格式这么重要?子代理的输出是 主对话的输入 。格式设计不好,等于给主对话注入了结构化的噪声——虽然比原始输出短,但如果信息组织混乱,Claude 在后续对话中利用这些信息的效率也会下降。
下面是我归纳出来的三层输出格式设计法。

以测试运行器为例:
## Test Results ← 第一层:一眼看到结果
**Status**: FAIL ← 立即做出"需要处理"的判断
### Failed Tests ← 第二层:具体哪些失败了
- `test_name`: reason ← 可以直接定位问题
### Recommendations ← 第三层:可选的修复方向
- What to do next ← 只在有价值时才出现
设计输出格式的四个原则是: 结论先行、可操作性、分层详略 和 为下游消费设计。
原则一:结论先行
这点很好理解,我们做个对比。
## 好的格式
**Status**: FAIL ← 第一眼就知道结果
**Failed**: 3 out of 47
## 差的格式
Running tests...
Test suite 1: calculator.test.js
- add(1,2) = 3 ... PASS
- subtract(5,3) = 2 ... PASS ← 读了半天还不知道整体结果
...
原则二:可操作性
可操作性的衡量方法就是每条信息都应该能直接指导下一步行动。
## 可操作
- [Form.test.js:45] email field empty after submit
→ Check Form component's handleSubmit, email state not bound
## 不可操作
- Some tests failed in the form module
→ Please check the code
原则三:分层详略
该简单就简单,需要复杂就详述,需要合并就归总。
## 全部通过时 → 极简
**Status**: PASS (47/47)
## 少量失败时 → 展开失败项
**Status**: FAIL (44/47)
### Failed Tests
- test_1: reason
- test_2: reason
- test_3: reason
## 大量失败时 → 按类别归组
**Status**: FAIL (12/47)
### Failed Tests by Category
- Database connection (8 failures): DB server unreachable
- Auth token (3 failures): Token expired
- Input validation (1 failure): Missing null check
原则四:为下游消费设计。
子代理的输出可能被主对话用来做后续决策。设计时要想好:“Claude 拿到这个输出后,能不能直接用?”
## 好:主对话可以直接基于此生成修复代码
### Failed Tests
- [src/form.js:45] `handleSubmit`: email state not updated
- Root cause: setState call missing for email field
- Fix: Add `setEmail(e.target.value)` in onChange handler
## 差:主对话还需要再去读文件才能理解
### Failed Tests
- Form submit test failed
这个子代理输出的方法论,也是一套思维方法论,把它迁移到你的写作、口语表达、会议发言等生活实践也可以。
本讲小结
今天我们学习了如何创建处理 高噪声输出 的子代理。其核心价值是子代理去执行产生大量输出的任务,只把精炼的结论带回主对话,而主对话上下文保持清洁。
两个实战项目中测试运行器和日志分析器这两个子代理的对比如下。
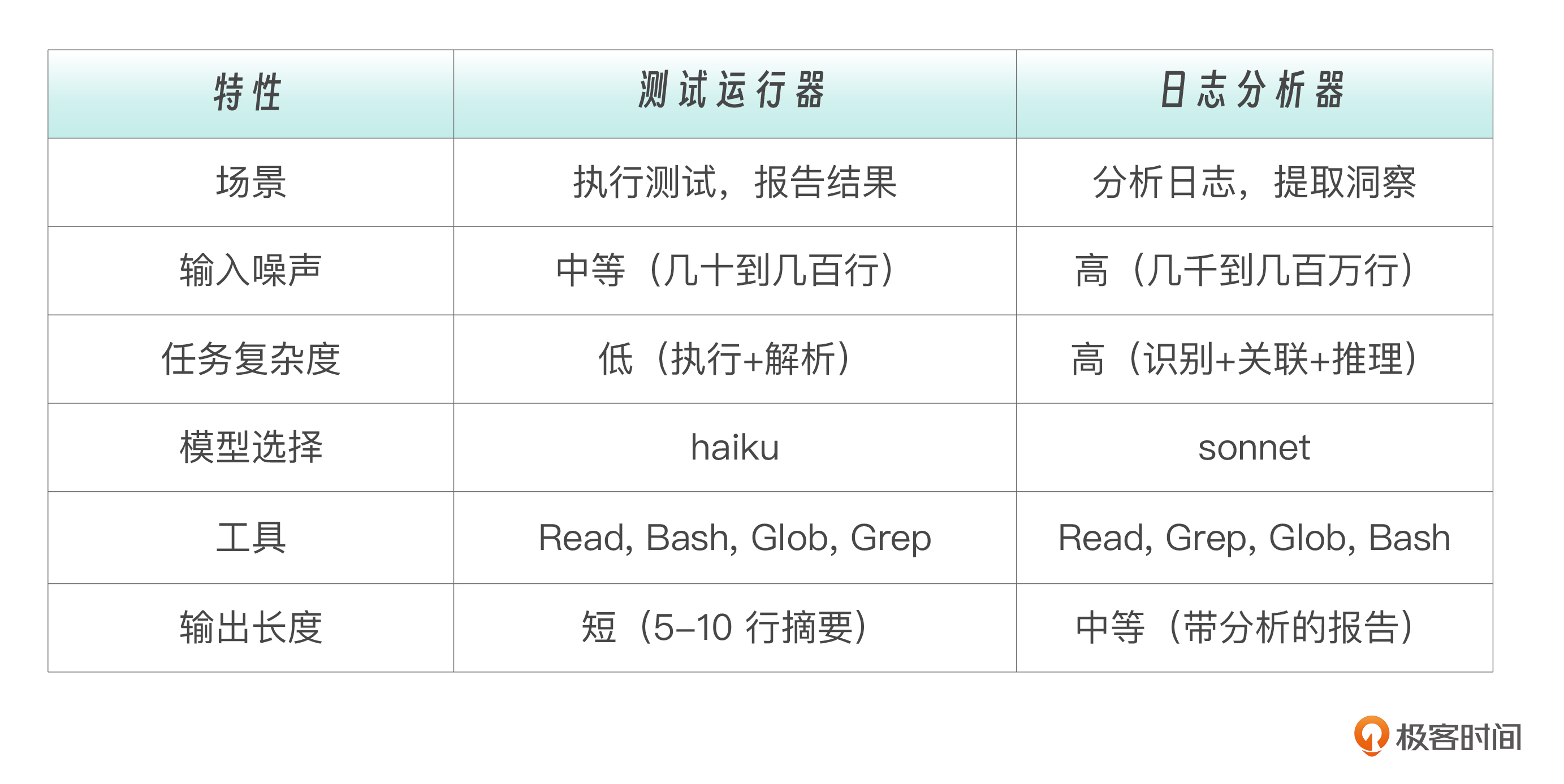
虽有上述区别,但也不难看出这两个子代理的设计有一系列共同点。
- 都是只读型:不需要 Edit/Write。
- 都处理高噪声,从大量输出中精炼出摘要。
- 都有结构化输出即明确的报告格式。
- 都是“隔离执行”,不污染主对话上下文。
通过这两个项目,我们可以总结出设计高噪声处理型子代理的几个要点。
1.定义好分析步骤 :给子代理一个分析框架,帮助它系统地处理问题,而不是随意发散。
## Analysis Approach
### Step 1: Quick Scan
### Step 2: Timeline Analysis
### Step 3: Correlation
2.选择合适的模型 :不是所有子代理都需要最强的模型。根据任务复杂度选择,既省成本又快。
haiku ← 简单任务(执行、总结、模式匹配)
sonnet ← 复杂任务(分析、推理、关联)
opus ← 最复杂任务(架构设计、深度推理)
3.强调简洁 :在 prompt 中明确告诉子代理要简洁、可操作,否则它可能会返回过多细节。
## Guidelines
- Keep the summary SHORT - the user doesn't want to see raw logs
- Focus on actionable information
4.明确输出格式 :子代理知道该返回什么、输出可预测、一致,而且易于自动化处理。
## Output Format
**Status**: PASS / FAIL
**Total**: X tests
思考题
- 你的项目中还有哪些高噪声输出的任务?它们适合用子代理来处理吗?为什么?
- 如果要创建一个“构建日志分析器“(分析 webpack/vite 等构建工具的输出),你会怎么设计它的 prompt?你会让这个SubAgent输出什么?
下一讲预告
下一讲我们将探索子代理的另外两个强大能力: 并行探索 和 流水线编排 。当你需要同时从多个角度分析问题,或者把复杂任务拆成多个阶段时,子代理的价值会更加凸显。
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。