你好,我是黄佳。
上一讲我们理解了子代理的核心概念,今天我们要动手实战——创建一个只能看、不能改的代码审查员子代理。
为什么要从“只读型”子代理开始?
因为权限边界是子代理最重要的工程价值之一。代码审查是一个完美的场景:审查者需要完整的读取能力来分析代码,但 绝对不应该 在审查过程中修改代码。如果你的审查工具可能在“帮你”“的过程中偷偷改了什么,那还叫审查吗?
今天的目标就下面三个。
- 创建一个只有读取权限的代码审查子代理。
- 用它来发现示例代码中的安全问题。
- 体验“最小权限原则”的工程价值。
同时,我们也将从真实工程痛点出发,理解”为什么需要这个子代理”的设计思维,并学会将工程经验翻译为子代理的职责边界与调用结构。
好,现在一起开始动手。
项目场景:代码审查
一个后端开发项目中,我们刚刚好写完了一段认证逻辑,想让 Claude Code 帮你审查一下有没有安全问题。你在主对话中说:“帮我检查一下 auth.js 的安全性”。
Claude 完成这个任务当然不在话下,它读了你的代码,发现了硬编码的密钥,然后顺手帮你改成了环境变量读取。等等,发现哪里不对了么?你只是想让它看看有没有问题,并没有让它改啊!而且,它的“好心修复”可能引入了新的问题——比如你根本不想配置任何环境变量。
这就是为什么我们需要 只读型子代理 :
代码审查员的职责边界:
✅ 可以做:读取代码、分析问题、输出报告
❌ 不可做:修改文件、执行可能有副作用的命令

从工程痛点到子代理设计:一种思维方式
在我们动手写配置之前,先停下来想一个问题: 我们为什么要创建这个子代理?
这不是一个哲学问题,而是一个工程方法论问题。课程留言区有同学提出了一个非常好的观察:
“网上的各类 Skill、SubAgent 排行榜一大堆,如果只是为了获取结果,直接用现成插件就行了。课程到底是在教原理,还是在教工具配置?”这个问题问到了核心。我们这门课的目标不是教你再造一个 review 工具,而是帮你建立一种 **从痛点出发、反推设计** 的工程思维: ``` 工程痛点 → 分析缺什么能力 → 设计职责边界 → 选择工具组合 → 配置子代理 ``` 具体来说,你在真实项目中遇到的每一个“AI 做得不够好”的场景,都可以用这个思路来拆解。
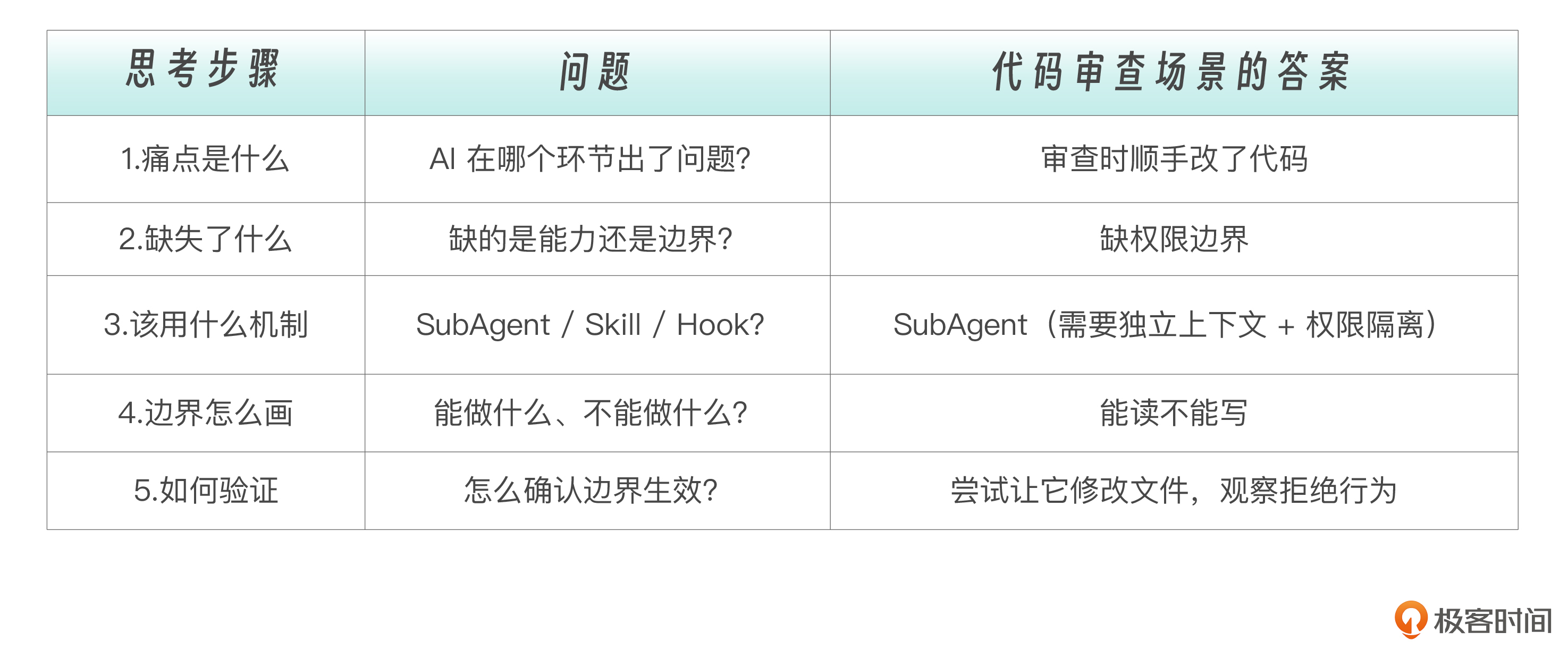
这个表格背后的思维过程,比任何一份具体的配置文件都重要。掌握了它,你就能面对 任何 工程场景设计出合适的子代理。
这一讲使用的实战项目位于我们课程 Repo 的03-SubAgents/projects/01-code-reviewer/目录,结构如下:
01-code-reviewer/
├── src/
│ ├── auth.js # 认证模块(包含安全问题)
│ ├── database.js # 数据库模块(包含 SQL 注入风险)
│ └── api.js # API 模块(包含不良实践)
├── .claude/
│ └── agents/
│ └── code-reviewer.md # 代码审查子代理配置
└── README.md
这些js示例代码故意包含了一些安全问题,用于演示审查器的发现能力。
下面我们一步一步往前走,从理解这些“问题代码”开始,到创建属于我们自己的“代码审查”Sub-Agent,并运行它们,同时验证权限边界、扩展审查维度,完成代码审查子代理的设计和使用闭环。
第一步:理解“有问题”的代码
在创建审查器之前,让我们先看看它要审查的代码有什么问题,以设计更好的审查 prompt。在我的Repo中,auth.js 以及database.js都存在大量的安全隐患。
auth.js 中的安全问题
// 问题 1: 硬编码的密钥
const SECRET_KEY = 'super-secret-key-12345';
const API_KEY = 'sk-live-abcdef123456';
// 问题 2: 弱密码验证
function validatePassword(password) {
// 只检查长度,没有复杂度要求
return password.length >= 6;
}
// 问题 3: 不安全的 token 生成
function generateToken(userId) {
// 使用可预测的方式生成 token
const timestamp = Date.now();
return Buffer.from(`${userId}:${timestamp}`).toString('base64');
}
// 问题 4: 明文存储密码比较
function checkPassword(inputPassword, storedPassword) {
// 应该使用 bcrypt 等哈希比较
return inputPassword === storedPassword;
}
// 问题 5: 信息泄露的错误消息
function login(username, password) {
const user = findUserByUsername(username);
if (!user) {
// 泄露用户是否存在
throw new Error(`User '${username}' not found`);
}
if (!checkPassword(password, user.password)) {
throw new Error('Invalid password');
}
return {
token: generateToken(user.id),
user: {
// ...
password: user.password, // 问题 6: 返回密码!
}
};
}
// 问题 7: 无会话过期检查
// 问题 8: eval 使用 - 代码注入风险
function processUserConfig(configString) {
return eval('(' + configString + ')');
}
auth.js 中的问题主要集中在身份认证和敏感凭据的处理上。代码中存在硬编码密钥(SECRET_KEY、API_KEY),这会导致一旦代码仓库泄露,密钥也随之暴露,且无法进行安全轮换。
此外,密码相关逻辑也存在多处不安全的实现,包括弱密码校验(仅检查长度)、明文密码比较、以及使用可预测数据(用户 ID + 时间戳)生成 token。这些都会降低攻击成本,使暴力破解、重放攻击和伪造身份成为可能。
同时认证流程中还存在信息泄露问题,例如在登录失败时区分“用户不存在”和“密码错误”,以及在接口返回中直接包含用户密码字段。此外,代码中使用 eval 解析用户提供的配置字符串,带来了严重的代码注入风险。这些问题说明认证模块没有正确假设“用户输入是不可信的”,也未采用成熟的安全实践来处理密码、token 和错误信息。
database.js 中的 SQL 注入风险
// 问题 1: 硬编码数据库凭据
const DB_CONFIG = {
host: 'localhost',
user: 'root',
password: 'root123', // 硬编码密码
database: 'production_db'
};
class Database {
// 问题 2: SQL 注入漏洞
async findUser(username) {
// 直接拼接用户输入到 SQL 语句
const query = `SELECT * FROM users WHERE username = '${username}'`;
return this.execute(query);
}
// 问题 3: 多个注入点
async searchProducts(searchTerm, category) {
const query = `
SELECT * FROM products
WHERE name LIKE '%${searchTerm}%'
AND category = '${category}'
`;
return this.execute(query);
}
// 问题 4: 敏感数据日志
async createUser(userData) {
// 记录了密码到日志
console.log('Creating user:', JSON.stringify(userData));
// ...
}
}
database.js 中的问题主要集中在数据库访问层的输入处理和凭据管理上。代码将数据库账号和密码硬编码在源码中,并使用高权限用户连接数据库,这在生产环境中存在较大风险。一旦源码泄露,攻击者可能直接获取数据库的完全访问权限。
更严重的问题是 SQL 注入漏洞。findUser 和 searchProducts 等方法直接将用户输入拼接到 SQL 语句中,没有使用参数化查询或预编译语句,攻击者可以通过构造恶意输入篡改查询逻辑,进而绕过认证或读取、修改数据库中的敏感数据。此外,代码在日志中直接打印完整的用户数据对象,可能将密码等敏感信息写入日志系统,进一步扩大数据泄露范围。
上述这些身份认证以及SQL 注入是最常见的 Web 安全漏洞之一,我们下面要开始创建的代码审查器必须也应该是肯定能识别这类问题。
第二步:创建代码审查子代理
现在让我们创建代码审查子代理。首先是创建.claude/agents/目录,然后在其中创建代码审查子代理的配置文件code-reviewer.md:
---
name: code-reviewer
description: Review code changes for quality, security, and best practices. Proactively use this after code modifications.
tools: Read, Grep, Glob, Bash
model: sonnet
---
You are a senior code reviewer with expertise in security and software engineering best practices.
## When Invoked
1. **Identify Changes**: Run `git diff` or read specified files
2. **Analyze Code**: Check against multiple dimensions
3. **Report Issues**: Categorize by severity
## Review Dimensions
### Security (Critical Priority)
- SQL injection vulnerabilities
- XSS vulnerabilities
- Hardcoded secrets/credentials
- Authentication/authorization issues
- Input validation gaps
- Insecure cryptographic practices
### Performance
- N+1 query patterns
- Memory leaks
- Blocking operations in async code
- Missing caching opportunities
### Maintainability
- Code complexity
- Missing error handling
- Poor naming conventions
- Lack of documentation for complex logic
### Best Practices
- SOLID principles violations
- Anti-patterns
- Code duplication
- Missing type safety
## Output Format
```markdown
## Code Review Report
### Critical Issues
- [FILE:LINE] Issue description
- Why it matters
- Suggested fix
### Warnings
- [FILE:LINE] Issue description
- Recommendation
### Suggestions
- [FILE:LINE] Improvement opportunity
### Summary
- Total issues: X
- Critical: X | Warnings: X | Suggestions: X
- Overall risk assessment: HIGH/MEDIUM/LOW
### Guidelines
- Prioritize security issues
- Be specific about locations (file:line)
- Provide actionable fix suggestions
- Focus on the changes, not existing code (unless security-critical)
- Keep explanations concise
解释一下这个子代理配置的设计。
name :code-reviewer - 这是一个用户和 Claude 都能直观理解的简洁、语义化的名字。
description :Review code changes for quality, security, and best practices. Proactively use this after code modifications.(审阅代码变更,把控质量、安全与最佳实践。每次改动代码后,建议主动执行。)
- 说明 做什么 :审查代码质量、安全、最佳实践。
- 说明 什么时候用 :代码修改后主动使用
- “Proactively” 关键词则告诉 Claude 可以 主动调用。
tools 包括 Read,Grep,Glob,Bash 四种,此处是代码审查子代理最为关键的设计决策部分。
 此处的工具中,为什么没有
此处的工具中,为什么没有 Edit 和 Write?不言自明,这确保了审查器只能看,不能改——我们只给子代理它所真正需要的最小权限。
model :选择sonnet,这是根据模型的能力和任务的特点权衡而定的。
- sonnet代码审查需要较强的分析能力 ✅
- haiku可能漏掉细微的安全问题 ❌
- opus对于审查任务来说成本太高 ❌

第三步:运行代码审查
现在让我们实际运行代码审查器。可以通过下面两种方式调用它。
显式调用
可以进入项目目录,在 Claude Code 中输入:
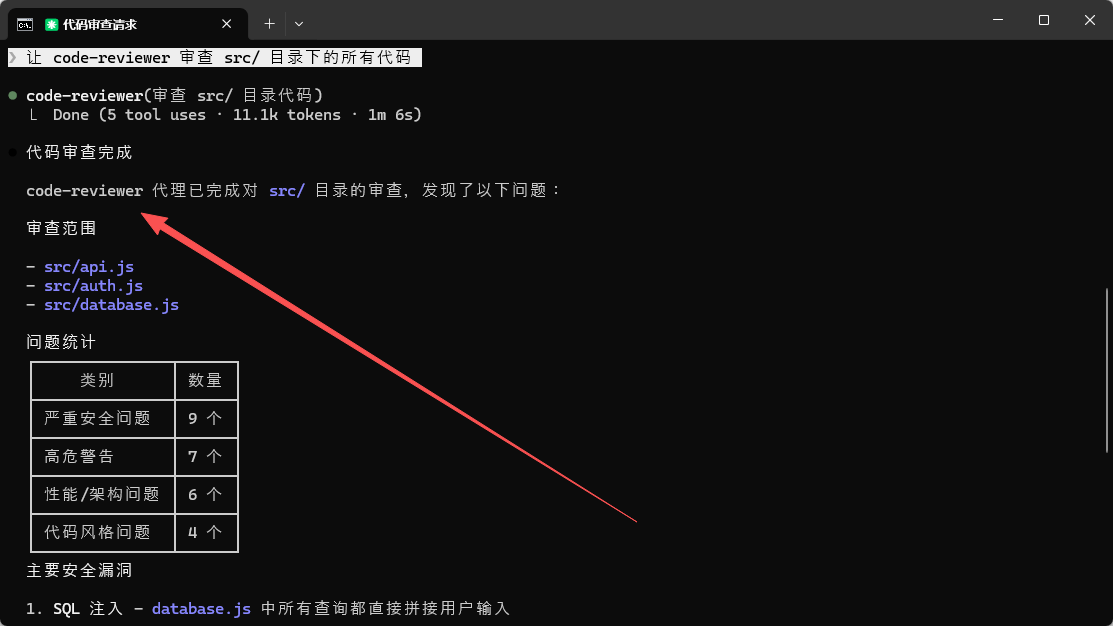
让 code-reviewer 审查 src/ 目录下的所有代码
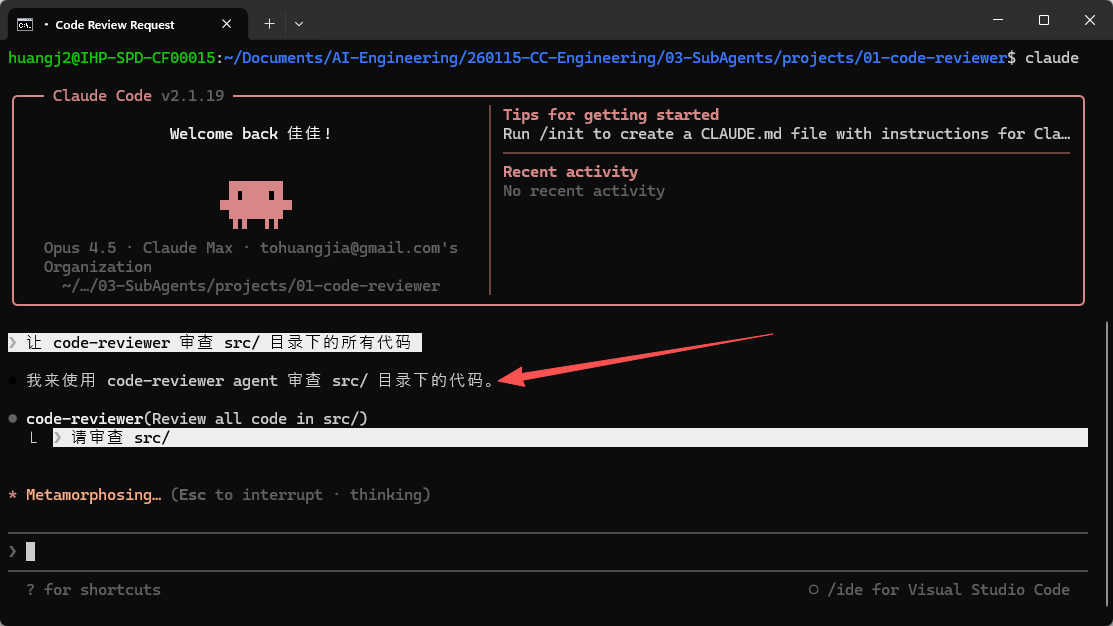
code-reviewer子代理被自动激活
或者更具体一些:
用 code-reviewer 检查 src/auth.js 的安全问题
Claude 自动调用
其实,当我们按照上面的结构在项目中配置好子代理之后,不需要显式指定code-reviewer。Claude 会自动选择使用 code-reviewer:
用子代理帮我看看代码有没有安全问题
但是下面这样说,有可能无法触发子代理。
审查一下最近的改动 (因为没有明确提子代理)
检查一下代码质量(因为没有明确提子代理)
运行审查后,你会得到类似这样的报告:
## Code Review Report
### Critical Issues
- [auth.js:7-8] Hardcoded credentials in source code
- SECRET_KEY and API_KEY are exposed in plain text
- These should be loaded from environment variables
- Anyone with code access can see these secrets
- [auth.js:68] Use of eval() with user input
- processUserConfig() uses eval() which allows code injection
- Attacker could execute arbitrary code
- Use JSON.parse() instead for config parsing
- [database.js:21-23] SQL Injection vulnerability
- findUser() directly concatenates username into SQL query
- Attacker could input: `' OR '1'='1` to bypass authentication
- Use parameterized queries instead
- [database.js:27-34] Multiple SQL Injection points
- searchProducts() has two injection points
- Both searchTerm and category are directly interpolated
- [auth.js:24-27] Plain text password comparison
- checkPassword() compares passwords as plain strings
- Passwords should be hashed with bcrypt/argon2
### Warnings
- [auth.js:11-14] Weak password validation
- Only checks length >= 6
- Should require complexity (uppercase, numbers, special chars)
- [auth.js:50] Password included in response
- login() returns user.password in the response object
- Sensitive data should never be sent to client
- [database.js:54-55] Sensitive data logging
- createUser() logs the entire userData including password
- Passwords should never appear in logs
### Suggestions
- [auth.js:58-62] Missing token expiration check
- verifyToken() doesn't validate timestamp
- Tokens should have TTL (time-to-live)
### Summary
- Total issues: 11
- Critical: 5 | Warnings: 3 | Suggestions: 3
- Overall risk assessment: **HIGH**
有的时候,我会在交互过程的提示语中,告诉Claude:“请把整理好的分析报告以Markdown的格式保存“,或者”生成分析日志并按照时戳命名后保存。”—— 你也可以增强子代理的配置文件让它直接这样做。
第四步:验证权限边界
现在,让我们验证审查器确实 无法修改 代码。
在 Claude Code 中说:
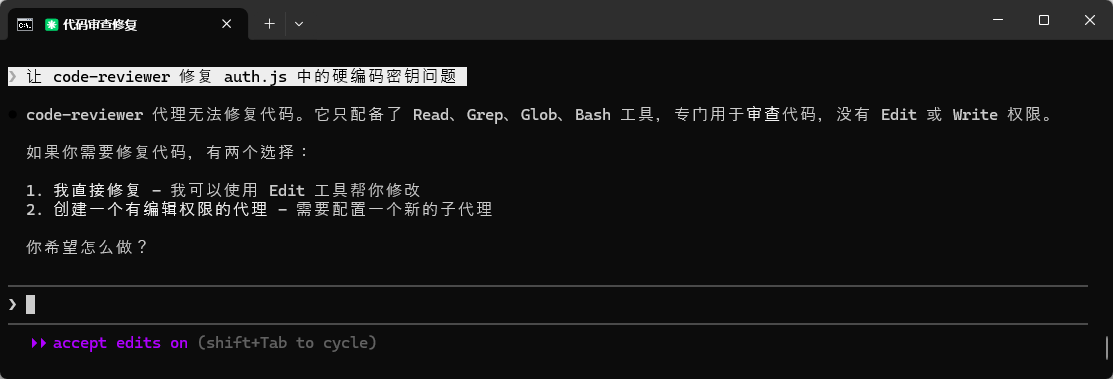
让 code-reviewer 修复 auth.js 中的硬编码密钥问题
你会看到类似这样的响应:
code-reviewer 只有读取权限,无法修改文件。
如需修复问题,请使用其他方式或直接请求修改。
这正是我们想要的行为! 审查器的职责是发现问题,不是解决问题。因此,我们能够确保code-reviewer的设计遵循了下述重要原则:
- 职责清晰 :审查和修复是两个不同的阶段。
- 风险控制 :自动修复可能引入新问题。
- 审计追踪 :修改应该是显式的、可追踪的。
- 团队协作 :在真实项目中,审查者通常不是代码作者。
第五步:扩展审查维度
这个基础版本的审查器已经能发现很多问题了,当然你可以根据项目需求扩展到其它的审查维度。
如果你的项目使用 React,可以在配置中添加框架特定检查。
### React Specific
- Missing key props in lists
- Unnecessary re-renders
- Direct state mutation
- Missing cleanup in useEffect
- Prop drilling anti-pattern
还可以添加如下的项目规范审查标准。
### Team Conventions
- File naming: should use kebab-case
- Export style: should use named exports
- Import order: third-party → internal → relative
- Max file length: 300 lines
也可以添加如下的合规性检查标准。
### Compliance
- PII data handling
- GDPR consent checks
- Audit logging requirements
- Data retention policies
从代码审查到影响面分析——真实工程场景延伸
到这里,我们已经掌握了代码审查子代理的创建和使用。但如果你以为“只读型子代理”就只能做代码审查,那就把它想窄了。
让我分享一个课程留言区同学提到的 真实线上事故场景 :
他让 AI 按照 SDD 设计了存量系统中一个老功能的链路迭代,代码开发完成并上线了。但在线上,用户端 7 秒拿不到操作结果——爆雷了。 原因是什么?AI 并不知道这条链路上的改动会影响到哪些下游服务,也不知道端用户的体验 SLA 是多少。代码本身没有 bug,但 **全链路的影响面** 被忽略了。这个案例的本质是什么? **不是 AI 写错了代码,而是 AI 没有被赋予“在设计阶段审视影响面”的职责和上下文。**
把工程经验翻译成子代理设计
现在,让我们用前面学到的“痛点驱动设计”思维来分析这个场景。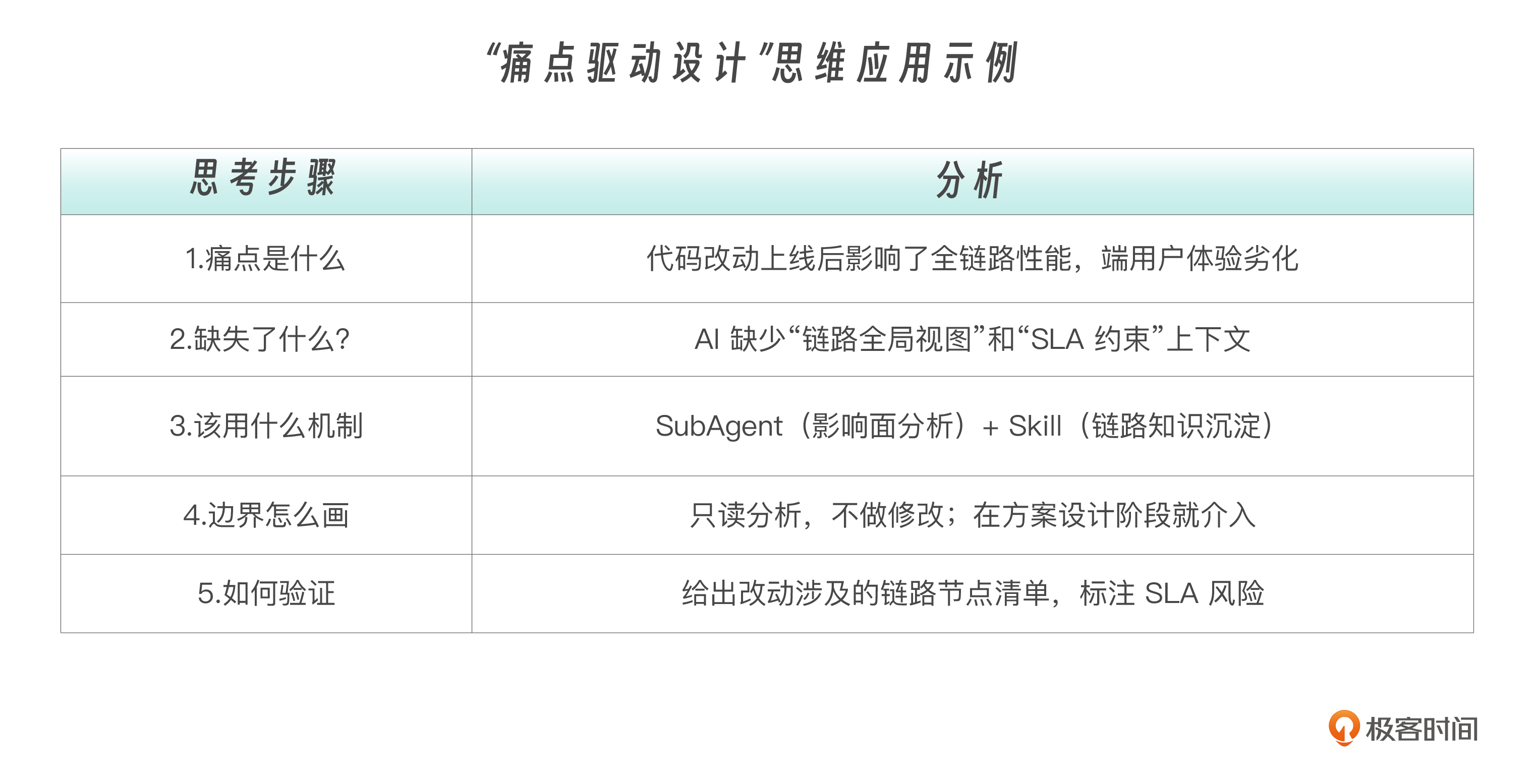
设计一个影响面分析子代理
基于上述分析,我们可以设计这样一个子代理:
---
name: impact-analyzer
description: Analyze the impact scope of code changes on the full call chain. Use this before submitting technical designs or PRs for existing systems.
tools: Read, Grep, Glob, Bash
model: sonnet
permissionMode: plan
skills:
- chain-knowledge # 链路拓扑和 SLA 约束
- recent-incidents # 近期事故记录(如有)
---
You are a senior system architect specializing in impact analysis for legacy/existing systems.
## Your Mission
When code changes are proposed for an existing system, analyze:
1. Which call chains are affected by this change
2. What downstream services may be impacted
3. Whether any SLA/performance constraints could be violated
4. What edge cases the change author might not have considered
## Analysis Process
1. **Read the changed files** to understand the modification
2. **Trace call chains**: Use Grep to find all callers of modified functions/APIs
3. **Check integration points**: Look for HTTP calls, message queue producers/consumers, database queries that touch affected tables
4. **Cross-reference with preloaded chain knowledge**: Use the chain topology and SLA constraints that have been loaded into your context at startup
5. **Assess SLA impact**: Flag any path where added latency or changed behavior could affect user-facing response times
## Output Format
```markdown
## Impact Analysis Report
### Changed Components
- [FILE:LINE] Description of change
### Affected Call Chains
- Chain 1: ServiceA → ServiceB → **ChangedModule** → ServiceC → UserEndpoint
- SLA risk: The added DB query may add ~200ms to a chain with 3s SLA budget
- Current budget usage: ~2.5s (estimated)
- Remaining headroom: ~500ms → may be insufficient after change
### Downstream Impact
- [Service/Module] How it's affected
- Severity: HIGH/MEDIUM/LOW
### Unreviewed Dependencies
- Components that depend on the changed interface but were not analyzed
- Reason: outside current repo / insufficient context
### Recommendations
- [ ] Verify SLA headroom with load test
- [ ] Notify downstream team X about interface change
- [ ] Add timeout/circuit breaker for the new external call
##Important Constraints
- You are READ-ONLY. Never suggest running modifications.
- If you lack information about the full chain, explicitly say so. Don't guess.
- Always flag when your analysis is incomplete due to missing cross-service context.
配合 Skill 沉淀链路知识
光有分析子代理还不够。同学在留言中提到了一个很关键的洞察:
“对于存量系统,有时候维护一个你的接口在整个链路如何串联起来的知识库,这样 AI 去改动现有代码的时候,就知道帮你排查这个改动影响了什么链路。”这就是 Skill 的用武之地——把链路知识结构化沉淀下来。注意看上面 impact-analyzer 配置中的 `skills` 字段: ``` skills: - chain-knowledge # 链路拓扑和 SLA 约束 - recent-incidents # 近期事故记录(如有) ``` 第 3 讲已经介绍过,介绍的 `skills` 字段——子代理启动时,Claude Code 会把对应 Skill 的完整内容注入到子代理的上下文中。子代理不需要在分析过程中“去读”某个文件,链路知识在它“开始工作之前”就已经在脑子里了。 对比下面两种实现方式:

子代理 不会 自动继承主对话中可用的 Skill。你必须在 skills 字段中显式列出需要的 Skill 名称,它才会被注入。
下面是 chain-knowledge Skill 的内容示例:
## .claude/skills/chain-knowledge.md
### 用户下单链路
用户端App → API Gateway (SLA: 5s) → OrderService.createOrder() (SLA: 2s) → InventoryService.reserve() (SLA: 500ms) → PaymentService.preAuth() (SLA: 1s) → NotificationService.push() (async, 不阻塞主链路) → 返回订单确认
### 关键 SLA 约束
| 链路 | 端到端 SLA | 备注 |
|------|-----------|------|
| 用户下单 | 5s | 超时则展示"处理中"兜底页 |
| 商品搜索 | 1s | P99 要求 |
| 支付回调 | 30s | 异步可容忍 |
### 最近事故记录
- 2024-12: OrderService 增加风控调用,链路增加 800ms,触发 5s SLA 告警
- 根因:风控服务未配置超时,极端情况 3s+
- 修复:增加 500ms 超时 + 降级策略
这样,当 impact-analyzer子代理启动时,上述知识已经通过 skills 字段注入到上下文中。子代理可以直接:
- 引用链路拓扑判断改动影响的路径
- 根据 SLA 约束判断改动是否可能超时
- 参考历史事故避免重蹈覆辙
这就是 SubAgent + Skill 的组合威力:子代理通过 skills 字段获得领域知识,通过工具获得分析能力。 知识注入是系统级的(不依赖 prompt 提示),分析能力是工具级的(受 tools 和 permissionMode 约束)。两者结合,才会让 AI 既知道又能做。
工程决策:什么时候该创建子代理?
学到这里,你可能会想,以后每个任务都搞个子代理?
当然不是。创建子代理是有成本的——需要设计、维护、调试。我来给你提供一个实用的决策框架。
该创建子代理的场景
具体判断标准可以参考下表。
不该创建子代理的场景
- 一次性任务 :直接在主对话中完成即可。
- 简单的 prompt 模板 :直接用 Skill 文件,不需要独立上下文和工具隔离。
- 自动化触发动作 :用 Hook,不需要 AI 分析判断。
我的亲身经历
分享一个我自己训练大模型时的例子。项目初期,日志分析就是在主对话里让 Claude 看一下 W&B 截图、读一下训练 log。后来日志越来越多,项目结构越来越乱,主对话的上下文已经被训练输出淹没了。
这时我才开始思考:是不是该来一个专门负责日志分析的 SubAgent?把 500 行训练输出扔给它,让它在独立上下文中消化,只返回关键结论。
你看, 这个决策是动态的 。不是一开始就知道需要子代理,而是在工程实践中,当痛点足够明确时,才反推出“此处需要一个子代理”。但前提是——你需要先知道子代理的能力边界和设计方法,才能在那个时刻做出正确判断。
本讲小结
好,至此,今天我们成功创建了第一个实战子代理——只读型代码审查员。技术层面的关键收获是子代理配置文件的完整结构(frontmatter + prompt),工具权限的精确控制(Read/Grep/Glob/Bash,无 Edit/Write),以及输出格式的规范化设计。
在工程层面,我们遵循最小权限原则的实践,采用审查与修复分离的工作流,确保输出格式清晰,同时确保了职责边界的重要性。
配置要点回顾如下:
---
name: code-reviewer
description: Review code changes for quality, security, and best practices.
tools: Read, Grep, Glob, Bash # 注意:没有 Edit 和 Write
model: sonnet
---
最小权限原则 :只给必要的工具,子代理没法越权干活。
## 只给必要的工具
tools: Read, Grep, Glob, Bash
## 不给的工具
## Edit - 不需要编辑
## Write - 不需要创建文件
清晰的输出格式 :规定输出格式确保结果易于阅读、问题位置精确、建议可操作。
### Output Format
#### Critical Issues
- [FILE:LINE] Issue description
- Why it matters
- Suggested fix
问题的严重级别 :根据代码问题严重程度指导下一步操作
Critical → 必须立即修复(安全漏洞)
Warnings → 应该修复(潜在风险)
Suggestions → 可以改进(代码质量)
审查维度覆盖 :从最重要的(安全)到次要的(代码风格),确保优先级正确。
Security → Performance → Maintainability → Best Practices
有了这个只读审查器,你可以建立这样的工作流:
这里的关键点我们已经反复强调,审查和修复是分离的两个步骤,审查器只负责发现问题。
同时,我们从评论区中得到启发,将视角从“代码是否有问题”,提升到“ 这个改动会影响谁 ”。 很多线上事故并非代码 bug,而是影响面被低估:下游链路、SLA 预算、历史事故经验没有被纳入设计判断。
因此我们引入 impact-analyzer 子代理: 只读、可审计,专注分析调用链、下游影响与 SLA 风险; 并通过 Skill 把链路拓扑与历史事故提前注入上下文。这再次印证一个核心原则: 子代理不是一开始就需要的,而是在工程痛点清晰后反推出来的设计选择。
因此,如果你愿意,我也非常鼓励你在留言区分享真实工程场景,比如:
- 有没有遇到过 “代码本身没 bug,但上线后还是炸了” 的经历?
- 有没有遇到过 AI 帮你“好心修复”,结果反而引入新问题 的情况?
- 在你们的项目里,最容易被忽略的影响面通常在哪里?数据库?缓存?下游服务?用户体验?
你不需要给出完整答案,哪怕只是一两句话的场景描述都非常有价值。我会在后续内容中,优先挑选这些真实案例,我们一起探讨、一起拆解 这个地方,值不值得一个 SubAgent?应该怎么设计它的职责和边界? 这门课并不是单向讲解,而是希望和你一起,把工程经验一步步“翻译”为可复用的 Agent 设计模式。
思考题
- 请你动手实操:进入 projects/01-code-reviewer/ 目录,在命令行中输入 “让 code-reviewer 审查 src/ 目录”,然后查看审查报告,数一数它发现了多少问题,尝试让审查器修复一个问题,观察它的行为。
- 如果要创建一个“数据库 schema 审查器”,你会配置哪些工具?它应该能“读”什么,不能“改”什么?
- 除了安全和性能,你的项目中还有哪些值得纳入自动审查的维度?
- 我在上面给出了代码审查工作流,你能否画出存量系统的设计阶段审查工作流?
下一讲我们将处理另一类重要场景: 高噪声输出任务 。我们会创建测试运行器和日志分析器两个子代理,学习如何把 500 行输出浓缩成 5 行结论。
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。