释题:纲举目张——提起渔网的总绳(纲),所有网眼(目)就自然张开。你好,我是黄佳。 上一讲我们构建一个生产级 Skill,并让 SubAgent 真正按它执行。现在你已经是一个合格的 Skill 工程师了。 但工程师和架构师的区别在于: **工程师知道怎么做,架构师知道为什么这样做。**纲举目张同时传达三层意思。
基石位置:纲 = 主绳 = 核心骨架,撤了纲整个网就散了。 能力复用:一根纲 → 无数个目,一个 Skills 标准 可以跨越多个平台。 承上启下:纲在目之上、在手之下——Skills 在 Tools 之上、SubAgents 之下。
Skills 在 Claude Code 架构中的位置
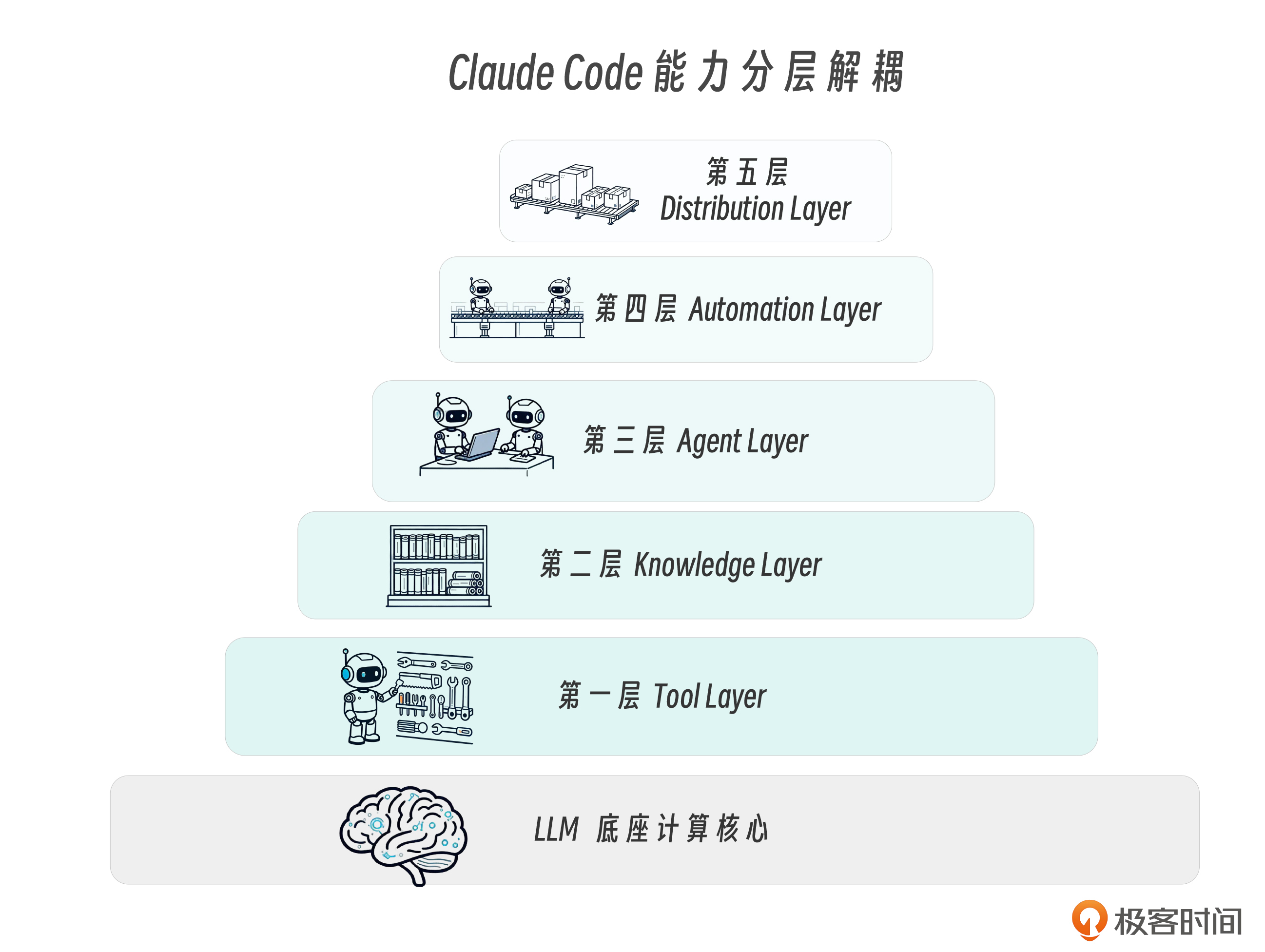
我们开篇就曾给出Claude Code 架构全景图。而课程学习到这个阶段,让我们再次站在最高处,从另一个视角去剖析Claude Code,拆解 Skills 在 Claude Code 完整架构中的位置。
如果把 Claude Code 五层架构看作一栋工程化系统大厦,可以按“能力分层解耦”的方式理解。
- LLM 是底座计算核心,相当于 CPU + Runtime,负责推理与控制循环(agentic loop)。
- 第一层 Tool Layer 是最底层的执行接口层,类似操作系统的 syscall 或基础设施 API,定义“系统可调用的原子能力”。
- 第二层 Knowledge Layer 是策略与操作规约层,Skills 本质是结构化 SOP 注入机制,解决“在什么上下文下,以什么步骤调用哪些工具”。
- 第三层 Agent Layer 是执行编排层,SubAgents 提供隔离执行单元,Agent Teams 提供多单元协作拓扑,解决复杂任务拆解与职责分离。
- 第四层 Automation Layer 是事件驱动控制层,Hooks 像 middleware 或 pipeline 拦截器,在关键节点注入自动化校验与约束逻辑。
- 第五层 Distribution Layer 是能力封装与交付层,Plugins 将前述能力模块化、版本化,实现跨项目与跨组织复用。
Skills 处于知识层这个“承上启下”的位置——工具层(能做什么)之上,智能体层(谁来做)之下。这个位置不是偶然的,它揭示了 Skills 的本质角色:
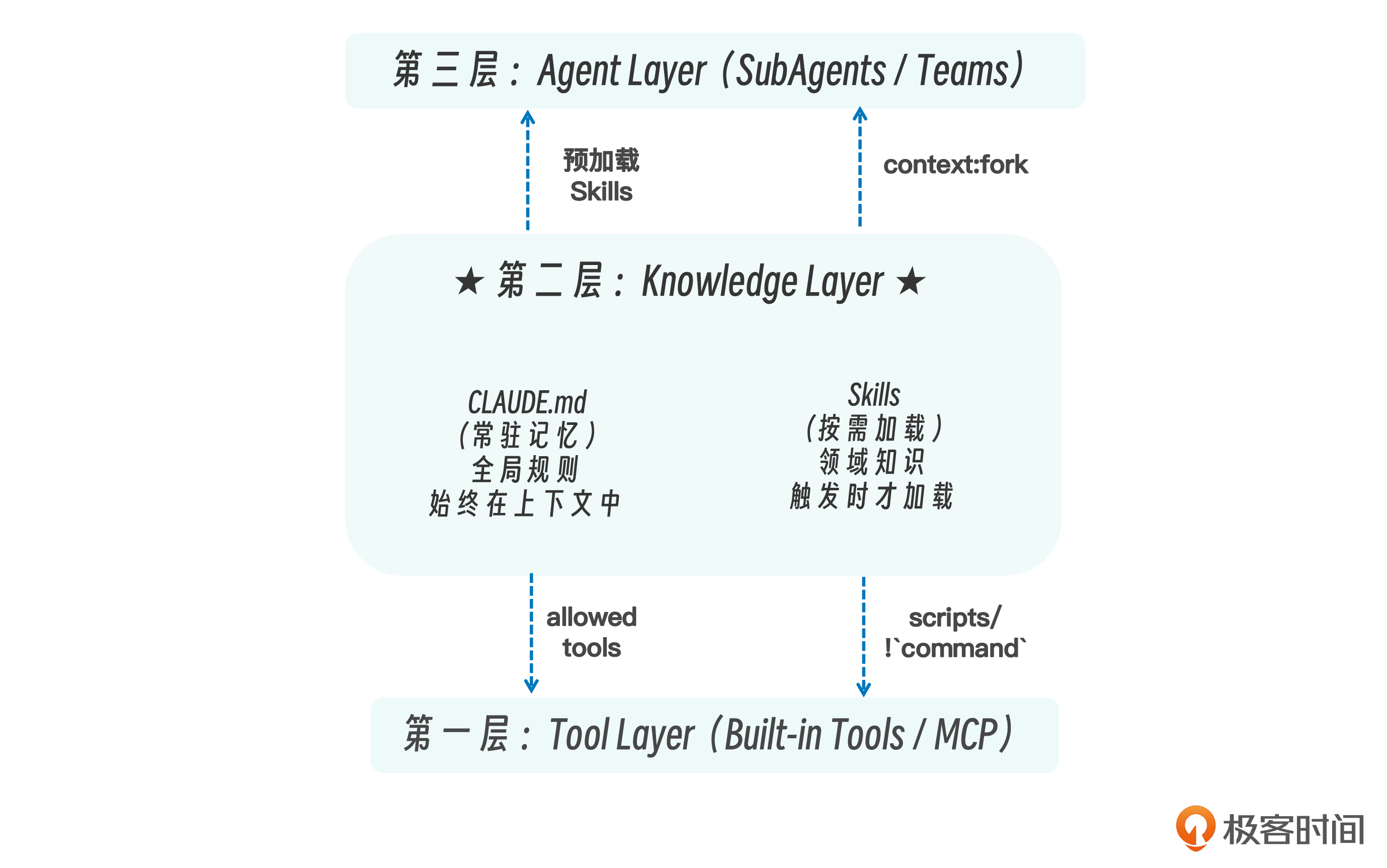
Skills 在系统中呈现出三种结构方向。
向下,它通过 allowed-tools 和 scripts/ 对 Tools 进行约束与编排,本质上是用知识来规范行动边界,相当于“知识约束行动”。向上,它为 SubAgents 提供预加载的专业知识,使子代理在决策前就具备特定领域能力,本质上是“知识服务决策”。
在平行维度上,Skills 与 CLAUDE.md 形成互补关系:Skills 是按需加载的专业知识模块,而 CLAUDE.md 是常驻的通识背景,两者分别承担“专业能力增强”和“基础认知框架”的角色。
这就是为什么 Skills 要设计成“按需加载”而非“全量加载” ——如果 Skills 像 CLAUDE.md 一样常驻,它就退化成了 CLAUDE.md 的一部分,失去了“精准投放知识”的架构优势。渐进式披露不是“省 token 的技巧”,而是 知识层架构的必然要求 。
三级进化——从 SOP 到组织智能
回顾 Skills 前几讲,我们实际上走了一条从简单到复杂的进化路径。这条路径映射到企业的知识管理成熟度。
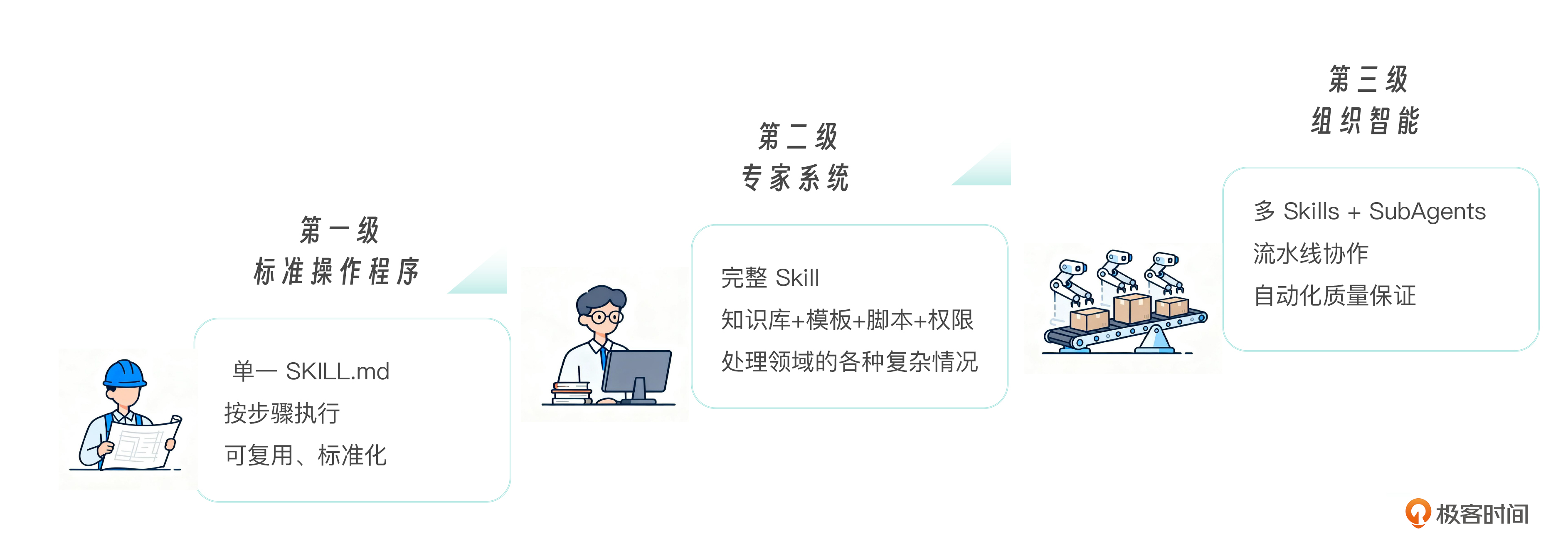
- 第一级是标准操作程序,把“个人经验”转化为“结构化执行规则”。
- 第二级是专家系统,把“流程”升级为“领域能力”。
- 第三级是组织智能,把“单点能力”升级为“系统级协同能力”。
这三级不是功能叠加,而是复杂度与抽象层级的进化。从 SOP 到专家系统,再到组织智能,是从可执行,到可扩展,再到可规模化的工程演进路径。
三级进化还不仅仅只是结构上的升级,更关键的问题是: 每一次升级到底解决了什么新的复杂性?
企业知识管理的成熟,本质上不是把文档写得更多,而是解决“规模化”“变体处理”“协作复杂度”这三类不断上升的问题。从一个人照章执行,到一个专家应对复杂情况,再到一个团队协作完成系统级任务——每往上一级,系统面对的不确定性和协作复杂度都会跃迁。因此,我们可以从“问题维度”的角度重新审视这三级演进。
具体来说,三级定位如下。
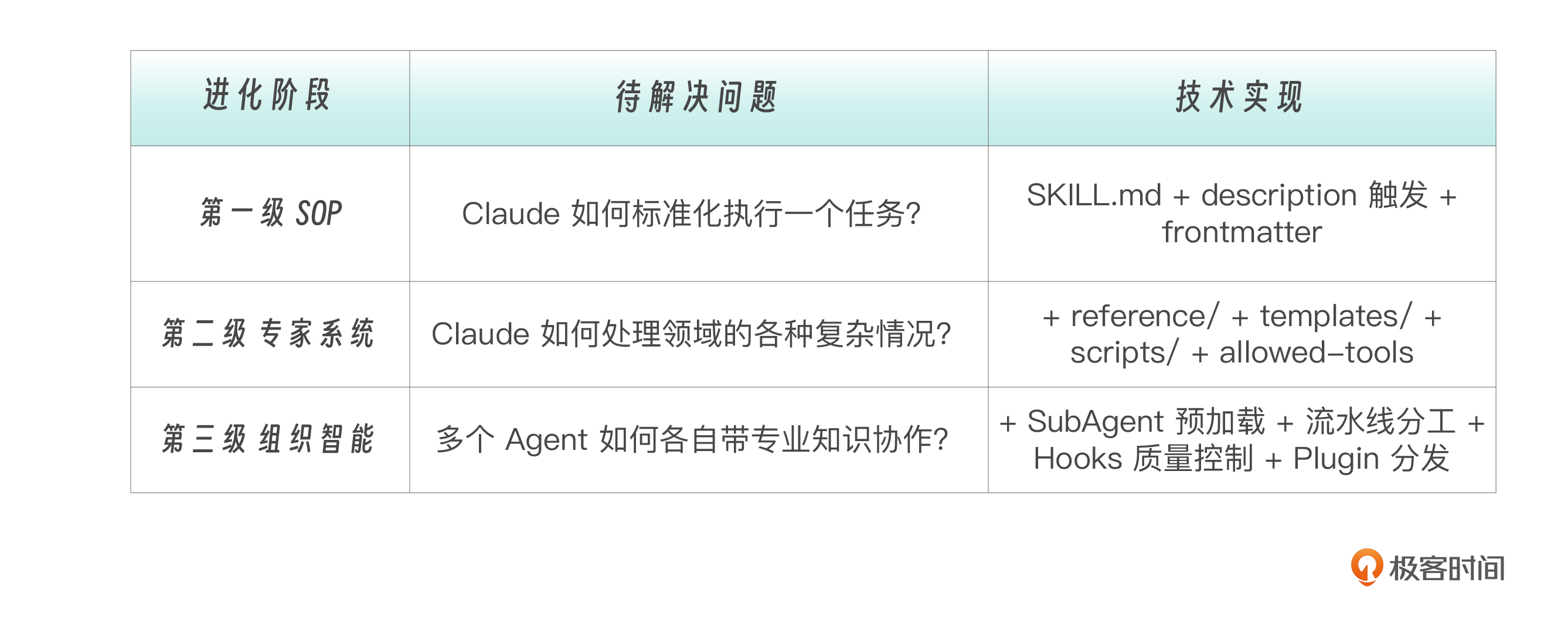
第一级是SOP阶段。 一个 Skill 解决一个标准化任务。一个单一 SKILL.md,把流程写清楚,步骤可复现,行为可预测。就像企业里新写一份操作手册——照着做就行。
第二级专家系统阶段。 在单一流程之上引入知识库、模板、脚本和权限控制,能够处理同一领域的各种复杂和边界情况。一个 Skill 通过渐进式披露组织丰富的领域知识,配合脚本和模板,成为完整的领域能力包。就像一个资深专家——不只有一份手册,还有工具箱、案例库、行业标准。
第三级上升到组织智能 。多个 Skills 与 SubAgents 配合——分析子代理加载分析 Skill、审查子代理加载审查 Skill、测试子代理加载测试 Skill——形成流水线式的团队协作。加上 Hooks 的自动化质量控制和 Plugin 的打包分发,就构成了完整的“组织智能”。就像一家成熟的企业——每个部门有自己的 SOP,部门间有标准化交接流程,质检自动化运行。
这就是 Skills 的终极价值:它不仅仅是节省 token 或给 Claude 一份参考。Skills 是把人类组织中积累了几十年的知识管理经验——SOP、专家系统、组织学习——技术化映射到 AI Agent 架构中。
那么,你的项目在哪一级?
你可以使用下面的自测清单。

大多数项目在第二级就能满足需求。佳哥要提醒大家, 不需要为了“高级”而过度设计 ——选择与问题复杂度匹配的级别。
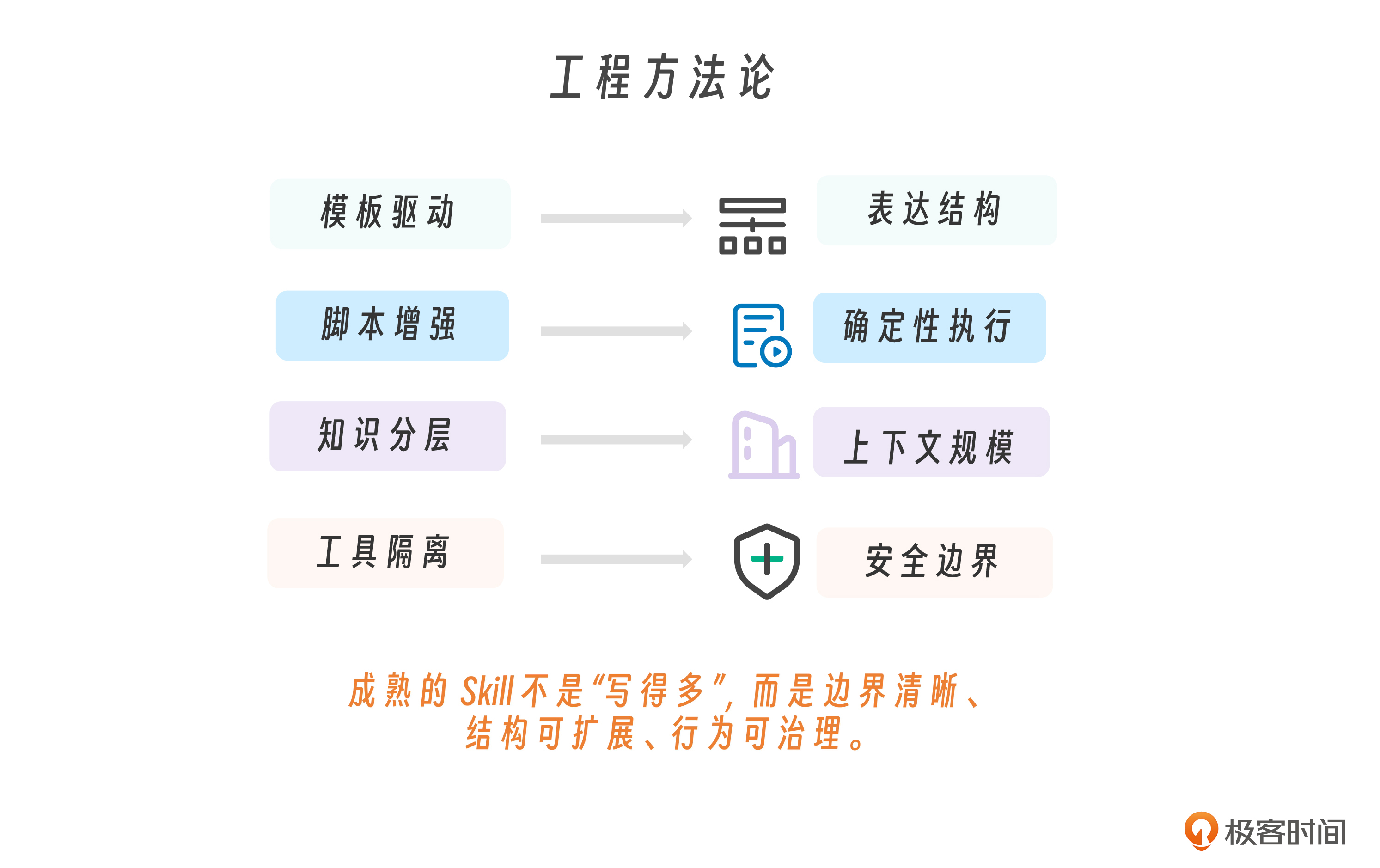
Skill 设计的四种模式
那么,在实际设计 Skill 时,有哪些经过验证的模式可以给我们一些场景应用启发?这里给出四种常见的设计模式,也可以说是典型应用场景吧。
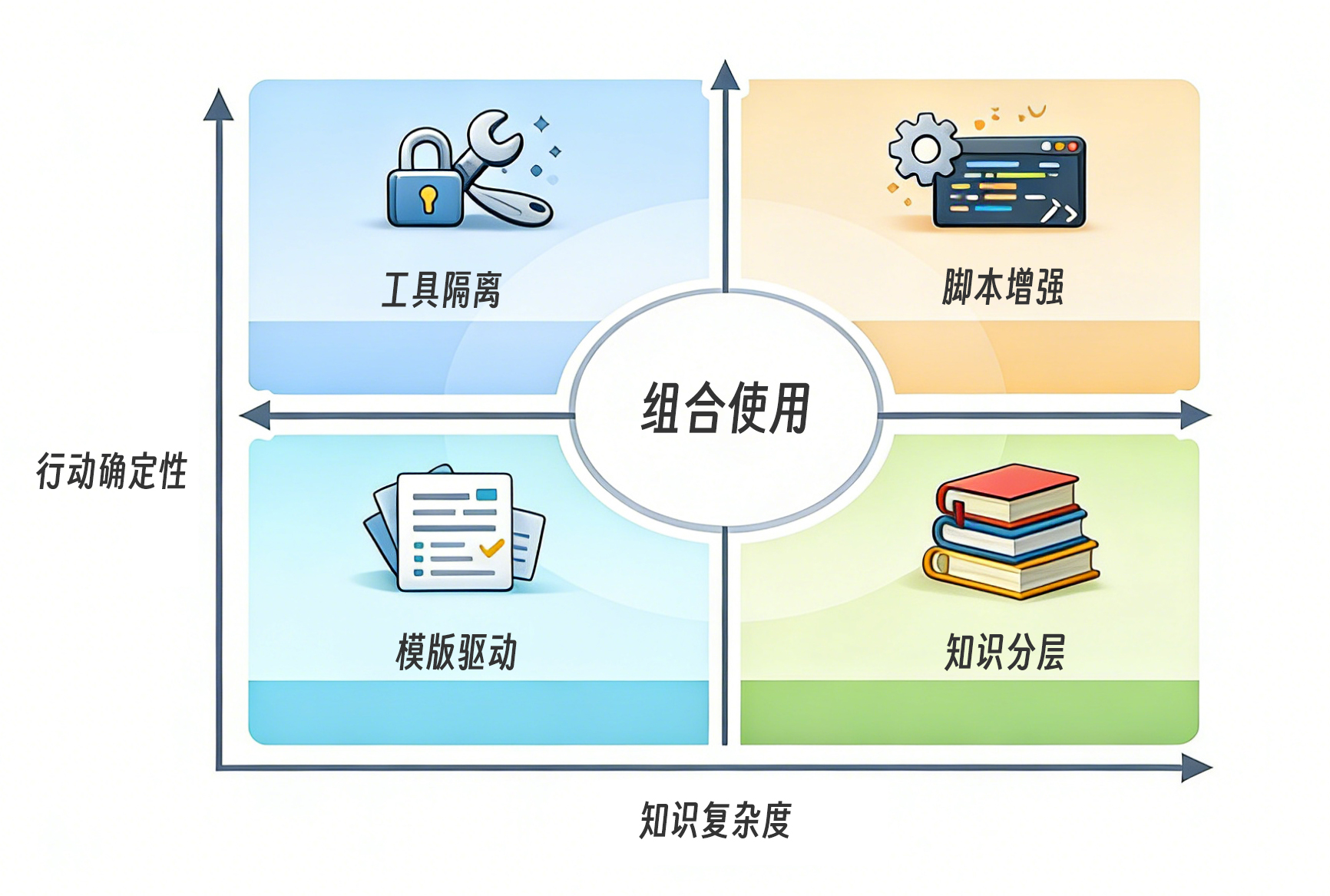
模板驱动模式
模板驱动模式核心是用模板强约束输出结构,让结果稳定、可对比、可自动解析。适用于报告生成、文档输出等需要格式一致性的场景。它解决的是“输出不稳定”的问题,本质是把自然语言生成转化为结构化接口。
.claude/skills/report-generating/
├── SKILL.md # 路由 + 流程
└── templates/
├── weekly_report.md # 周报模板
├── incident.md # 事故报告模板
└── review.md # 评审报告模板
SKILL.md 关键写法 :
## Output Rules
- ALWAYS use the template from `templates/` that matches the request type
- Fill ALL placeholders — do not leave {placeholder} unfilled
- Do NOT add sections beyond what the template defines
模板驱动的价值在于把输出格式标准化,使结果具备一致性、可比较性和可自动处理能力。它将“生成内容”与“结构定义”分离,让 Skill 更易维护,也让后续流程(例如自动汇总、比对或系统导入)更加稳定可靠。
如果模板过于复杂(例如超过 100 行),通常意味着职责混乱,应拆分为多个更小、更单一用途的模板;如果模板中开始出现逻辑判断或条件分支,说明边界被打破——逻辑应放在 SKILL.md 中,模板只负责呈现格式,不负责决策。
脚本增强模式
脚本增强模式的核心是把计算、匹配、数据转换等确定性逻辑交给脚本执行,而不是让 Claude 推理完成。适用于公式计算、正则匹配、指标统计等场景。它解决的是“结果不稳定”的问题,本质是把概率型推理替换为确定性执行。
.claude/skills/data-analyzing/
├── SKILL.md # 路由 + 流程
└── scripts/
├── parse_csv.py # 数据解析
├── calculate.py # 指标计算
└── visualize.py # 生成图表 HTML
如果你在 SKILL.md 里开始写公式,让 Claude 去计算或反复推理数值结果,那就应该停下来思考——这种确定性计算应当下沉到脚本中完成。Claude 负责判断和理解,脚本负责计算和执行。
脚本不应依赖额外的外部安装环境(例如运行时需要再执行 pip install),优先使用标准库,若确有依赖必,须在说明文档中明确声明;脚本不应包含交互式输入,必须是一次性可执行、无人工干预的流程;同时也不要把所有逻辑都塞进脚本,只有确定性、可计算、可验证的逻辑才适合放入脚本,涉及判断、语义理解或策略决策的部分应保留给 Claude 处理。
知识分层模式
知识分层模式的核心是按使用频率组织知识,高频内联,中低频按需加载。适用于规则多、领域复杂的 Skill。它解决的是“上下文膨胀”的问题,本质是通过渐进加载控制认知复杂度。
.claude/skills/security-reviewing/
├── SKILL.md # 核心检查清单(高频,~200 行)
├── QUICKREF.md # 常见漏洞速查(中频)
├── OWASP_TOP10.md # OWASP 详细标准(低频)
├── reference/
│ ├── xss.md # XSS 防护详解(按需)
│ ├── sqli.md # SQL 注入详解(按需)
│ └── auth.md # 认证问题详解(按需)
└── examples/
├── good_auth.md # 正确实现示例(按需)
└── bad_patterns.md # 反模式示例(按需)
分层策略 :
总是加载(SKILL.md 内联)
← 80% 的请求只需要这些
← 控制在 500 行以内
触发时加载(Quick Reference)
← 用户问到特定方向时加载
← 契约式引用:"When user asks about X → load Y"
按需加载(reference/ + examples/)
← Claude 判断需要时才读取
← 文件名要有描述性
这就是第 11 讲“渐进式披露“策略的直接应用 。但这里强调的不是怎么做,而是“什么时候选择这个模式”,答案是 当你的 SKILL.md 超过 500 行时 。
工具隔离模式
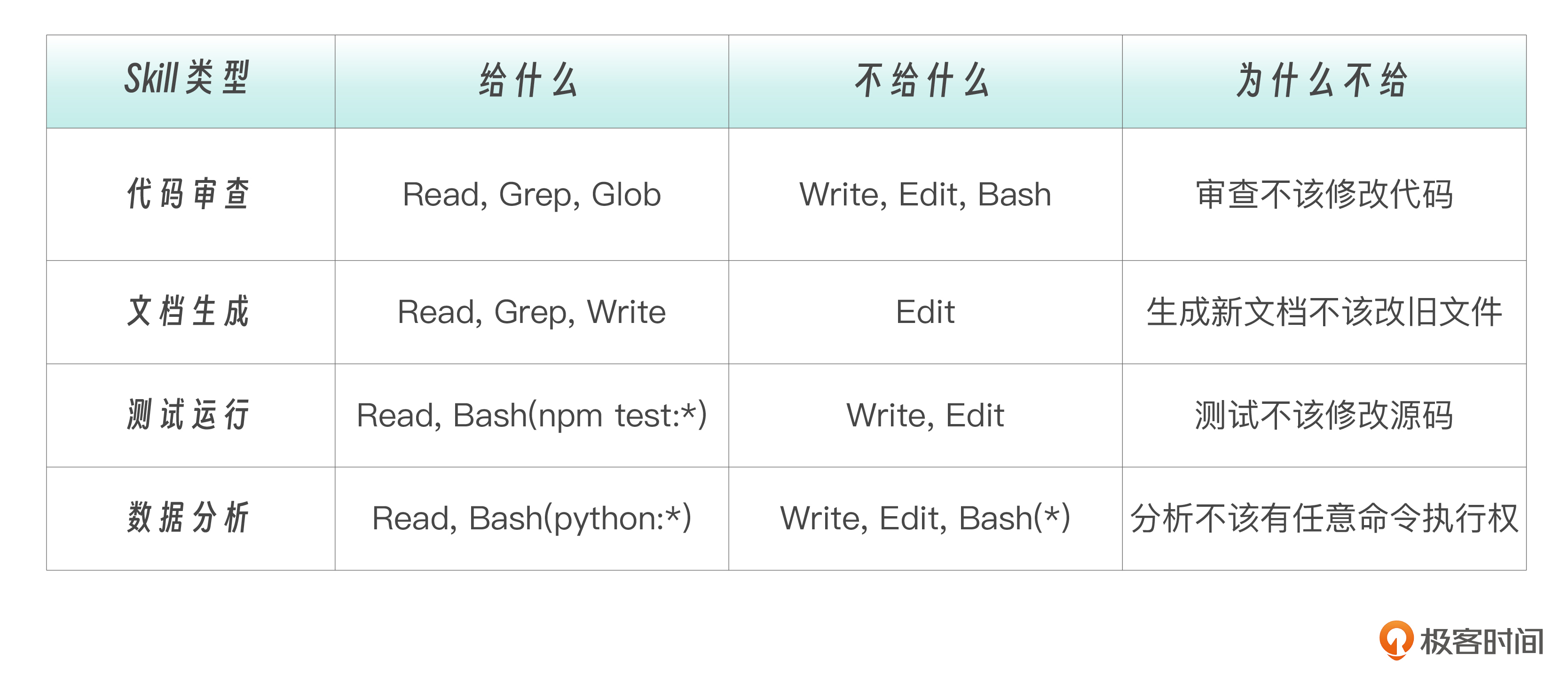
工具隔离模式的核心是通过 allowed-tools 明确能力边界,限制 Skill 可以调用的工具。适用于需要安全控制或职责划分的场景。它解决的是“越权风险”的问题,本质是把安全约束前置为结构设计。当你需要确保 Skill 不会做“不该做的事”时——这是安全设计,不是功能设计。
# 审计类 Skill:只读
allowed-tools: [Read, Grep, Glob]
# 生成类 Skill:只写不改
allowed-tools: [Read, Grep, Glob, Write]
# 分析类 Skill:只读 + 脚本
allowed-tools: [Read, Grep, Glob, Bash(python:*)]
# 执行类 Skill:受控执行
allowed-tools: [Read, Bash(npm test:*), Bash(pytest:*)]
工具隔离模式的价值不在于“能做什么”,而在于 明确“不能做什么” 。
四种模式不是互斥的——一个成熟的 Skill 通常组合使用多种模式。但理解每种模式的 核心思想和适用边界 ,能帮你在设计时做出更好的取舍。
实际的生产级 Skill 通常组合多种模式。以我们在第 12 讲构建的 API 文档生成器为例。
04-api-generator = 模板驱动 + 脚本增强 + 知识分层 + 工具隔离
├── SKILL.md ← 知识分层(路由器,500 行以内)
├── PATTERNS.md ← 知识分层(按需加载)
├── templates/endpoint.md ← 模板驱动(标准化输出)
├── scripts/detect.py ← 脚本增强(确定性路由检测)
└── allowed-tools ← 工具隔离(Write 但不给 Edit)
组合决策树 :
你的 Skill 需要……
│
├─ 标准化输出格式? → 加 templates/(模板驱动)
├─ 确定性计算/匹配? → 加 scripts/(脚本增强)
├─ 知识量 > 500 行? → 拆分 reference/(知识分层)
└─ 安全边界控制? → 配置 allowed-tools(工具隔离)
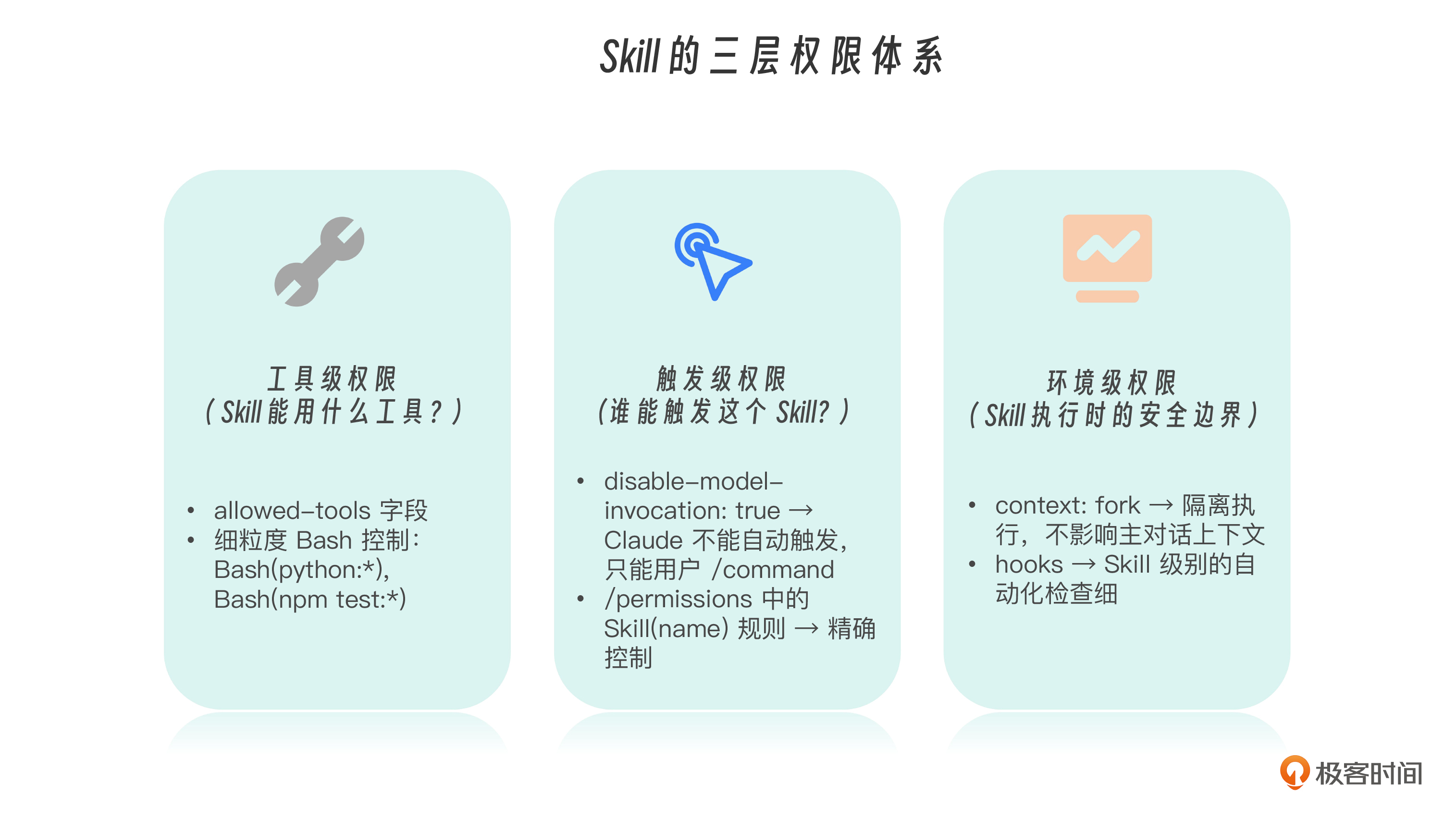
权限体系与安全设计
在能力不断增强的同时,一个问题开始变得不可回避: 当 Skill 变成组织级能力时,如何确保它“强大而不失控”?我们逐级来看。
- 在第一级 SOP 阶段,风险很小——它只是执行固定步骤。
- 在第二级专家系统阶段,Skill 已经可以调用多种工具、加载大量知识。
- 到了第三级组织智能阶段,多个 Skills 与 SubAgents 协作,自动触发、流水线运行,如果没有清晰的权限分层,系统很容易出现“能力越强,风险越大”的问题。
因此,Skill 的权限设计不是附加功能,而是组织智能能够落地的前提。
权限设计本质上是在回答三个问题:
- 这个 Skill 能做什么?
- 这个 Skill 什么时候能被触发?
- 这个 Skill 在什么边界内运行?
这三问,构成了完整的 Skill 三层权限体系。
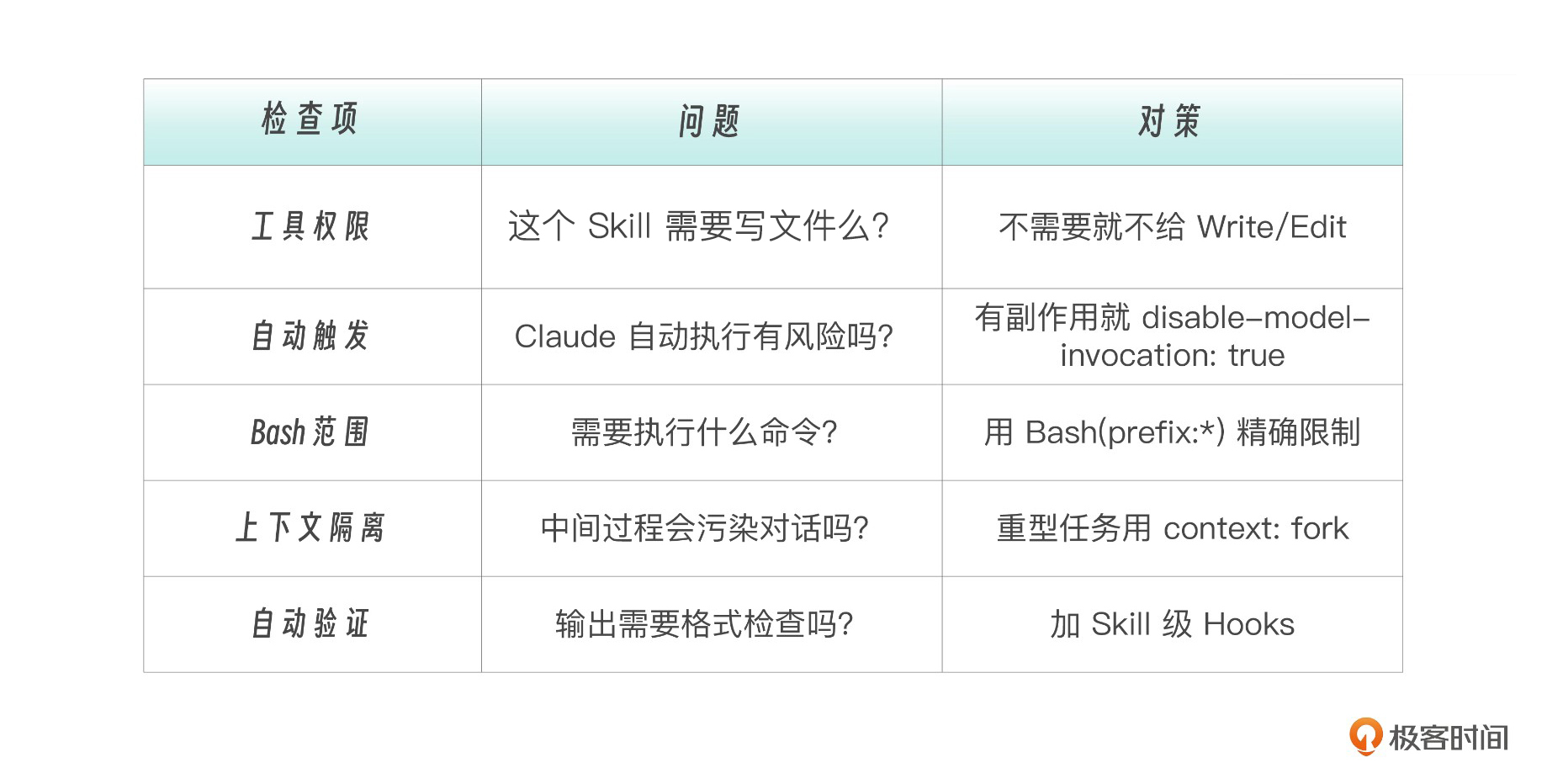
设计一个生产级 Skill 时,建议按照 Skill 安全设计清单逐项检查。我为你做了一个参考表格。
本讲小结
本讲真正讨论的,不是“如何写一个 Skill”,而是 如何让组织知识在 AI 系统中有序存在 。
从 Claude Code 的五层架构来看,Skills 位于知识层的核心位置——向下约束工具能力,向上服务智能体决策,与 CLAUDE.md 构成常驻认知与按需专业知识的双轨体系。它不是简单的提示封装,而是“知识如何进入系统”的架构接口。
从企业本体论来看,Skills 是组织 SOP、专家经验与协作流程的技术化映射。我们看到了一条清晰的演进路径:
- SOP 解决可执行问题,
- 专家系统解决复杂变体问题,
- 组织智能解决规模协作问题。
每一次升级,本质上都在应对更高阶的不确定性与协作复杂度。
从工程方法论来看,四种设计模式——模板驱动、脚本增强、知识分层、工具隔离——分别控制表达结构、确定性执行、上下文规模与安全边界。它们不是技巧,而是职责分离的体现。成熟的 Skill 不是“写得多”,而是边界清晰、结构可扩展、行为可治理。
从安全治理角度看,三层权限体系(工具级、触发级、环境级)明确回答了三个问题:
- 能做什么?
- 谁能触发?
- 在什么边界内运行?
当 Skill 升级为组织级能力时,权限设计不再是附加项,而是架构前提。
因此,Skills 的终极意义,不在于节省 token,也不在于提示工程的精细化,而在于—— 它是 AI 系统中的“知识总纲”。 提起这一根纲,工具层的约束、智能体层的知识注入、自动化层的质检,自然各就各位,形成真正可规模化的组织智能 。
当你理解了这一点,你已经不只是 Skill 工程师,而是在设计一个可治理、可演进、可扩展的 AI 组织系统。
思考题
- 设计一个 PR 审查 Skill:使用
context: fork+!command+ Skill 内 Hooks。画出完整配置,说明!command预加载什么数据、context: fork选择什么 agent 类型、Hooks 在何时做什么检查。 - 用“企业本体论映射”分析你当前项目:你的 CLAUDE.md 是“企业文化”吗?你的 Skills 是SOP吗?你的 SubAgents 是“团队成员”吗?如果映射不通,说明你的架构可能有设计问题——找出来。
- 评估你的项目处于“三级进化”的哪一级。如果要向上一级进化,你需要增加什么组件?成本是否值得?
- 为你项目中的一个 Skill 选择设计模式组合:用“组合决策树“判断需要哪些模式,画出最终的目录结构。
下一讲预告
我们的学习已经从“怎么造 Skill”上升到为什么这样造“”。但故事还没结束——Skills 已经不仅仅是 Claude Code 的功能了。
2025 年 12 月,Anthropic 把 Skills 发布为开放标准。4 个月内,OpenAI Codex、Google Gemini CLI、GitHub Copilot、Cursor 等 27+ 平台相继采纳。Vercel 推出了 skills.sh 包管理器,52,000+ Skills 被注册。
下一讲,我们将走出 Claude Code,看看 Skills 如何 星火燎原 ——从一个产品特性变成行业开放标准,以及这对你作为 AI 工程师意味着什么。
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。