释题:真相大白。2026 年 3 月 31 日,Anthropic 在发布 Claude Code v2.1.88 时,因 `.npmignore` 配置疏忽(主流推测),将一份 59.8MB 的 source map 文件随 npm 包一同发布。这份文件映射了完整的原始 TypeScript 源码——1,900 个文件,512,000 行代码。数小时内,源码被全网镜像,GitHub fork 超过 41,000 次。我们从第一讲起,就在黑箱外推测的那些架构设计,现在全部真相大白。你好,我是黄佳。 昨天(2026年 3 月 31 日),有人发现 `@anthropic-ai/claude-code` 的 v2.1.88 npm 包中包含了一个不该出现的文件——`cli.js.map`。这是一份 **source map** ,本用于内部调试,它能将编译后的混淆代码精确映射回原始的 TypeScript 源文件。 Anthropic 随后撤下了该版本,发表声明“这是一个由人为失误导致的打包问题,不涉及安全漏洞,不涉及客户数据或凭证”。但为时已晚——源码已被多个 GitHub 仓库镜像存档。  这不是一次“黑客攻击”。这是一次 **工程事故** ——一个 `.npmignore` 配置的疏忽。但它对我们的课程来说,是一次极其珍贵的验证机会。 从第1讲(全景认知)到最新的第18讲(工具系统),我们一直在黑箱外推测 Claude Code 的内部架构——通过官方文档、行为观察、API 分析来还原它的设计逻辑。现在,源码摊在了面前。 **我们的推测对了多少?有哪些出乎意料的发现?对 Harness 工程有什么新的启示?** 这一讲不是事件报道,而是 **架构验证** 。我把源码中最重要的发现,逐一映射回我们课程中讲过的每个模块。 泄露的规模与结构有多大,我们先看数字: 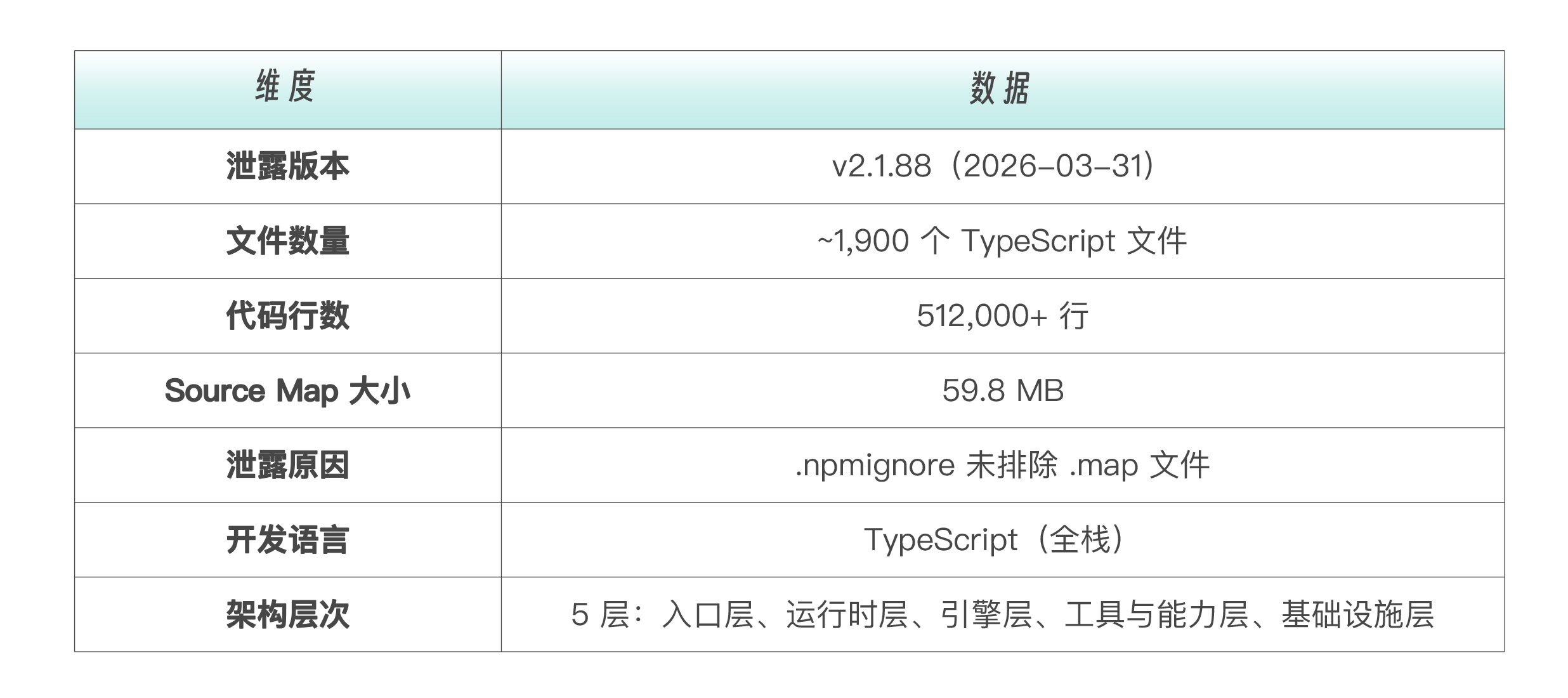 下面,我们从源码的级别来拆解,也借助Claude Code本身的强大代码分析功能,与课程一一对照。我总结出了10大发现。(除了这篇加餐,4月2日我也应极客时间邀请做了一场“拆解 Claude Code 源码中的企业级 AI 落地密码”的直播,直播回放链接在这里 https://live.geekbang.org/room/2508 )
一、Claude Code 的确是五层架构式设计
我们课程第一讲中就指出Claude Code 不是“一个 CLI 工具”,——它是一个 平台运行时 ,终端 CLI 只是它的入口之一。同一个引擎核心驱动着桌面 App、Web 客户端、IDE 扩展和编程 SDK。
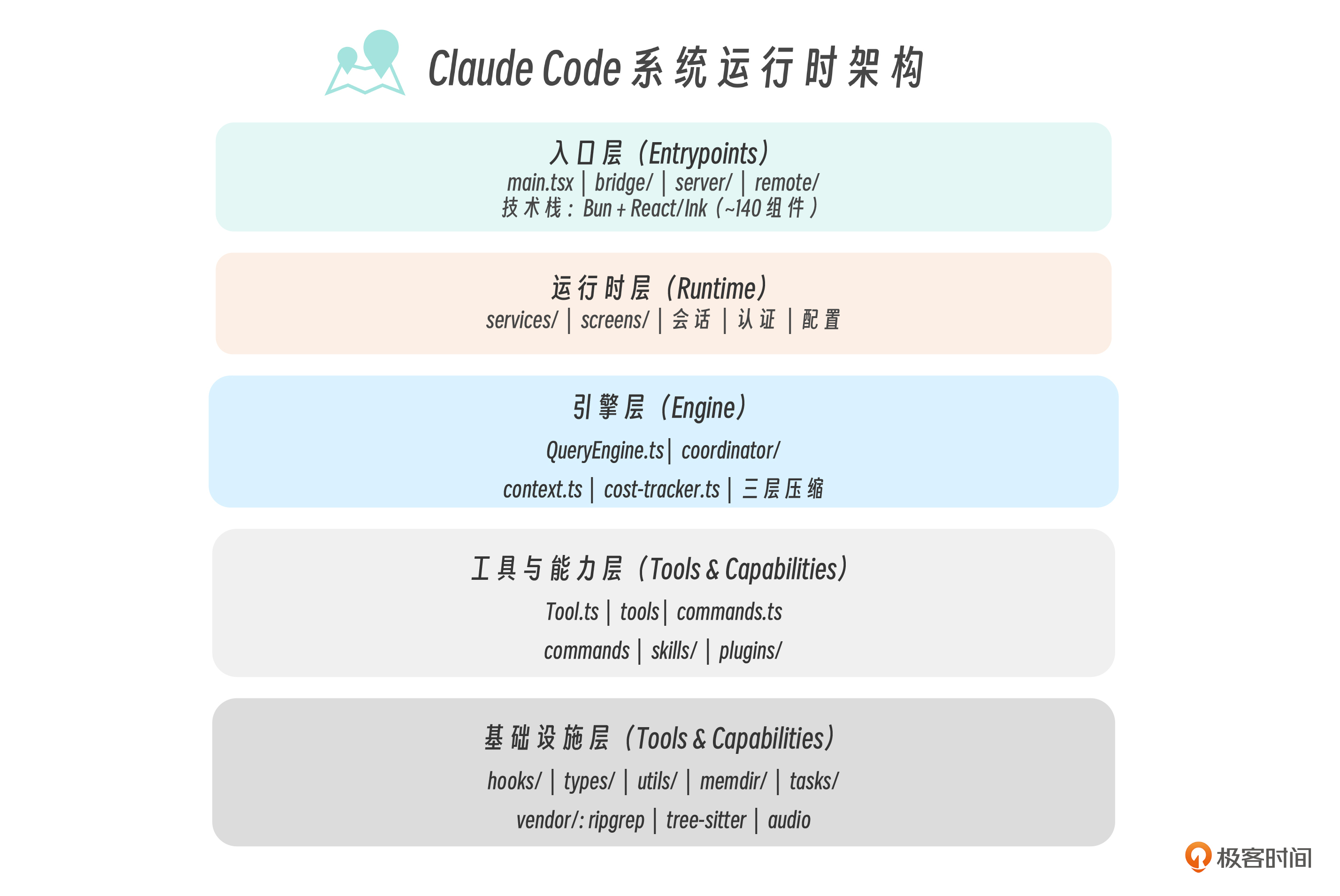
我们课程第一讲的架构图是基于行为观察和文档推断画出来的。现在源码的目录结构给出了最直接的证据——四个独立入口模块、140 个 UI 组件、三个预编译原生二进制。这个定位完全正确。直接把源码目录结构摊开,可以逐层验证:
src/
├── main.tsx ← 入口层:Commander.js CLI 解析 + React/Ink 渲染
├── bridge/ ← 入口层:IDE 集成桥接(VS Code / JetBrains)
├── server/ ← 入口层:Server 模式(供桌面 App / Web 调用)
├── remote/ ← 入口层:远程会话
│
├── services/ ← 运行时层:外部服务集成
├── screens/ ← 运行时层:全屏 UI(认证、配置等)
├── components/ ← 运行时层:~140 个 Ink UI 组件
│
├── QueryEngine.ts ← 引擎层:46KB(约 1,200 行),LLM 调用 / 流式 / 缓存 / 编排
├── coordinator/ ← 引擎层:多 Agent 编排(Coordinator Mode)
├── context.ts ← 引擎层:系统/用户上下文收集
├── cost-tracker.ts ← 引擎层:Token 消耗追踪
│
├── Tool.ts ← 工具层:29KB(约 800 行),所有工具类型定义 + 权限 Schema
├── tools/ ← 工具层:~40 个工具实现
├── commands/ ← 工具层:~85 个斜杠命令,25K 行
├── commands.ts ← 工具层:命令注册中心
├── skills/ ← 工具层:技能系统
├── plugins/ ← 工具层:插件系统
│
├── hooks/ ← 基础设施层:React Hooks(含权限检查)
├── types/ ← 基础设施层:TypeScript 类型定义
├── utils/ ← 基础设施层:工具函数
├── memdir/ ← 基础设施层:持久化记忆目录
└── tasks/ ← 基础设施层:任务管理
当然我们低估了工程化的程度:85 个命令、40 个工具、25K 行命令注册代码——这是一个 重度工程化的产品级系统 所应该有的。
我的Claude Code告诉我, 基于此,咖哥你就应该相信这次泄露是真实的 。
我们先看几个架构中最关键的部分。
技术栈选型——Bun + React/Ink。 Claude Code 运行在 Bun 而非 Node.js 上(Anthropic 在 2026 年 3 月收购了 Bun 的母公司 Oven),终端 UI 用了 React + Ink 框架——本质上是用 React 组件树渲染终端文本界面。components/ 目录下有约 140 个 Ink 组件——这个数量级说明 Claude Code 的终端交互绝不是简单的 readline 命令行,而是一个完整的 声明式 UI 应用 。我们课程中一直把 Claude Code 称为终端工具,这从技术精确性上低估了它。
入口层的分离架构。 main.tsx、bridge/、server/、remote/ 四个入口模块相互独立,但共享下面四层。这意味着,IDE 扩展通过 bridge/ 接入时,走的是和 CLI 一模一样的 QueryEngine、同一套工具权限、同一套上下文管理。 不是 IDE 版是阉割版——是同一个引擎的不同门面。
vendor/ 目录暗藏的“原生依赖”。 本地包中 vendor/ 目录包含了三个预编译二进制:ripgrep(代码搜索)、tree-sitter-bash(Bash AST 解析)、audio-capture(语音输入)。这说明 Claude Code 的 Grep 工具底层调用的是 ripgrep ——Rust 写的高性能搜索工具,不是 Node.js 的文本匹配。这解释了为什么 Claude Code 搜索大型代码库时那么快。tree-sitter-bash 则用于在执行 Bash 命令前做语法解析——可能是权限检查和安全分析的一部分。
下面是从代码中分析出来的Claude Code的真实系统架构,和我们之前的拆解的确有很多不谋而合之处。—— 当然,我们之前是从使用者的角度拆解,这个则是实打实的系统运行时架构。
二、QueryEngine:18 讲里的 Agentic Loop,源码里叫什么?
第 18 讲 梳理 Tools 工具系统 时 , 我们定义了 Agentic Loop 的核心模式——“推理 → 工具调用 → 结果回注 → 继续推理”。我们推测 Claude Code 用的是 “dumb loop, smart model” 的设计——循环本身极简,所有智能交给模型。
源码启发 :如果我们看看Claude Code的源码,会发现业界对 Agentic Loop 核心模式的解读完全正确。不过, 源码实际上比我们描述得更精巧 。
源码中这个循环的核心不叫AgentLoop——叫 QueryEngine 。它是整个系统最大的单一模块, 46,000 行 TypeScript 。QueryEngine 是一个单例(singleton),拥有一个 mutableMessages 数组—— 整个对话的唯一真相来源(single source of truth) 。
循环的核心实现用了 generator 模式 :
// 概念性伪代码,基于泄露源码的架构分析
async function* agentLoop(messages: Message[]): AsyncGenerator<Event> {
while (true) {
const response = await queryLLM(messages);
for (const item of response.items) {
if (item.type === 'text') {
yield { type: 'text', content: item.text };
}
if (item.type === 'tool_use') {
// 权限检查
const approved = await checkPermission(item.tool, item.input);
if (!approved) continue;
// 执行工具
const result = await executeTool(item.tool, item.input);
messages.push({ role: 'tool_result', content: result });
yield { type: 'tool_result', tool: item.tool, result };
}
}
if (!response.hasToolCalls) break; // 无工具调用 = 结束
}
}
Generator 模式 相比传统的 while 循环或状态机,有哪些好处呢?
- 天然的流式输出 ,
yield每产生一个事件就推给 UI。 - 中断是干净的 ,用户按 Ctrl+C,generator 直接 return,无需清理状态机。
- 预算控制是平凡的 ,在 yield 之间检查 Token 消耗,超预算直接 return。
- 工具调用是递归的 ,子代理可以嵌套自己的 generator。
和先前的课程对照一下,我们在第 18 讲把这个循环讲对了,但漏掉了 generator 模式这个实现细节。这是一个值得补充的工程模式——如果你自己要实现 Agentic Loop,generator 比 while + state machine 更优雅。

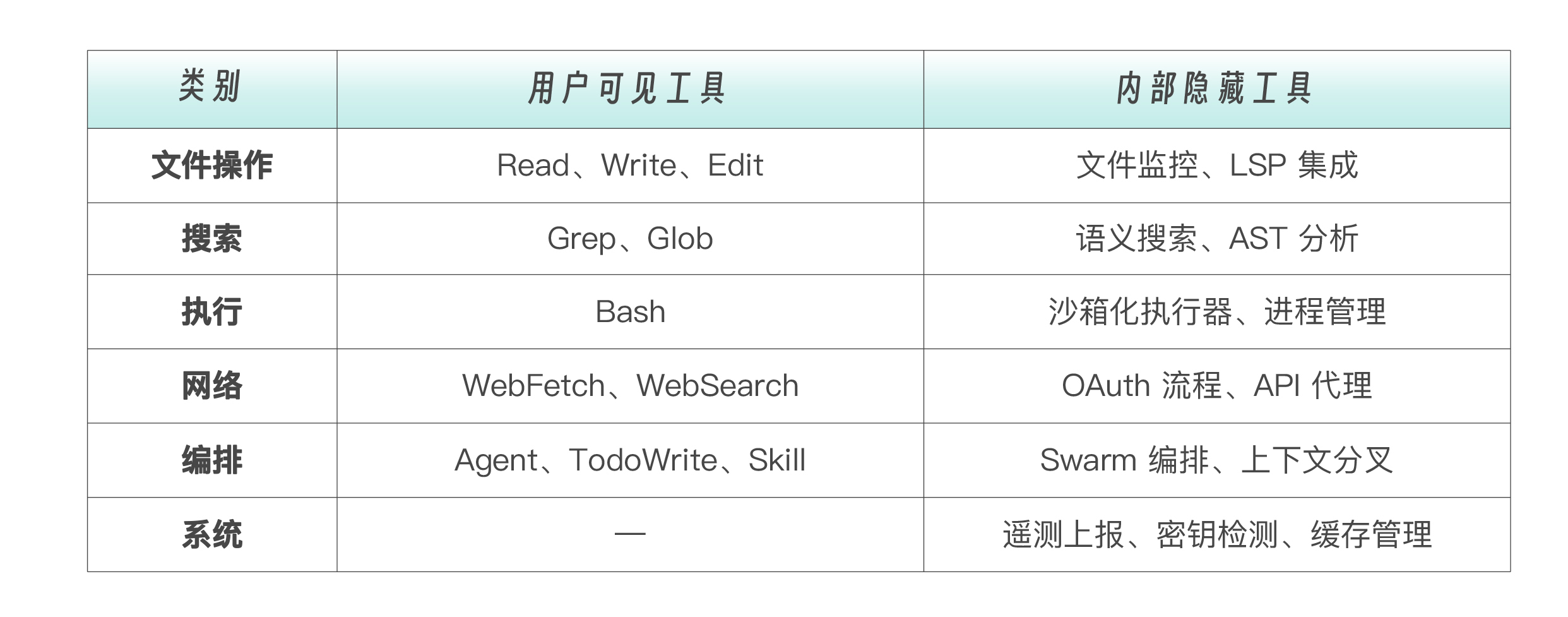
三、40 个工具:被严重低估的工具规模
我们说 Claude Code 内置了约 15 个工具,覆盖五个原子操作(读、写、执行、联网、编排)。我们强调了“少而精”的设计哲学。
源码启发:实际有约 40 个工具。 我们当时统计的 15 个,只是用户可见的工具。源码中还有大量 内部工具 不对外暴露。
源码揭示的工具分类如下表:
每个工具都是一个 离散的、权限门控的插件 。工具定义不是简单的函数签名——每个工具包含以下内容。
- JSON Schema 的参数定义
- 权限需求声明(哪些权限级别可以调用)
- 风险等级标注(是否需要用户审批)
- 输出格式规范(返回给模型的数据结构)
- 错误处理逻辑(重试策略、降级方案)
工具定义这么长,不是因为工具逻辑复杂,而是因为每个工具的 安全边界定义 极其详尽。这印证了一个工程经验, 功能代码和安全代码的比例大约是 1:3。 实现一个工具可能 200 行,但定义它的权限边界、错误处理和输出规范需要 600 行。
“少而精”的哲学仍然成立——40 个工具中,用户直接交互的确实只有十几个。其余都是支撑性的内部工具,服务于安全、监控和系统管理。第 18 讲给出的“五个原子操作”的分类框架是对的,但规模严重低估了。
四、上下文工程:Sebastian Raschka 说“真正的秘密武器不是模型”
Sebastian Raschka(《Build a Large Language Model From Scratch》作者)在泄露当天发表了一篇分析文章,标题直接点出了核心洞察: Claude Code’s Real Secret Sauce Isn’t the Model.
源码验证了他的判断。Claude Code 在上下文构造上做了至少五项精密优化,这些优化解释了为什么同一个 Claude 模型在 Web UI 和 Claude Code 中表现天差地别。
优化一:Git 上下文自动加载。
每次提示构造时,Claude Code 自动注入当前 Git 分支名、主分支名、最近的 commit 记录和 diff。模型不需要你告诉它“你在哪个分支上”——Harness 已经替你说了。这就是为什么 Claude Code 能自然地执行 git checkout -b feature/xxx 而 Web UI 做不到。
优化二:静态/动态内容分界标记。
提示词中有一个 boundary marker ,将静态内容(系统指令、工具定义、CLAUDE.md)和动态内容(对话历史)分开。静态部分走全局缓存——和 Codex CLI 的 Prompt Caching 策略异曲同工,但 Claude Code 在客户端就做了分界,而不是依赖 API 端推断。
优化三:文件读取去重。
如果你在一次会话中多次读取同一个文件且文件未变,Claude Code 不会重复将内容塞入上下文。它在客户端做了 内容哈希去重 ——只有文件内容发生变化时才重新加载。
优化四:大结果落盘。
当工具返回结果超过一定大小(比如 grep 搜出了几千行)时,Claude Code 不会把完整结果塞进上下文——它把完整结果 写入临时文件 ,上下文中只保留一段 摘要预览 + 文件引用路径 。模型可以在需要时通过 Read 工具读取完整内容。
优化五:LSP 集成。
源码中有一个 LSP(Language Server Protocol)工具——这是我们在课程中完全没提到的。LSP 让 Claude Code 能做 语义级的代码理解 :定义跳转、引用查找、调用层次分析。
这不是 grep 的文本匹配能替代的,grep "functionName" 会匹配注释和字符串,LSP 只匹配真正的符号引用。
上下文构造流程:
Git 信息(分支、commit)──→ ┐
CLAUDE.md(项目规则)───→ │
系统提示词 + 工具定义──→ ├→ 静态区域(缓存)
│ ↓ boundary marker
对话历史(去重后)────→ ├→ 动态区域
工具结果(大结果落盘)──→ ┘
这五项优化中,“大结果落盘”最值得学习。很多人用 Claude Code 时遇到过“上下文爆了”的问题——原因往往是一次 grep 搜出了太多结果。源码告诉我们, Claude Code 已经在做结果裁剪了——如果你还遇到上下文不够用,说明你的搜索条件太宽泛,不是工具的问题。
另外,LSP 集成解释了一个长久以来的疑问:为什么 Claude Code 在处理大型 TypeScript 项目时特别准?因为它不只是在文本搜索,它在用编译器级别的语义理解。
五、Self-Healing Memory:远比预期复杂的记忆系统
第 2 讲 CLAUDE.md 记忆系统里, 我们讲了三级记忆体系——用户级、项目级、本地级。CLAUDE.md 是核心载体。 源码揭示了“自愈式记忆”(Self-Healing Memory)架构,这是我们完全没预料到的,值得我们仔细琢磨一下。 三层结构:
第一层:MEMORY.md(轻量索引)
└── 每条记忆只有一行指针(~150 字符)
└── 永远加载在上下文中
└── 是"目录",不是"内容"
第二层:Topic Files(主题文件)
└── 实际的记忆内容存在独立文件中
└── 按需加载,不一次性塞入上下文
└── 类似数据库的"索引 + 数据页"分离
第三层:Raw Transcripts(原始记录)
└── 对话原文从不完整回读
└── 只通过 grep 检索特定标识符
└── 类似日志系统的"只写不全读"
“自愈”体现在哪里? 源码中有一条关键规则叫“Strict Write Discipline”——Agent 只有在成功写入文件 之后, 才更新 MEMORY.md 索引。如果写入失败,索引不更新,这避免了“索引指向不存在的内容”的一致性问题。 这本质上是数据库中的 write-ahead logging(WAL) 的逆向——先写数据,再写索引,确保索引永远指向有效内容。 我们在第 2 讲把 CLAUDE.md 讲成了记忆的载体。而源码告诉我们,CLAUDE.md 更准确地说是 “记忆的索引” 。实际内容分散在 topic files 中。 这种设计解决了重要问题, CLAUDE.md 太大了怎么办? (一个我们在课程中提到,但没有深入的问题) 答案是控制 MEMORY.md 的大小(~200 行,每行 150 字符),让它永远装得进上下文,具体内容按需加载。
六、权限系统:44 个 Feature Flag 和“从不信任”的设计哲学
课程里,我们探讨了 deny → allow → ask 的评估顺序,讲了四级配置层次(Managed → User → Project → Local),也讲了“deny 不可被低级别覆盖”的安全原则。这部分内容对应第18讲权限控制,还有即将发布的第 20 讲 Rules规则系统。
源码验证之后,这些分析全部正确,但深度远超预期。
源码中最引人注目的安全设计是 44 个 feature flag 。这些不是“未来功能的占位符”——它们是 已经完整实现、编译在代码中、但在外部构建时编译为 false 的功能。
其中最重要的一个叫 KAIROS ,它出现了 150+ 次。
KAIROS 是什么?
KAIROS 是一个守护进程模式 。当前的 Claude Code 是“被动响应式”的——你输入命令,它执行。KAIROS 让 Claude Code 变成一个 始终在线的后台 Agent 。它包含一个叫 autoDream 的进程:在用户空闲时,Agent 自动进行“记忆整合”——合并分散的观察、消除逻辑矛盾、将模糊的洞察转化为确定性事实。
这意味着 Anthropic 正在构建一个 从工具到助手到守护进程 的进化路径。我们的课程停留在“工具”阶段,KAIROS 代表的是下一个阶段。
还有另一个发现值得关注, 32 个构建标志和 120+ 个内部环境变量 。这些环境变量控制着从模型选择到缓存策略到遥测级别的一切。其中一些变量名暗示了未发布的能力——比如涉及一个内部代号为 Capybara 的模型家族(Claude 4.6 的变体),代码中甚至用 String.fromCharCode 编码这个名字,以避免触发内部的泄露检测器。
我原先梳理的权限体系虽然正确,但源码揭示了一个更深层的设计哲学: Claude Code 对自身代码的安全防护和对用户代码的安全防护一样严格。
Feature flag 编译为 false、模型代号用字符编码隐藏、环境变量用前缀分类——这些都是“从不信任”(zero trust)思维在代码层面的体现。

七、反蒸馏机制:用“假工具”投毒竞争对手的训练数据
这是泄露中最具战略意义的发现。
源码的 claude.ts 文件中(约第 301-313 行),有一个标志叫 ANTI_DISTILLATION_CC。当启用时,Claude Code 在 API 请求中发送 anti_distillation: ['fake_tools']——这告诉服务端 在系统提示词中静默注入虚假的工具定义 。
这是什么意思?如果有人在 录制 Claude Code 的 API 流量 (比如通过中间人代理截获请求和响应),用这些数据来训练竞品模型——那些虚假工具定义就会 污染训练数据 。竞品模型会学到不存在的工具,在推理时产生幻觉。
正常请求:
tools: [Read, Write, Edit, Bash, Grep, Glob, ...] ← 真实工具
开启反蒸馏后的请求:
tools: [Read, Write, Edit, Bash, Grep, Glob, ...,
FakeToolA, FakeToolB, FakeToolC] ← 注入假工具
anti_distillation: ['fake_tools'] ← 服务端标记
这个功能受 GrowthBook feature flag (tengu_anti_distill_fake_tool_injection)控制,只在第一方 CLI 会话中激活。
源码中还有 第二层反蒸馏机制 ,betas.ts 中的“connector-text summarization”。开启后,API 会将 Claude 在工具调用之间的中间文本进行摘要化处理,并附上 加密签名 。即使有人截获了流量,拿到的也是摘要而非原始推理过程。
这在我们的课程中完全没有涉及——因为这不是面向用户的功能,而是面向 竞争对手 的防御。但它揭示了一个重要的工程视角: Harness 不仅是用户和模型之间的桥梁,也是 IP 保护的前线。 工具定义、系统提示词、推理中间过程——这些是 Harness 层的核心 IP。反蒸馏机制说明 Anthropic 把 Harness 视为 必须保护的商业秘密 。
讽刺的层次又加深了——Anthropic 精心设计了反蒸馏机制,来保护 Claude Code 的工具定义,结果因为一个 .npmignore 的疏忽,把包含反蒸馏代码在内的全部源码都泄露了。假工具可以防住 API 层的窃取,但防不住 npm 层的意外发布。安全是一个系统问题,不是一个层的问题。
八、挫败检测:用正则表达式读懂你的情绪
源码中的 userPromptKeywords.ts 暴露了一个出人意料的功能: 用户挫败感检测 。
具体实现是一条正则表达式:
/\b(wtf|wth|ffs|omfg|shit(ty|tiest)?|dumbass|horrible|awful|
piss(ed|ing)? off|piece of (shit|crap|junk)|what the (fuck|hell)|
fucking? (broken|useless|terrible|awful|horrible)|fuck you|
screw (this|you)|so frustrating|this sucks|damn it)\b/
这条正则匹配了英语中最常见的挫败和愤怒表达——从轻微的 damn it 到重度的 fuck you。匹配结果被记录到分析系统,标记为 tengu_input_prompt 事件的 is_negative 布尔值。
同时还有一个 is_keep_going 布尔值——检测用户是否在失败后仍坚持继续(比如try again、keep going)。两个信号组合,让 Anthropic 可以构建 用户满意度仪表盘 ,分析哪些功能让用户“骂街”?哪些场景让用户在失败后仍然愿意继续尝试?
社区对此的讨论很有意思—— 为什么一家拥有世界上最好的语言模型的 AI 公司,用正则表达式来检测用户情绪?
答案很工程化,一条正则表达式的执行成本是 纳秒级 的,而调用一次 LLM 来做情感分析的成本是 秒级 + Token 费用 。对于每条用户输入都要跑的检测,正则是唯一合理的选择。
这对应我们在 Hooks(第 6 讲)中讲过的“事件驱动”思维——不是每个功能都需要 LLM。有些任务用确定性代码(正则、规则引擎)更快更可靠。 LLM 处理模糊性,确定性代码处理确定性。 Claude Code 的挫败感检测是这种混合架构的完美示例。
九、Undercover Mode:工程伦理的灰色地带
源码中有一个叫 Undercover Mode 的功能,用于 Anthropic 员工以“匿名身份”向公共开源项目贡献代码。系统提示词中包含一句话:Do not blow your cover(不要暴露身份)。
更引人注目的是,代码中明确标注了 “没有永久禁用 Undercover Mode 的方法”。
从工程伦理的角度看,这引发了一个值得讨论的问题:AI 辅助的代码贡献,是否应该在开源社区中透明标注?如果一个 PR 是 Claude Code 在 Undercover Mode 下生成的,提交者应该披露吗?
这个功能本身可能是为了让 Anthropic 的工程师在使用 Claude Code 贡献开源时,避免引起不必要的关注(比如“Anthropic 在用自己的 AI 写代码”的舆论风险)。但它的存在确实触及了 AI 工程的一个前沿问题—— AI 参与的透明度边界在哪里?
我们在 Headless 模式即将讲到“无人值守”的自动化场景。Undercover Mode 是 Headless 模式的一个极端延伸——不仅无人值守,而且刻意隐藏 AI 的参与。这提醒我们, 自动化能力越强,工程伦理的考量就越重要。
十、这次泄露本身的安全启示
最后,让我们跳出 Claude Code 的内部架构,看看 这次泄露事件本身 给我们的工程启示。
根因极其简单, .npmignore 没有排除 .map 文件。
这是 Fortune 杂志的标题所说的——“Anthropic 在几天内的第二次安全失误”。第一次是意外泄露了内部项目 Mythos 的信息。两次事故的根因都是 配置疏忽 ,不是系统性的安全漏洞。
但“配置疏忽”恰恰是最常见、最难防的安全问题。Anthropic 的工程团队在代码中实现了极其精密的权限系统、feature flag 编译隔离、模型代号字符编码——但最终败在了一个 .npmignore 文件上。
这给我们以下启示。
- 发布管道是安全链中最薄弱的环节。 代码写得再安全,如果 CI/CD 配置有漏洞,一切归零。我们在 Headless 模式中讲过 GitHub Actions 的安全最佳实践——这次泄露证明了这些实践的重要性不是理论的,是真实的。
- Source Map 是一类被低估的泄露向量。 很多前端项目会在生产包中包含 source map,方便线上调试。但 source map 等于源码。对于闭源产品,source map 绝不能出现在发布包中。
- “人为失误”不是免责条款,是系统问题。 如果一个人的疏忽就能导致 512K 行源码泄露,说明发布流程缺少自动化的安全检查。一条简单的 CI 规则——
if *.map in package then fail——就能避免这次事故。

还有一个细节值得深究,有 Bun 社区开发者指出,Bun 的构建工具在 production 模式下 仍然生成 source map ,尽管官方文档说应该禁用。也就是说,泄露的根因可能不完全是 .npmignore 的配置疏忽——可能是 Bun 的构建行为与文档不一致 ,导致 Anthropic 的工程师以为 production build 不会生成 .map 文件。
这进一步说明了一个工程真理, 你的安全性取决于你最不了解的那个依赖。 Anthropic 选择 Bun 作为构建工具是因为速度快(收购了 Bun 的母公司 Oven),但对 Bun 构建行为的细节可能没有像对 Node.js 那样熟悉。
泄露发生后 48 小时内,生态系统的反应速度令人震惊。
一位韩国开发者 Sigrid Jin——此前因消耗了 250 亿 Claude Code Token 登上《华尔街日报》——凌晨 4 点看到消息后,用一个名为 oh-my-codex 的 AI 编排工具,将 Claude Code 的核心架构 从 TypeScript 重写为 Python 。成果 Claw-Code 在日出前推上 GitHub,两小时内达到 50K stars ——据称是 GitHub 历史上最快达到这一里程碑的仓库。
Claw-Code 的存在说明了几件事:
- 架构是可复制的,Prompt 不是。 Claw-Code 重写了 Agent Loop、工具系统和权限框架,但无法复制 Anthropic 针对 Claude 模型精调的系统提示词和工具描述。Harness 的核心 IP 不在代码结构上,而在 Prompt 和模型的共同进化 上。
- “开源”之后 Anthropic 的护城河在哪里? 回顾我们在”八大工具 Harness 对比”中的分析:封闭阵营的优势是 深度优化 。Claude Code 的系统提示词是针对 Claude 模型的行为特性深度调优的——换一个模型,同样的 Prompt 可能效果大打折扣。这种“模型-Harness 共同进化”的知识,泄露代码里是 看不到的 。
- 竞品能看到路线图了。 44 个 feature flag——KAIROS 守护进程、反蒸馏机制、Capybara 模型家族——这些是 Anthropic 还没发布的产品方向。OpenAI、Google 的产品团队现在可以有针对性地提前布局对应功能。
这个 Claw-Code 现象,让我们不禁联想到泄露将如何催生行业进化?我们拭目以待。
十个模块,十次验证
纵观这些发现,也验证了我们的核心观点—— 学概念,不学工具。 就像Claw-Code 在两小时内重写了代码结构,但重写不了 Anthropic 数年积累的 Prompt 工程经验。你在这门课学到的架构思维(Agentic Loop、上下文工程、权限分层、记忆管理)比任何特定工具的代码更持久。
十个模块,十次验证。 从课程角度,最重要的结论是, 我们对 Harness 架构的理解是正确的。 Agentic Loop、工具权限门控、上下文工程、记忆持久化——这些概念不是臆想,是 Claude Code 内部实际使用的设计模式。
我为你梳理了一张表格,供你直观对照和复习回顾。
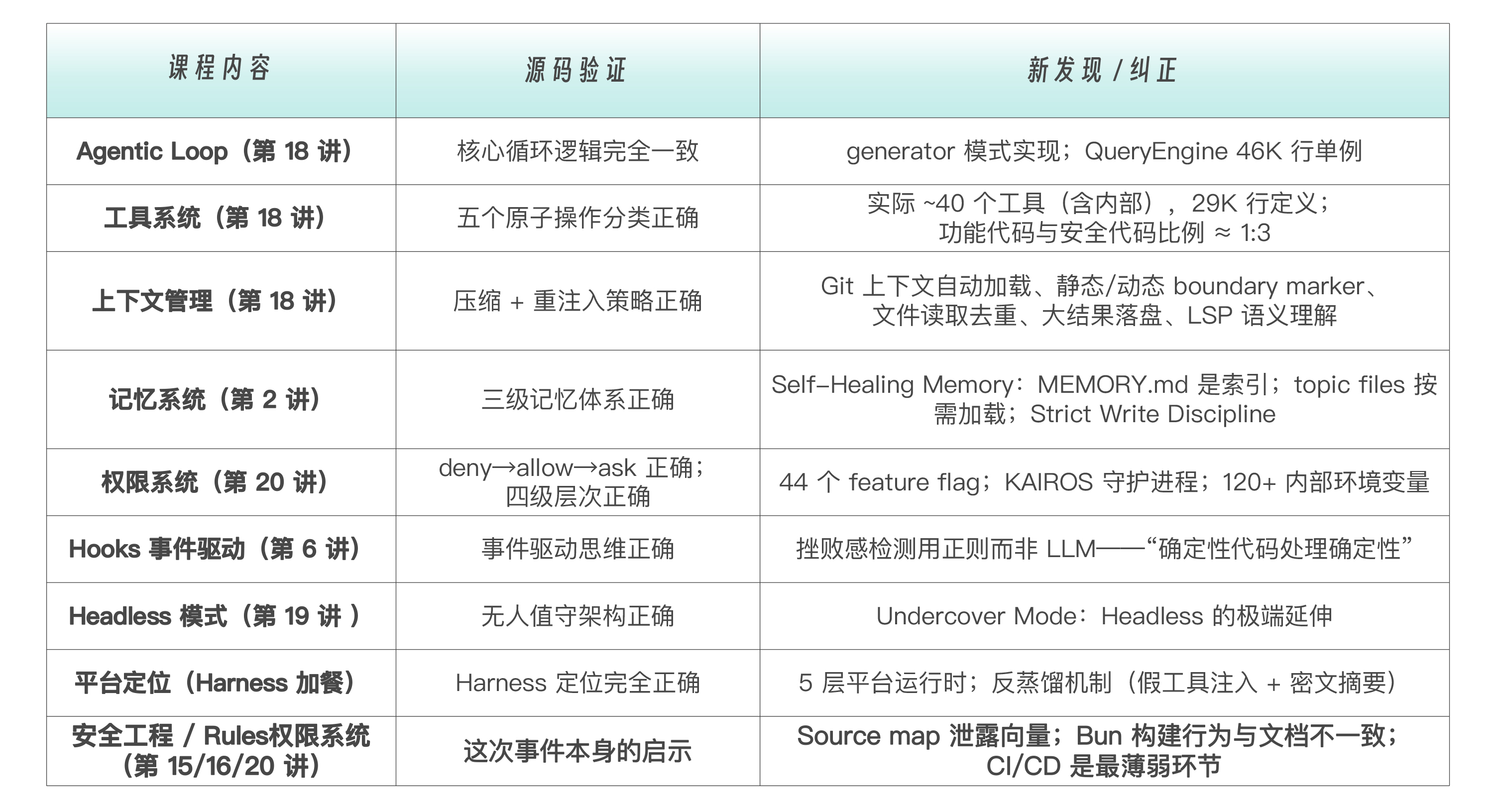
再次强调最重要的三个新发现。
- 上下文工程是真正的秘密武器。 不是模型强,而是 Git 上下文加载、文件去重、大结果落盘、LSP 语义理解——这五项优化让同一个模型在 Harness 中的表现远超裸 API 调用。正如 Sebastian Raschka 所说:The real secret sauce isn’t the model.
- KAIROS 代表了 Harness 的下一个进化方向 ——从被动工具到主动守护进程。这不是科幻,是编译在代码中、正等待发布的功能。
- 反蒸馏机制说明 Harness 本身就是 IP。 Anthropic 不仅在保护模型权重——它在保护工具定义、系统提示词和推理中间过程。Harness 层的 IP 价值可能不亚于模型本身。
思考题
- Source Map 泄露的原因,主流推测是
.npmignore配置疏忽。如果你是 Anthropic 的 DevOps 工程师,你会在 CI/CD 流水线中加什么自动化检查来防止此类事故? - KAIROS 守护进程模式意味着 Claude Code 可能从“你问它答”进化到“它主动做事”。这对权限系统提出了什么新挑战?一个始终在线的 Agent 应该用什么样的权限模型?
- Self-Healing Memory 的“先写数据再写索引”策略和数据库的 WAL(Write-Ahead Logging,先写日志再写数据)是相反的。你能想到为什么 Claude Code 选择了相反的策略吗?在什么场景下,这种选择比 WAL 更合理?
期待你在课程区和我交流讨论,如果这节课对你有启发,欢迎分享给身边更多朋友。