你好,我是黄佳。
在我们的专栏上线初期,就有学员问过我:黄老师,你一直说Claude Code最懂工程,你为什么这么说?这个问题和另外一个群里面经常被问到的问题其实几乎等价,就是 Claude Code 为什么强,究竟强在哪里?

至今为止,我们一直在 Claude Code 里面折腾——写 CLAUDE.md、配 Skills、调 Hooks、连 MCP。但倒是尚未正面思考过一个更根本的问题: Claude Code 本身是什么?
它不是 Claude 模型。模型是 Anthropic 的 API,任何人都可以调用。它也不是一个简单的命令行工具——如果是,为什么同一个 Claude Sonnet 模型,通过 API 直接调用和通过 Claude Code 调用,表现差距那么大?
答案藏在一个词里:Harness。
什么是 Harness?
先看 Anthropic 官方文档里是怎么说的:
Claude Code serves as the **agentic harness** around Claude: it provides the tools, context management, and execution environment that turn a language model into a capable coding agent.翻译一下,Claude Code 是一个 **智能体编排框架** ,包裹在 Claude 模型外面。它提供工具、上下文管理和执行环境,把一个语言模型变成一个有能力的编码 Agent。 注意,这个定义里有三个关键词, **工具** 、 **上下文管理** 、 **执行环境** 。模型本身只会生成文本。是 Harness 给了它读文件的能力、写代码的能力、搜索代码库的能力、在终端执行命令的能力。没有 Harness,Claude 就是一个只会说话的大脑——有智力,没有手脚。  业界对Harness的核心共识是:
**Agent Harness** = 包裹 LLM 的运行时基础设施,管理工具调度、上下文工程、安全执行、状态持久化和会话连续性。LLM 只负责推理决策。 2026 年的关键洞察: **竞争差异化的重心已从 Model 转移到 Harness** 。下面这张图,把 Harness 的内部结构拆得很清楚。 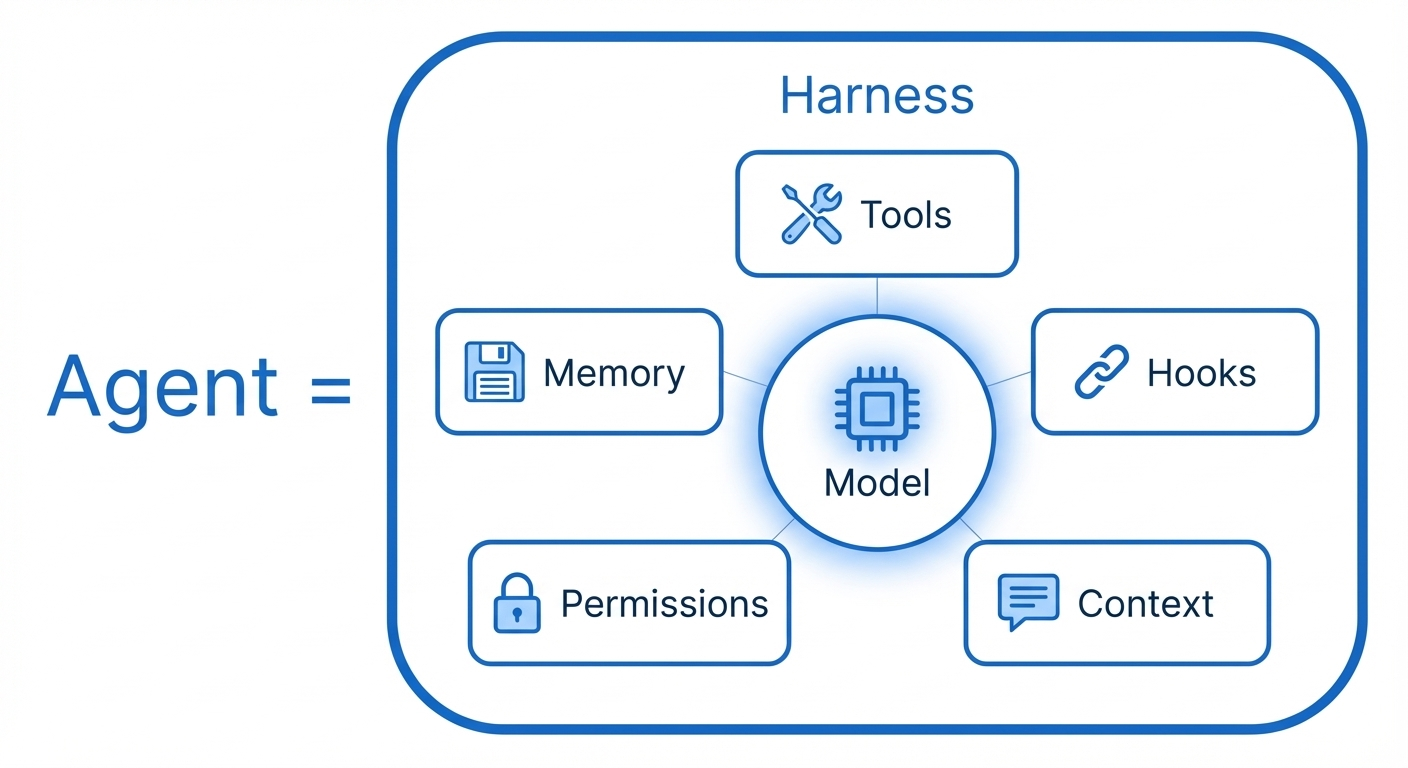
Agent = Model + Harness。 图中最核心的位置是 Model ——那个蓝色芯片图标,代表 Claude 的大语言模型。但模型本身只是一个推理引擎,它不能独立行动。 真正让它变成 Agent 的,是包裹在它周围的五个 Harness 组件。
- Tools(工具) ,模型的手脚。Read、Write、Edit、Bash、Grep……这些工具赋予模型与文件系统、终端、网络交互的能力。没有工具,模型只能说,不能做。
- Context(上下文) ,模型的记忆加载器。CLAUDE.md、系统提示词、对话历史、工具定义——这些上下文在每一轮循环中被注入模型,决定了模型看到什么、知道什么。上下文管理的精妙之处是,它不仅是被动的信息传递,还包括主动的压缩和重注入策略。
- Memory(记忆) ,模型的长期存储。跨会话的记忆持久化,让模型能“记住”你的偏好、项目规则和历史决策。CLAUDE.md 是显式记忆,自动记忆(
~/.claude/memory/)是隐式记忆。没有 Memory,每次对话都从零开始。 - Hooks(钩子) ,模型的神经反射。事件驱动的自动化机制,在工具执行前后触发自定义逻辑。比如每次保存文件前自动格式化,每次提交前自动运行 lint。Hooks 让 Harness 有了“条件反射”的能力——不需要模型主动决策,某些行为会自动发生。
- Permissions(权限) ——模型的安全围栏。哪些工具可以自由使用,哪些需要人工审批,哪些完全禁止——权限系统是 Harness 的安全底线。它解决了一个核心矛盾:你希望 Agent 足够自主以提高效率,但又不希望它自主到失控。
注意图中的空间关系: Model 在中心,五个组件围绕它排列,整体被一个名为 Harness 的边框包裹 。这不是随意的布局,它精确表达了一个架构事实:模型不直接接触外部世界,所有交互都通过 Harness 的组件中转。Harness 是模型和现实之间的 唯一接口 。
这五个组件也不是孤立的。Tools 的执行结果变成 Context 的一部分;Hooks 在 Tools 执行前后触发;Permissions 决定哪些 Tools 可以被调用;Memory 用于跨会话保留 Context 中的关键信息。它们构成了一个协同运转的系统,少了任何一个,Agent 的能力都会大打折扣。
我们再看看 Harness 在整个系统中的层级位置,如下图所示。
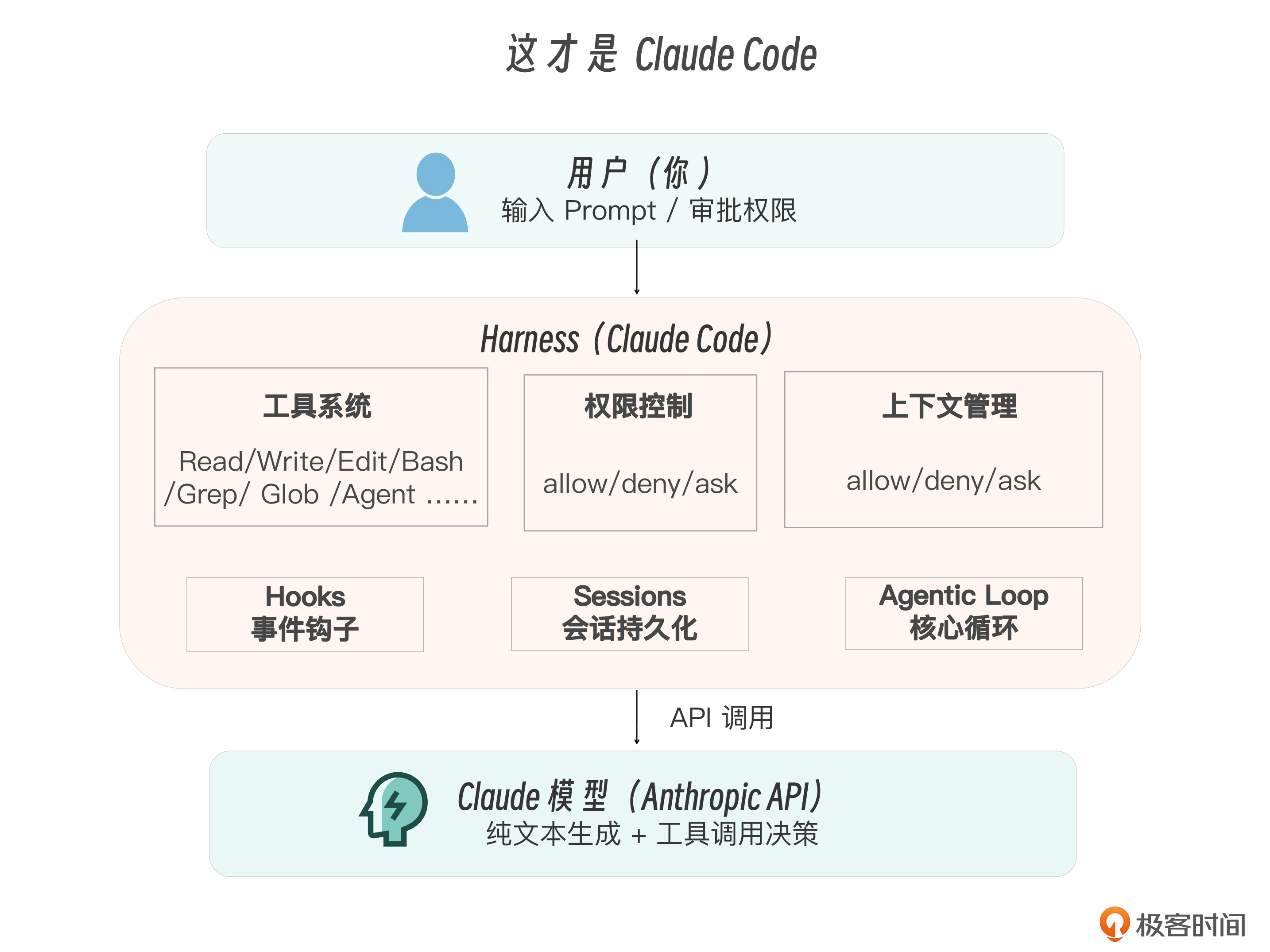
Agentic Loop——Harness 的心脏
如果 Harness 是一台机器,Agentic Loop 就是它的发动机。整个 Claude Code 的运转,归根到底就是一个循环:
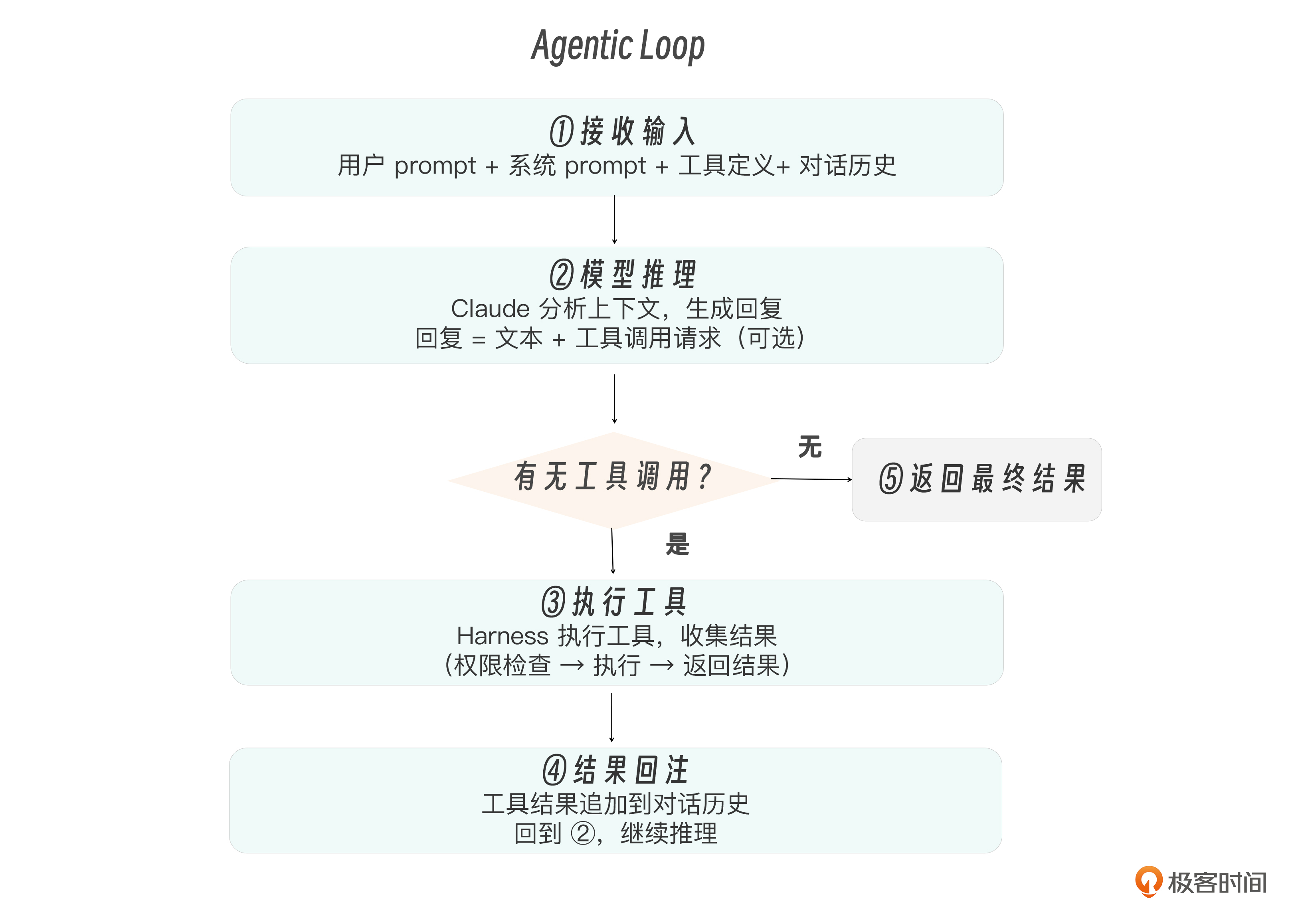
关键点在于 步骤 ② 和步骤 ④ 之间的循环 。模型不是一次性给出最终答案的。它可能先读一个文件,看完结果后决定再搜索一下,搜索完又决定编辑某行代码,编辑完再运行测试——每一步都是一次循环。一个复杂任务可能跑几十轮循环。
循环什么时候结束?满足下面两个条件之一即可:
- 模型主动停止 ——Claude 认为任务完成,生成纯文本回复,不再请求工具调用。API 返回
stop_reason: "end_turn"。 - 达到最大轮次 ——Harness 设置了
--max-turns限制,防止无限循环。

内置工具——Harness 的手脚
Agentic Loop 是引擎,工具是车轮。Claude Code 内置了 20+ 个左右的工具,覆盖了软件工程的五个原子操作。
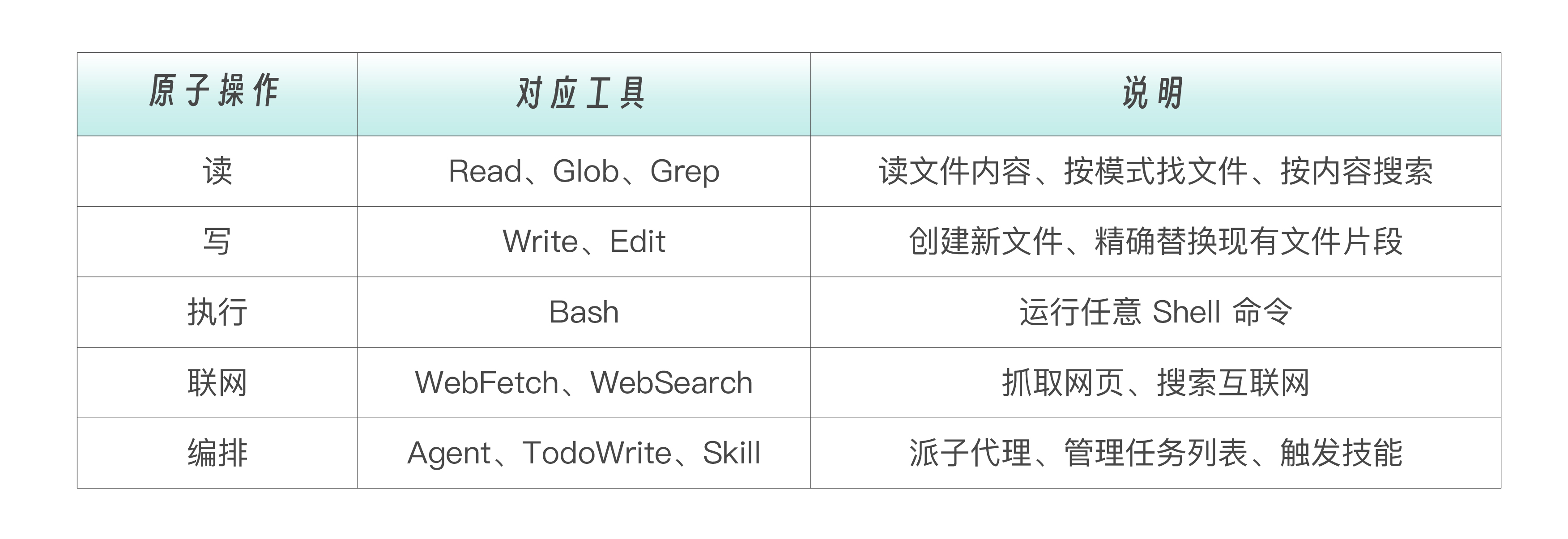
工具设计背后有一个深刻的哲学, 少而精 。Claude Code 没有内置重构工具、测试工具、部署工具……它只给了最基础的原语。重构是 Read + Edit + Bash 的组合涌现;测试是 Bash + Read 的组合涌现;部署还是 Bash。
这就像计算机只需要几条指令就能图灵完备一样。Harness 不需要为每种场景造一个工具,它只需要确保 基础工具的组合空间足够大 。
但 Bash 是个例外。Bash 工具是一个 图灵完备的逃逸舱 。通过它,Claude 可以执行任何 Shell 命令:安装依赖、运行测试、调用 API、操作数据库。这意味着 Claude Code 的能力上限,理论上等于操作系统的能力上限。
这也是为什么 Harness 需要 权限控制 的原因。
上下文管理——被忽视的关键能力
大多数人讨论 Agent 框架时,只关心工具和循环。但 Harness 最精巧的部分,其实是 上下文管理 。
Claude 的上下文窗口是有限的(200K tokens)。一个真实的编码任务——读 20 个文件、搜索 50 次、执行 30 条命令——产生的对话历史会迅速膨胀到几十万 tokens。如果不管理,要么爆掉上下文窗口,要么模型开始“遗忘”早期信息。
Claude Code 的解决方案是 自动压缩 。当对话历史接近上下文窗口的 92% 时,Harness 会触发一次压缩操作:
对话历史(180K tokens)
│
▼ 压缩触发
┌────────────────────────────┐
│ 保留:最近的消息(完整) │
│ 压缩:早期消息 → 摘要 │
│ 重注入:CLAUDE.md 内容 │
│ 重注入:系统提示词 │
│ 重注入:工具定义 │
└────────────────────────────┘
│
▼
压缩后对话历史(~80K tokens)
│
▼ 继续工作
注意最后三行, CLAUDE.md、系统提示词、工具定义在每次压缩后都会重新注入 。这意味着即使对话历史被截断了,模型仍然知道项目的规则、自己有哪些工具、应该遵循什么约定。
这就是为什么你在 CLAUDE.md 里写的东西那么“持久”——不是因为模型记住了它,而是 Harness 在每次压缩后都重新塞给模型。

开源还是闭源?一个被误解的事实
很多人以为 Claude Code 是开源的。毕竟它在 GitHub 上有一个仓库(github.com/anthropics/claude-code),截至 2026 年 3 月已有 81K+ stars。
但打开仓库的 LICENSE 文件,你会看到:
© Anthropic PBC. All rights reserved. Use is subject to Anthropic’s Commercial Terms of Service.其实 **Claude Code 不是开源软件。** 它是专有软件。 GitHub 仓库里有什么?安装脚本、插件模板、GitHub Action、文档、示例配置。核心的 Agentic Loop、工具执行引擎、上下文管理器——这些 Harness 的核心代码——以编译后的 npm 包(`@anthropic-ai/claude-code`)分发,源码并不可见。 2026 年 1 月,GitHub 上出现了一个 issue(#22002),请求 Anthropic 将 Claude Code CLI 以 Apache 2.0 或 MIT 许可证开源。截至目前,这个 issue 仍然是“Open”状态。
Claude Agent SDK——可编程的 Harness
虽然 Claude Code CLI 本身不开源,但 Anthropic 在 2025 年发布了 Claude Agent SDK ——一套可编程的 Harness 接口。
# TypeScript 版本
npm install @anthropic-ai/claude-agent-sdk
# Python 版本
pip install claude-agent-sdk
Agent SDK 提供了与 Claude Code 完全相同的 Agentic Loop、内置工具、上下文管理、权限系统、Hooks、Sub-Agent 支持和 MCP 集成。区别在于,Claude Code 是面向终端用户的交互式产品,Agent SDK 是面向开发者的编程库。
用 Agent SDK,你可以构建自己的 Harness——一个定制化的 Agent 应用,嵌入到你自己的产品、工作流或 CI/CD 系统中。
from claude_agent_sdk import AgentClient
client = AgentClient(api_key="...")
# 创建一个有工具能力的 Agent
result = client.run(
prompt="审查这个 PR 的安全问题",
tools=["Read", "Grep", "Glob", "Bash"],
max_turns=20,
allowed_tools={"Bash": ["npm test", "npm run lint"]}
)
print(result.text)
如果说 Claude Code 是一辆出厂配置的整车,Agent SDK 就是发动机总成——你可以把它装进任何车身里。

第三方 Harness 的崛起与冲突
Claude Code 的成功证明了一件事: 模型 + Harness = 10× 生产力 。这个公式吸引了大量第三方工具来构建自己的 Harness。
OpenCode (前身 SST)是最成功的第三方 Harness。它用 Client-Server 架构解决了 Claude Code 的“单表面”局限——TUI、桌面 App、IDE 插件、Slack 机器人共享同一个后端。截至 2026 年 3 月,OpenCode 拿到了 119K GitHub stars,月活 65 万+,超过了 Claude Code 本身的 star 数。
但 2026 年 1 月,Anthropic 采取了一个争议性举措: 封堵了第三方工具通过消费者 OAuth Token 调用 Claude API 的通道 。这直接影响了 OpenCode、Cursor、Windsurf 等工具的用户——他们之前可以用 Claude Pro 订阅的 Token 在这些第三方工具里使用 Claude,封堵后必须购买独立的 API Key。
这件事引发了开发者社区的强烈反弹,但也揭示了 Harness 生态的核心张力: 模型提供商希望控制 Harness 层,因为 Harness 决定了 API 调用量和用户体验;第三方 Harness 希望模型层是可替换的商品,因为这样它们才能建立独立的价值。
我为你梳理一下当前的 Harness 生态格局(截止到2026年3月31日)。
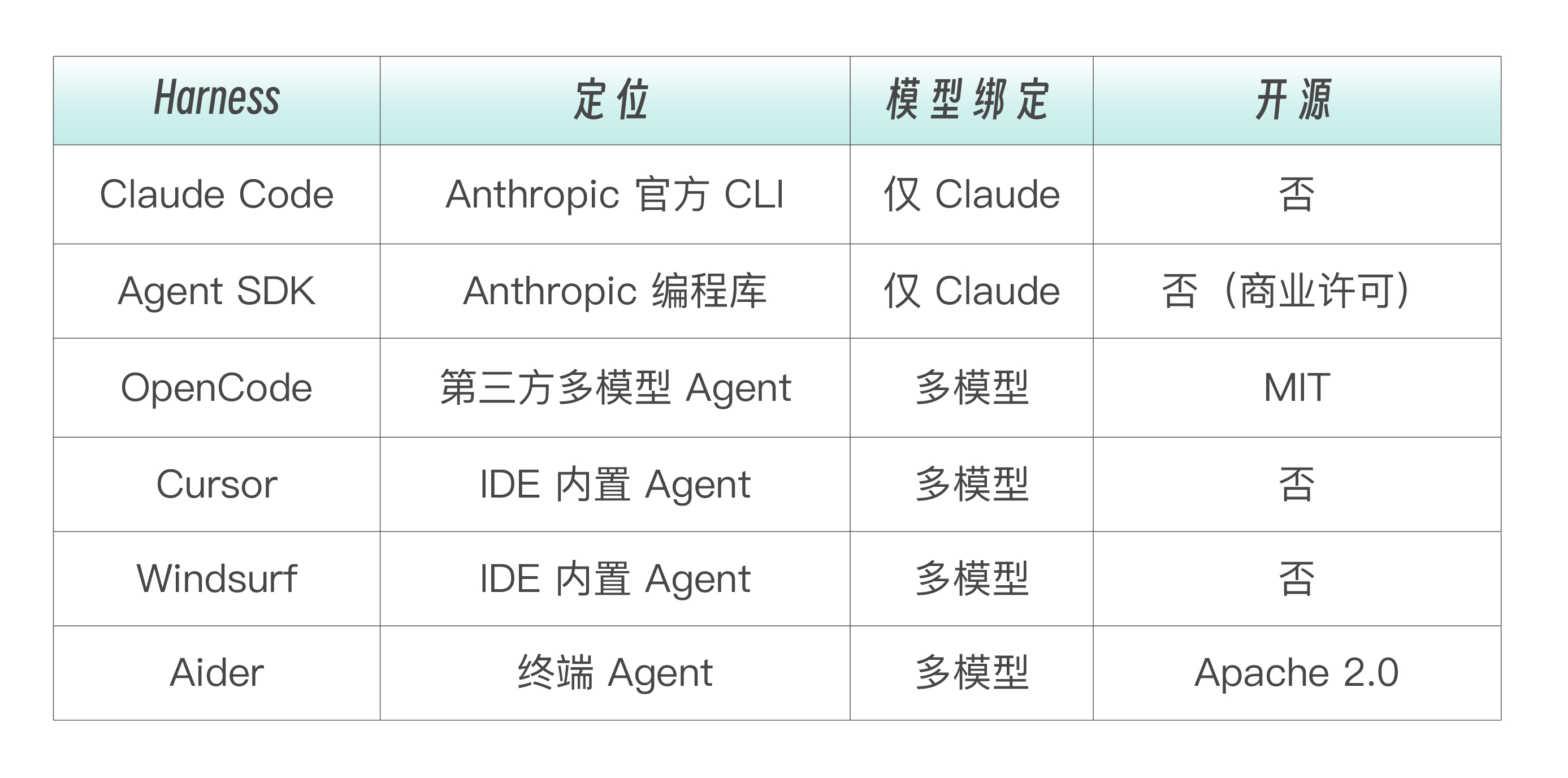
为什么 2026 年是 Harness 之年?
2025 年的关键词是 Agent。2026 年的关键词是 Agent Harness 。
为什么?因为行业已经意识到。模型本身正在商品化——Claude、GPT、Gemini、DeepSeek 的能力差距在缩小。但 同一个模型在不同 Harness 中的表现差距,远大于不同模型在同一个 Harness 中的差距 。
换句话说,Harness 比模型更重要。
这不是我的臆断。有几个数据点足以佐证:
- Claude Code 在 2025 年 11 月达到 10 亿美元年化收入 ——这是一个 Harness 产品的收入,不是模型本身的收入。
- Anthropic 在 2026 年 3 月收购了 Bun (JavaScript 运行时),明确表示要加强 Claude Code 的基础设施。收购一个运行时来加强一个 Harness——这说明 Anthropic 把 Harness 视为战略级资产。
- 开源社区出现了“Agent Harness“作为独立品类。GitHub 上以 “harness” 为关键词的新仓库数量在 2026 年 Q1 翻了三倍。
对于我们开发者来说,这意味着什么?
理解 Harness 比理解模型更重要。
模型的能力由 Anthropic/OpenAI 决定,你无法改变。但 Harness 的配置——CLAUDE.md 怎么写、工具权限怎么设、Hooks 怎么接、MCP 怎么连——这些全在你手中。你前面学的每一讲,本质上都是在 调教 Harness 。
动手验证:感受 Harness 的存在
最后来一个非常简单的实验,只是感受 Harness 的作用(其实我们每天都在感受着这种不同)。
用裸 API 和 Claude Code 分别执行同一个任务:
# 方式一:裸 API 调用(没有 Harness)- 你可以换成Deepseek或GPT等任何模型
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "content-type: application/json" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6-20260320",
"max_tokens": 1024,
"messages": [{"role":"user","content":"找出当前目录下所有 TODO 注释并列出文件名和行号"}]
}'
# 方式二:通过 Harness(Claude Code)
claude -p "找出当前目录下所有 TODO 注释并列出文件名和行号" --output-format text
裸 API 会怎么回答?它会告诉你“你可以用 grep 命令来搜索”——因为它没有手脚,只能 说 。
Claude Code 会怎么做?它会直接执行 Grep 工具搜索 TODO,然后返回完整的文件名、行号和上下文——因为 Harness 给了它 行动 的能力。
同一个大脑,有没有 Harness,结果天壤之别。
总结一下
这一讲我们从底层理解了 Claude Code 的真实身份——它是一个 Harness ,一个包裹在 Claude 模型外面的智能体编排框架。
我们再回顾一下核心要点。
- Harness = 工具 + 上下文管理 + 执行环境 + 权限控制 。它把模型的智力转化为行动力。
- Agentic Loop 是 Harness 的心脏 。“推理 → 工具调用 → 结果回注 → 继续推理”的循环是所有复杂行为的涌现基础。
- 20+个内置工具覆盖 5 个原子操作 (读、写、执行、联网、编排)。少而精的设计让组合空间最大化。
- 上下文管理是被低估的关键能力 。自动压缩 + CLAUDE.md 重注入,确保模型在长任务中不丢失关键信息。
- Claude Code 不是开源软件 。核心 Harness 代码以编译后的 npm 包分发。Agent SDK 提供了可编程的 Harness 接口。
- 2026 年是 Harness 之年 。同一模型在不同 Harness 中的表现差距,大于不同模型在同一 Harness 中的差距。因此理解 Harness 比理解模型更重要。
思考题
1.如果你要为自己的团队构建一个定制化的 Harness(比如专门用于数据分析),你会保留 Claude Code 的哪些内置工具,去掉哪些,新增哪些?为什么? 2.Claude Code 的上下文压缩策略“摘要早期消息 + 重注入 CLAUDE.md”。你能想到这种策略的局限性吗?在什么场景下会出问题? 3.从商业角度看,Anthropic 选择“开放 Agent SDK、封闭 Claude Code CLI” 的策略是否合理?如果你是 Anthropic 的竞争对手,你会怎么应对?
参考资料
我好多次和大伙儿强调一手资料的重要性,加餐梳理之外,我也想把 Harness 主题下,我认为非常有价值的参考资料分享给你。
Tier 1:AI 实验室一手资料
Anthropic
- Effective Harnesses for Long-Running Agents:官方定义 harness 架构,Initializer + Coding Agent 两阶段设计。
- Building Effective Agents:2024.12 发表的行业奠基性文章,Workflow vs Agent 区分,Harness 概念前身。
- Building Agents with the Claude Agent SDK:Agent SDK 官方文档,暴露 Claude Code 内部的 Agent Loop。
OpenAI
- Harness Engineering:2026.2,正式提出 “harness engineering” 概念,~1500 自动化 PR。
- Unrolling the Codex Agent Loop:Codex CLI agent loop 详解。
- Unlocking the Codex Harness:Codex harness 的 App Server 层实现。
Tier 2: 学术论文
Building Effective AI Coding Agents(arXiv 2603.05344),这篇论文是学术界对 Harness 概念的首次严肃形式化——scaffolding vs harness 的边界定义是本文最大贡献。文中以“首次 prompt”为分界线。之前是 scaffolding(搭脚手架),之后是 harness(操控)。佳哥个人认为这个定义简洁有力,应该成为行业标准。
Tier 3: 行业内高影响力文章
- Simon Willison,How Coding Agents Work,提出 “Coding agent = harness for LLM” 的经典定义。
- Inngest,Your Agent Needs a Harness, Not a Framework,重点看 Harness vs Framework 的区分。
- Swyx / Latent Space,Is Harness Engineering Real?,行业讨论,核心观点是“竞争优势在 Harness 而非Model”。
- LangChain,Deep Agents (GitHub),开源 Harness 实现,仅调 Harness 就让Terminal Bench 提升 13.7 分。
- Lilian Weng,LLM Powered Autonomous Agents,2023年的奠基综述,虽未用 “harness”一词但定义了同一架构。
- Parallel.ai,What is an Agent Harness,最佳独立解释文,定义 Harness 6 大组件,区分 Harness/Framework/Orchestrator。
欢迎你在留言区参与讨论,也推荐你把今天的内容,分享给身边关注 Harness 的朋友。